






















































Sampling distributions
In Chapter 7, Basic Statistics, we mentioned how much we love when data follows the normal distribution. One of the reasons for this is that many statistical tests (including the ones we will use in this chapter) rely on data that follows a normal pattern, and for the most part, a lot of real-world data is not normal (surprised?). Take our employee break data for example, you might think I was just being fancy creating data using the Poisson distribution, but I had a reason for this—I specifically wanted non-normal data, as shown:
pd.DataFrame(breaks).hist(bins=50,range=(5,100))
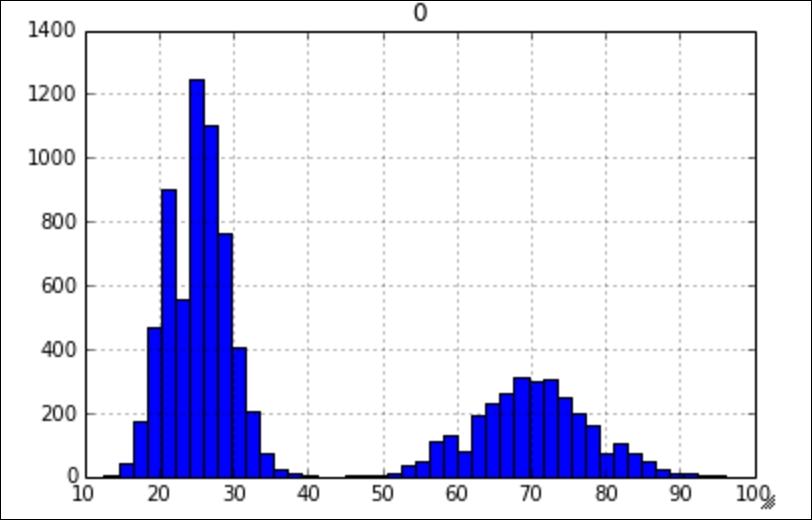
As you can see, our data is definitely not following a normal distribution, it appears to be bi-modal, which means that there are two peaks of break times, at around 25 and 70 minutes. As our data is not normal, many of the most popular statistics tests may not apply, however, if we follow the given procedure, we can create normal data! Think I'm crazy? Well, see for yourself.
First off, we will...









