






















































Understanding network architecture
Network architecture refers to the overall design of a computer network, along with other auxiliary networks. It includes the hardware, software, and protocols that make up the network, as well as the physical and logical layout of the network and the relationships between the various components.
Network architecture should be designed to support the needs and goals of an organization, taking into account factors such as the size of the network, the types of devices and applications that will be traversed across, the number of end users (consumers), the level of security required, and the availability and performance requirements.
The architecture must be able to support the current organizational needs (from the various lines of businesses, stakeholders, leadership, and end users), be flexible for future growth, meet multiple degrees of SLx (such as SLAs and SLOs), and be agile to support shifts in the market, all the while maintaining a cost balance between CapEx and OpEx.
There are many different approaches to designing network architecture, and the most appropriate one will depend on the specific needs and constraints of an organization. Some common types of network architectures include the following:
- Client-server architecture, in which one or more central servers provide services to multiple clients
- Peer-to-peer architecture, in which all devices on a network are able to communicate directly with each other
- Hierarchical architecture, in which a network is divided into multiple layers, each with a specific function
- Hybrid architecture, in which multiple different architectures are combined in order to meet the needs of an organization
- Spine-leaf architecture, to take advantage of high-speed throughput for east–west traffic and a higher level of redundancy
Let’s take a closer look at these architectures.
Client/server architecture
The client/server architecture is a computing model in which the server hosts, delivers, and manages most of the resources and services requested by the client.

Figure 1.3 – An example of a client/server architecture
It’s also known as a networking computing model or client/server network, as all requests and services are delivered over a network. Client/server architecture is a common way to design and implement computer systems. It is used in a wide variety of applications, including web applications, email systems, and database management systems.
These systems can be HR, CMDB, network (fabric) monitoring and logging, or storage systems.
Multiple clients’ requests are made to and from a central server. The server is responsible for handling requests, processing data, and providing a client with the requested information. The client, on the other hand, initiates the request and displays the received data to the user. This architecture is commonly used in distributed computing, where a centralized server manages and distributes data to multiple clients over a network.
The communication between the client and the server typically occurs over a network, such as the internet, and follows a request-response model. Clients make requests to the server for specific services or data, and the server processes those requests and returns the requested information to the clients.
Typically, in a client/server architecture, the client computer is responsible for the user interface. The client computer displays information to the user and accepts input from the user. The server computer is responsible for the data. The server computer stores data and processes data requests from the client computer.
A common example of a client-server architecture, used every day, is a web application. In this case, the client is a web browser (such as Chrome or Firefox) that runs on a user’s computer, and the server is a computer or group of computers that host the web application and store the files and databases that the application uses. The client sends requests to the server (such as to load a web page or submit a form), and the server responds by sending the requested data back to the client.
The following is a request made by a client to reach to load my blog site at www.ahaliblogger.tech.
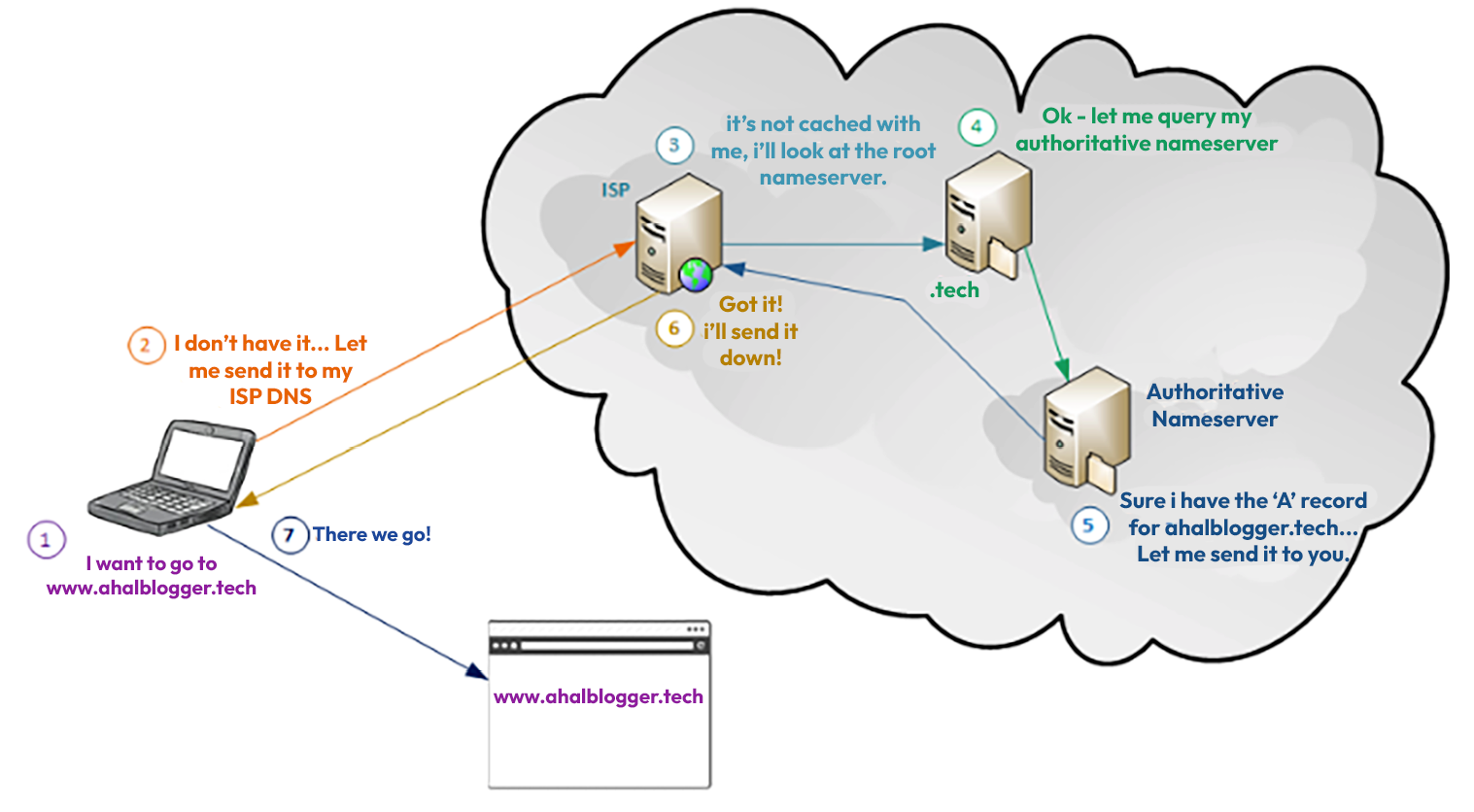
Figure 1.4 – A DNS request flow to ahaliblogger.tech
In the diagram, a client makes a request to reach ahaliblogger.tech. As the request flows through several DNS servers, an authoritative server responds to the client with the proper information.
Client/server architecture has several advantages over other computing models. One advantage is that it is scalable. The systems can be easily expanded to accommodate more users. Another advantage is that it is reliable. Client/server systems are less likely to fail than other networking computing models.
However, client/server architectures also have some disadvantages. One disadvantage is that it can be complex to design and implement. Another disadvantage is that it can be expensive to maintain.
Peer-to-peer architecture
A peer-to-peer (P2P) network architecture is a type of network in which each computer or device (known as a peer) is able to act as both the client and the server. This means that each peer is able to both request and provide a response to other peers on the network, without the need for a central server or authority to manage the network.
Peer-to-peer networks are often decentralized and self-organizing and can be used for a wide range of applications, including file sharing, online gaming, and distributed computing.
An example of a peer-to-peer network architecture is a BitTorrent file-sharing network.

Figure 1.5 – How BitTorrent works
In this network, clients (peers) share files with each another by breaking the files into small pieces and distributing them across the network. The (BitTorrent) client contacts a “tracker” specified in the .torrent file (https://www.howtogeek.com/141257/htg-explains-how-does-bittorrent-work/).
Each client is able to download pieces of the file from multiple other peers and can also upload pieces of the file to other peers. This allows the efficient distribution of large files, as the load is distributed among many users rather than relying on a central server.
Hierarchical architecture
Hierarchical network architecture is a type of network design that uses a multi-layered approach to organize and manage network resources. It separates a network into distinct layers, where each layer has a defined function that, in turn, defines its role in the network. These layers are the access layer, the distribution layer, and the core layer.

Figure 1.6 – The three-tier network architecture model
The preceding diagram illustrates each layer in the hierarchical architecture model.

Figure 1.7 – The access layer of the three-tier hierarchical architecture model
The access layer is the point of entry into a network, and it is where end user devices such as computers, servers, printers, VOIP phones, and other IP devices connect. The access layer is responsible for providing basic (and, at times, more complex) connectivity and controlling access to the network.

Figure 1.8 – The distribution layer of the three-tier hierarchical architecture model
The distribution layer is where a network is divided into different segments or VLANs, and it acts as a bridge between the access and core layers. This layer is responsible for routing and filtering traffic, and providing security and Quality of Service (QoS) features.

Figure 1.9 – The core layer of the three-tier hierarchical architecture model
The core layer is the backbone of a network, and it is responsible for the high-speed switching and routing of traffic between different segments of the network. This layer is designed to be highly available and redundant, providing a fast and efficient data transfer throughout the network.

Figure 1.10 – The collapsed core model
The preceding diagram shows a variation of the hierarchical architecture, where the distribution and core layers are combined into what is known as a collapsed layer. In this design, the core and distribution functions are performed within one device (or a pair of devices).
The hierarchical design allows for better scalability, security, and manageability. Separating the different functions into specific layers also allows for better troubleshooting, as the network administrators can easily identify the problem area by looking at the specific layer.
The most common hierarchical architecture used in today’s network is spine/leaf.
Hybrid network architecture
Hybrid network architecture is a type of network architecture that combines elements of two or more different types of network architectures. The most common types of network architectures that are combined in a hybrid network are peer-to-peer (P2P) and client-server (C/S) architectures.
In a hybrid P2P/C/S network, a network is made up of both clients and servers, but the clients also have the ability to act as servers. This allows for network resources to be used more efficiently and can provide a better user experience, as data can be shared and distributed more easily.
For example, a hybrid P2P/C/S network might be used in a file-sharing application, where users can upload and download files from a central server but also share files directly with one another.
Another example would be combining the use of both wired and wireless connections. This allows a more flexible and reliable network – for example, a wireless connection can be used for mobile devices, while a wired connection can be used for more demanding applications such as video conferencing.

Figure 1.11 – An example of hybrid architecture – wireless and wired
A more common approach to hybrid network architecture is distributed computing systems, where a combination of cloud computing and edge computing is used. This allows data processing to take place at the edge of the network, close to the source of the data, while still giving you the ability to offload to the cloud for more processing power and storage.
An example is Tesla’s self-driving car. The car’s sensor constantly monitors certain regions around it, detecting an obstacle or pedestrian in its way, and then the car must be stopped or move around without hitting anything (https://www.geeksforgeeks.org/difference-between-edge-computing-and-fog-computing/). The vehicle must process the data quickly to determine what needs to be done next and also send it to backend systems (cloud or on-premises), where it is put in a data store (i.e., Hadoop clusters or cloud buckets). At this point, the data can be processed for further analysis, such as ETL processing or AI/ML pipelines.
The following diagram illustrates the use of edge devices in hybrid network architecture.

Figure 1.12 – Hybrid architecture – edge computing to cloud computing
Hybrid network architectures can provide the best of both worlds, the flexibility of P2P and the central control of C/S, and it can also allow for more efficient use of resources, better security and scalability, and a better user experience.
Spine-leaf architecture
A spine-leaf network architecture is a type of data center network architecture in which all devices are connected to leaf switches, which, in turn, are connected to spine switches.
The leaf switches provide end devices with access to a network, while the spine switches provide high-speed interconnections between the leaf switches. This architecture creates a flat, non-blocking network that allows efficient communication between devices and provides high redundancy.

Figure 1.13 – Spine-leaf architecture
The architecture can also be easily scaled to support a large number of devices and high throughput. The purpose of this architecture is to provide a cost-effective, scalable, and high-performance solution for modern data centers.


