






















































Log file monitoring
Log files can be a valuable source of information. Zabbix provides a way to monitor log files using the Zabbix agent. For that, two special keys are provided:
log: Allows us to monitor a single filelogrt: Allows us to monitor multiple, rotated files
Both of the log monitoring item keys only work as active items. To see how this functions, let's try out the Zabbix log file monitoring by actually monitoring some files.
Monitoring a single file
Let's start with the simpler case, monitoring a single file. To do so, we could create a couple of test files. To keep things a bit organized, let's create a directory /tmp/zabbix_logmon/ on A test host and create two files in there, logfile1 and logfile2. For both files, use the same content as this:
2016-08-13 13:01:03 a log entry 2016-08-13 13:02:04 second log entry 2016-08-13 13:03:05 third log entry
Note
Active items must be properly configured for log monitoring to work—we did that in Chapter 3, Monitoring with Zabbix Agents and Basic Protocols.
With the files in place, let's proceed to creating items. Navigate to Configuration | Hosts, click on Items next to A test host, then click on Create item. Fill in the following:
Name:
First logfileType: Zabbix agent (active)
Key:
log[/tmp/zabbix_logmon/logfile1]Type of information: Log
Update interval:
1
When done, click on the Add button at the bottom. As mentioned earlier, log monitoring only works as an active item, so we used that item type. For the key, the first parameter is required—it's the full path to the file we want to monitor. We also used a special type of information here, Log. But what about the update interval, why did we use such a small interval of 1 second? For log items, this interval is not about making an actual connection between the agent and the server, it's only about the agent checking whether the file has changed—it does a stat() call, similar to what tail -f does on some platforms/filesystems. Connection to the server is only made when the agent has anything to send in.
Note
With active items, log monitoring is both quick to react, as it is checking the file locally, and also avoids excessive connections. It could be implemented as a somewhat less efficient passive item, but that's not supported yet as of Zabbix 3.0.0.
With the item in place, it should not take longer than 3 minutes for the data to arrive—if everything works as expected, of course. Up to 1 minute could be required for the server to update the configuration cache, and up to 2 minutes could be required for the active agent to update its list of items. Let's verify this—navigate to Monitoring | Latest data and filter by host A test host. Our First logfile item should be there, and it should have some value as well:

Note
Even short values are excessively trimmed here. It is hoped that this will be improved in further releases.
If the item is unsupported and the configuration section complains about permissions, make sure permissions actually allow the Zabbix user to access that file. If the permissions on the file itself look correct, check the execute permission on all the upstream directories, too. Here and later, keep in mind that unsupported items will take up to 10 minutes to update after the issue has been resolved.
As with other non-numeric items, Zabbix knows that it cannot graph logs, thus there's a History link on the right-hand side—let's click on it:
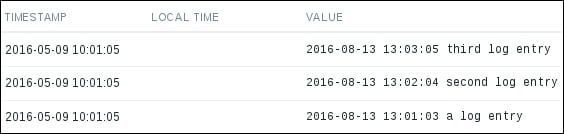
Note
If you see no values in the History mode, it might be caused by a bug in the Zabbix time scroll bar. Try selecting the 500 latest values in the dropdown in the upper-right corner.
All the lines from our log file are here. By default, Zabbix log monitoring parses whole files from the very beginning. That is good in this case, but what if we wanted to start monitoring some huge existing log file? Not only would that parsing be wasteful, we would also likely send lots of useless old information to the Zabbix server. Luckily, there's a way to tell Zabbix to only parse new data since the monitoring of that log file started. We could try that out with our second file, and to keep things simple, we could also clone our first item. Let's return to Configuration | Hosts, click on Items next to A test host, then click on First logfile in the NAME column. At the bottom of the item configuration form, click on Clone and make the following changes:
Name:
Second logfileKey:
log[/tmp/zabbix_logmon/logfile2,,,,skip]
Note
There are four commas in the item key—this way we are skipping some parameters and only specifying the first and fifth parameters.
When done, click on the Add button at the bottom. Same as before, it might take up to 3 minutes for this item to start working. Even when it starts working, there will be nothing to see in the latest data page—we specified the skip parameter and thus only any new lines would be considered.
Note
Allow at least 3 minutes to pass after adding the item before executing the following command below. Otherwise, the agent won't have the new item definition yet.
To test this, we could add some lines to Second logfile. On "A test host", execute:
$ echo "2016-08-13 13:04:05 fourth log entry" >> /tmp/zabbix_logmon/logfile2
Note
This and further fake log entries increase the timestamp in the line itself—this is not required, but looks a bit better. For now, Zabbix would ignore that timestamp anyway.
A moment later, this entry should appear in the latest data page:

If we check the item history, it is the only entry, as Zabbix only cares about new lines now.
Note
The skip parameter only affects behavior when a new log file is monitored. While monitoring a log file with and without that parameter, the Zabbix agent does not re-read the file, it only reads the added data.
Filtering for specific strings
Sending everything is acceptable with smaller files, but what if a file has lots of information and we are only interested in error messages? The Zabbix agent may also locally filter the lines and only send to the server the ones we instruct it to. For example, we could grab only lines that contain the string error in them. Modify the Second logfile item and change its key to:
log[/tmp/zabbix_logmon/logfile2,error,,,skip]
That is, add an error after the path to the log file. Note that now there are three commas between error and skip—we populated the second item key parameter. Click on Update. Same as before, it may take up to 3 minutes for this change to propagate to the Zabbix agent, so it is suggested to let some time pass before continuing. After making a tea, execute the following on "A test host":
$ echo "2016-08-13 13:05:05 fifth log entry" >> /tmp/zabbix_logmon/logfile2
This time, nothing new would appear in the Latest data page—we filtered for the error string, but this line had no such string in it. Let's add another line:
$ echo "2016-08-13 13:06:05 sixth log entry – now with an error" >> /tmp/zabbix_logmon/logfile2
Checking the history for the logfile2 logfile item, we should only see the latest entry.
How about some more complicated conditions? Let's say we would like to filter for all error and warning string occurrences, but for warnings only if they are followed by a numeric code that starts with numbers 60-66. Luckily, the filter parameter is actually a regular expression—let's modify the second log monitoring item and change its key to:
log[/tmp/zabbix_logmon/logfile2,"error|warning 6[0-6]",,,skip]
We changed the second key parameter to "error|warning 6[0-6]", including the double quotes. This regular expression should match all errors and warnings that start with numbers 60-66. We had to double quote it, because the regexp contained square brackets, which are also used to enclose key parameters. To test this out, let's insert in our log file several test lines:
$ echo "2016-08-13 13:07:05 seventh log entry – all good" >> /tmp/zabbix_logmon/logfile2 $ echo "2016-08-13 13:08:05 eighth log entry – just an error" >> /tmp/zabbix_logmon/logfile2 $ echo "2016-08-13 13:09:05 ninth log entry – some warning" >> /tmp/zabbix_logmon/logfile2 $ echo "2016-08-13 13:10:05 tenth log entry – warning 13" >> /tmp/zabbix_logmon/logfile2 $ echo "2016-08-13 13:11:05 eleventh log entry – warning 613" >> /tmp/zabbix_logmon/logfile2
Based on our regular expression, the log monitoring item should:
Ignore the seventh entry, as it contains no error or warning at all
Catch the eighth entry, as it contains an error
Ignore the ninth entry—it has a warning, but no number following it
Ignore the tenth entry—it has a warning, but the number following it does not start within range of
60-66Catch the eleventh entry—it has a warning, the number starts with
61, and that is in our required range,60-66
Eventually, only the eighth and eleventh entries should be collected. Verify that in the latest data page only the entries that matched our regexp should have been collected.
The regexp we used was not very complicated. What if we would like to exclude multiple strings or do some other, more complicated filtering? With the POSIX EXTENDED regular expressions that could be somewhere between very complicated and impossible. There is a feature in Zabbix, called global regular expressions, which allows us to define regexps in an easier way. If we had a global regexp named Filter logs, we could reuse it in our item like this:
log[/tmp/zabbix_logmon/logfile2,@Filter logs,,,skip]
Global regular expressions are covered in more detail in Chapter 12, Automating Configuration.
Monitoring rotated files
Monitoring a single file was not terribly hard, but there's a lot of software that uses multiple log files. For example, the Apache HTTP server is often configured to log to a new file every day, with the date included in the filename. Zabbix supports monitoring such a log rotation scheme with a separate item key, logrt. To try it out, navigate to Configuration | Hosts, click on Items next to A test host, then click on Create item. Fill in the following:
Name:
Rotated logfilesType: Zabbix agent (active)
Key:
logrt["/tmp/zabbix_logmon/access_[0-9]{4}-[0-9]{2}-[0-9]{2}.log"]Type of information: Log
Update interval:
2
When done, click on the Add button at the bottom. But the key and its first parameter changed a bit from what we used before. The key now is logrt, and the first parameter is a regular expression, describing the files that should be matched. Note that the regular expression here is supported for the file part only, the path part must describe a specific directory. We also double quoted it because of the square brackets that were used in the regexp. The regexp should match filenames that start with access_, followed by four digits, a dash, two digits, a dash, two more digits, and ending with .log. For example, a filename such as access_2015-12-31.log would be matched. One thing we did slightly differently—the update interval was set to 2 seconds instead of 1. The reason is that the logrt key is periodically re-reading directory contents, and this could be a bit more resource intensive than just checking a single file. That is also the reason why it's a separate item key, otherwise we could have used the regular expression for the file in the log item.
Note
The Zabbix agent does not re-read directory contents every 2 seconds if a monitored file still has lines to parse—it only looks at the directory again when the already known files have been fully parsed.
With the item in place, let's proceed by creating and populating some files that should be matched by our regexp. On "A test host", execute:
$ echo "2016-08-30 03:00:00 rotated first" > /tmp/zabbix_logmon/access_2015-12-30.log
Checking the latest data page, the rotated log files item should get this value. Let's say that's it for this day and we will now log something the next day:
$ echo "2015-12-31 03:00:00 rotated second" > /tmp/zabbix_logmon/access_2015-12-31.log
Checking the history for our item, it should have successfully picked up the new file:

As more files with a different date appear, Zabbix will finish the current file and then start on the next one.
Alerting on log data
With the data coming in, let's talk about alerting on it with triggers. There are a few things somewhat different than the thresholds and similar numeric comparisons that we have used in triggers so far.
If we have a log item which is collecting all lines and we want to alert on the lines containing some specific string, there are several trigger functions of potential use:
str(): Checks for a substring; for example, if we are collecting all values, this function could be used to alert on errors:str(error)regexp: Similar to thestr()function, allows us to specify a regular expression to matchiregexp: Case-insensitive version ofregexp()
Note
These functions only work on a single line; it is not possible to match multiline log entries.
For these three functions, a second parameter is supported as well—in that case, it's either the number of seconds or the number of values to check. For example, str(error,600) would fire if there's an error substring in any of the values over last 10 minutes.
That seems fine, but there's an issue if we only send error lines to the server by filtering on the agent side. To see what the problem is, let's consider a "normal" trigger, like the one checking for CPU load exceeding some threshold. Assuming we have a threshold of 5, the trigger currently in the OK state and values such as 0, 1, 2 arriving, nothing happens, no events are generated. When the first value above 5 arrives, a PROBLEM event is generated and the trigger switches to the PROBLEM state. All other values above 5 would not generate any events, nothing would happen.
And the problem would be that it would work this way for log monitoring as well. We would generate a PROBLEM event for the first error line, and then nothing. The trigger would stay in the PROBLEM state and nothing else would happen. The solution is somewhat simple—there's a checkbox in the trigger properties, Multiple PROBLEM events generation:

Marking this checkbox would make the mentioned CPU load trigger generate a new PROBLEM event for every value above the threshold of 5. Well, that would not be very useful in most cases, but it would be useful for the log monitoring trigger. It's all good if we only receive error lines; a new PROBLEM event would be generated for each of them.
Note that even if we send both errors and good lines, errors after good lines would be picked up, but subsequent errors would be ignored, which could be a problem as well.
With this problem solved, we arrive at another one—once a trigger fires against an item that only receives error lines, this trigger never resolves—it always stays in the PROBLEM state. While that's not an issue in some cases, in others it is not desirable. There's an easy way to make such triggers time out by using a trigger function we are already familiar with, nodata(). If the item receives both error and normal lines, and we want it to time out 10 minutes after the last error arrived even if no "normal" lines arrive, the trigger expression could be constructed like this:
{host.item.str(error)}=1 and {host.item.nodata(10m)}=0Here, we are using the nodata() function the other way around—even if the last entry contains errors, the trigger would switch to the OK state if there were no other values in the last 10 minutes.
Note
We also discussed triggers that time out in Chapter 6, Detecting Problems with Triggers, in the Triggers that time out section.
If the item receives error lines only, we could use an expression like the one above, but we could also simplify it. In this case, just having any value is a problem situation, so we would use the reversed nodata() function again and alert on values being present:
{host.item.nodata(10m)}=0Here, if we have any values in the last 10 minutes, that's it—it's a PROBLEM. No values, the trigger switches to OK. This is somewhat less resource intensive as Zabbix doesn't have to evaluate the actual item value.
Yet another trigger function that we could use here is count(). It would allow us to fire an alert when there's a certain number of interesting strings—such as errors—during some period of time. For example, the following will alert if there are more than 10 errors in the last 10 minutes:
{host.item.count(10m,error,like)}>10Extracting part of the line
Sometimes we only want to know that an error was logged. In those cases, grabbing the whole line is good enough. But sometimes the log line might contain an interesting substring, maybe a number of messages in some queue. A log line might look like this:
2015-12-20 18:15:22 Number of messages in the queue: 445
Theoretically, we could write triggers against the whole line. For example, the following regexp should match when there are 10,000 or more messages:
messages in the queue: [1-9][0-9]{4}But what if we want to have a different trigger when the message count exceeds 15,000? That trigger would have a regexp like this:
messages in the queue: (1[5-9]|[2-9].)[0-9]{3}And if we want to exclude values above 15,000 from our first regexp, it would become the following:
messages in the queue: 1[0-4][0-9]{3}That is definitely not easy to maintain. And that's with just two thresholds. But there's an easier way to do this, if all we need is that number. Zabbix log monitoring allows us to extract values by regular expressions. To try this out, let's create a file with some values to extract. Still on "A test host", create the file /tmp/zabbix_logmon/queue_log with the following content:
2016-12-21 18:01:13 Number of messages in the queue: 445 2016-12-21 18:02:14 Number of messages in the queue: 5445 2016-12-21 18:03:15 Number of messages in the queue: 15445
Now on to the item—go to Configuration | Hosts, click on Items next to A test host, then click on Create item. Fill in the following:
Name:
Extracting log contentsType: Zabbix agent (active)
Key:
log[/tmp/zabbix_logmon/queue_log,"messages in the queue: ([0-9]+)",,,,\1]Type of information: Log
Update interval:
1
We quoted the regexp because it contained square brackets again. The regexp itself extracts the text "messages in the queue", followed by a colon, space, and a number. The number is included in a capture group—this becomes important in the last parameter to the key we added, \1—that references the capture group contents. This parameter, "output", tells Zabbix not to return the whole line, but only whatever is referenced in that parameter. In this case—the number.
Note
We may also add extra text in the output parameter—for example, a key such as log[/tmp/zabbix_logmon/queue_log, messages in the queue: "([0-9]+)",,,,Extra \1 things] would return "Extra 445 things" for the first line in our log file. Multiple capture groups may be used as well, referenced in the output parameter as \2, \3, and so on.
When done, click on the Add button at the bottom. Some 3 minutes later, we could check the history for this item in the latest data page:
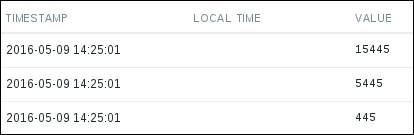
Hooray, extracting the values is working as expected. Writing triggers against them should be much, much easier as well. But one thing to note—for this item we were unable to see the graphs. The reason is the Type of information property in our log item—we had it set to Log, but that type is not considered suitable for graphing. Let's change it now. Go to Configuration | Hosts, click on Items next to A test host, and click on Extracting log contents in the NAME column. Change Type of information to Numeric (unsigned), then click on the Update button at the bottom.
Note
If the extracted numbers have the decimal part, use Numeric (float) for such items.
Check this item in the latest data section—it should have a Graph link now. But checking that reveals that it has no data. How so? Internally, Zabbix stores values for each type of information separately. Changing that does not remove the values, but Zabbix only checks the currently configured type. Make sure to set the correct type of information from the start. To verify that this works as expected, run the following on "A test host":
$ echo "2016-12-21 18:16:13 Number of messages in the queue: 113" >> /tmp/zabbix_logmon/queue_log $ echo "2016-12-21 18:17:14 Number of messages in the queue: 213" >> /tmp/zabbix_logmon/queue_log $ echo "2016-12-21 18:18:15 Number of messages in the queue: 150" >> /tmp/zabbix_logmon/queue_log
Checking out this item in the Latest data section, the values should be there and the graph should be available, too. Note that the date and time in our log file entries still doesn't matter—the values will get the current timestamp assigned.
Note
Value extracting works the same with the logrt item key.
Parsing timestamps
Talking about the timestamps on the lines we pushed in Zabbix, the date and time in the file did not match the date and time displayed in Zabbix. Zabbix marked the entries with the time it collected them. This is fine in most cases when we are doing constant monitoring—content is checked every second or so, gathered, timestamped and pushed to the server. When parsing some older data, the timestamps can be way off, though. Zabbix does offer a way to parse timestamps out of the log entries. Let's use our very first log file monitoring item for this. Navigate to Configuration | Hosts, click on Items next to A test host, and click on First logfile in the NAME column. Notice the Log time format field—that's what we will use now. It allows us to use special characters to extract the date and time. The supported characters are:
y: YearM: Monthd: Dayh: Hourm: Minutes: Second
In our test log files, we used the time format like this:
2015-12-13 13:01:03
The time format string to parse out date and time would look like this:
yyyy-MM-dd hh:mm:ss
Note that only the supported characters matter—the other ones are just ignored and can be anything. For example, the following would work exactly the same:
yyyyPMMPddPhhPmmPss
You can choose any characters outside of the special ones. Which ones would be best? Well, it's probably best to aim for readability. Enter one of the examples here in the Log time format field:

Note
When specifying the log time format, all date and time components must be present—for example, it is not possible to extract the time if seconds are missing.
When done, click on the Update button at the bottom. Allow for a few minutes to pass, then proceed with adding entries to the monitored file. Choose the date and time during the last hour for your current time, and run on "A test host":
$ echo "2016-05-09 15:30:13 a timestamped log entry" >> /tmp/zabbix_logmon/logfile1
Now check the history for the First logfile item in the latest data page:

There's one difference from the previous cases. The LOCAL TIME column is populated now, and it contains the time we specified in our log line. The TIMESTAMP column still holds the time when Zabbix collected the line.
Note that only numeric data is supported for date and time extraction. The standard syslog format uses short textual month names such as Jan, Feb, and so on—such a date/time format is not supported for extraction at this time.
Viewing log data
With all the log monitoring items collecting data, let's take a quick look at the displaying options. Navigate to Monitoring | Latest data and click on History for Second logfile. Expand the Filter. There are a few very simple log viewing options here:
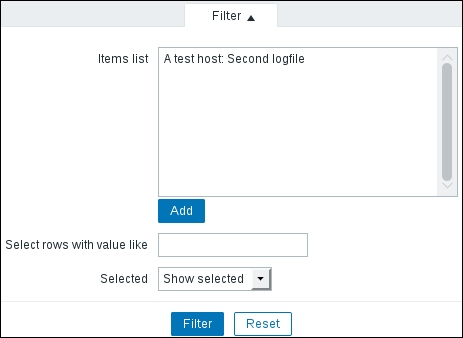
Items list: We may add multiple items and view log entries from them all at the same time. The entries will be sorted by their timestamp, allowing us to determine the sequence of events from different log files or even different systems.
Select rows with value like and Selected: Based on a substring, entries can be shown, hidden, or colored.
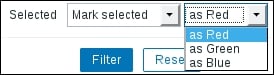
As a quick test, enter "error" in the Select rows with value like field and click on Filter. Only the entries that contain this string will remain. In the Selected dropdown, choose Hide selected—and now only the entries that do not have this string are shown. Now choose Mark selected in the Selected dropdown and notice how the entries containing the "error" string are highlighted in red. In the additional dropdown that appeared, we may choose red, green, or blue for highlighting:
Let's add another item here—click on Add below the Items list entry. In the popup, choose Linux servers in the Group dropdown and A test host in the Host dropdown, then click on First logfile in the NAME column. Notice how the entries from both files are shown, and the coloring option is applied on top of that.
That's pretty much it regarding log viewing options in the Zabbix frontend. Note that this is a very limited functionality and for a centralized syslog server with full log analysis options on top of that, a specialized solution should be used—there are quite a lot of free software products available.


