






















































Query optimization essentials
The Query Processor is also the component inside the SQL Database Engine that is responsible for query optimization. This is the second stage of query processing and its goal is to produce a query plan that can then be cached for all subsequent uses of the same query. In this section, we will focus on the highlighted sections of the following diagram that handle query optimization:
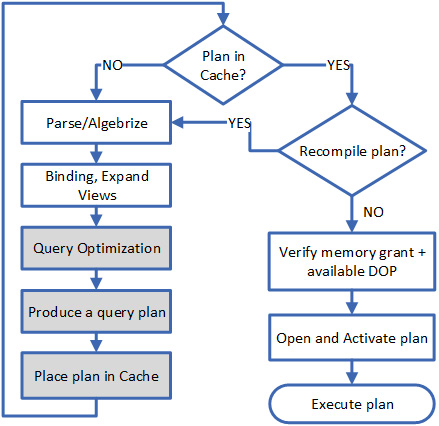
Figure 1.5: States of query processing related to query optimization
The SQL Database Engine uses cost-based optimization, which means that the Query Optimizer is driven mostly by estimations of the required cost to access and transform data (such as joins and aggregations) that will produce the intended result set. The purpose of the optimization process is to reasonably minimize the I/O, memory, and compute resources needed to execute a query in the fastest way possible. But it is also a time-bound process and can time out. This means that the Query Optimizer may not iterate through all the possible optimization permutations of a given T-SQL statement, but rather stops itself after finding an estimated “good enough” compromise between low resource usage and faster execution times.
For this, the Query Optimizer takes several inputs to later produce what is called a query execution plan. These inputs are the following:
- The incoming T-SQL statement, including any input parameters
- The loaded metadata, such as statistics histograms, available indexes and indexed views, partitioning, and the number of available schedulers
Note
We will further discuss the role of statistics in Chapter 2, Mechanics of the Query Optimizer, and dive deeper into execution plans in Chapter 3, Exploring Query Execution Plans, later in this book.
As part of the optimization process, the SQL Database Engine also uses internal transformation rules and some heuristics to narrow the optimization space – in other words, to narrow the number of transformation rules that can be applied to the incoming T-SQL statement. The SQL Database Engine has over 400 such transformation rules that are applicable depending on the incoming T-SQL statement. For reference, these rules are exposed in the undocumented dynamic management view sys.dm_exec_query_transformation_stats. The name column in this DMV contains the internal name for the transformation rule. An example is LOJNtoNL: an implementation rule to transform a logical LEFT OUTER JOIN to a physical nested loops join operator.
And so, the Query Optimizer may transform the T-SQL statement as written by a developer before it is allowed to execute. This is because T-SQL is a declarative language: the developer declares what is intended, but the SQL Database Engine determines how to carry out the declared intent. When evaluating transformations, the Query Optimizer must adhere to the rules of logical operator precedence. When a complex expression has multiple operators, operator precedence determines the sequence in which the operations are performed. For example, in a query that uses comparison and arithmetic operators, the arithmetic operators are handled before the comparison operators. This determines whether a Compute Scalar operator can be placed before or after a Filter operator.
The Query Optimizer will consider numerous strategies to search for an efficient execution plan, including the following:
- Index selection
Are there indexes to cover the whole or parts of the query? This is done based on which search and join predicates (conditions) are used, and which columns are required for the query output.
- Logical join reordering
The order in which tables are actually joined may not be the same order as they are written in the T-SQL statement itself. The SQL Database Engine uses heuristics as well as statistics to narrow the number of possible join permutations to test, and then estimate which join order results in early filtering of rows and less resource usage. For example, depending on how a query that joins 6 tables is written, possible join reordering permutations range from roughly 700 to over 30,000.
- Partitioning
Is data partitioned? If so, and depending on the predicate, can the SQL Database Engine avoid accessing some partitions that are not relevant for the query?
- Parallelism
Is it estimated that execution will be more efficient if multiple CPUs are used?
- Whether to expand views
Is it better to use an indexed view, or conversely expand and inline the view definition to account for the base tables?
- Join elimination
Are two tables being joined in a way that the number of rows resulting from that join is zero? If so, the join may not even be executed.
- Sub-query elimination
This relies on the same principle as join elimination. Was it estimated that the correlated or non-correlated sub-query will produce zero rows? If so, the sub-query may not even be executed.
- Constraint simplification
Is there an active constraint that prevents any rows from being generated? For example, does a column have a non-nullable constraint, but the query predicate searches for null values in that column? If so, then that part of the query may not even be executed.
- Eligibility for parameter sensitivity optimization
Is the database where the query is executing subject to Database Compatibility Level 160? If so, are there parameterized predicates considered at risk of being impacted by parameter sniffing?
- Halloween protection
Is this an update plan? If so, is there a need to add a blocking operator?
Note
An update plan has two parts: a read part that identifies the rows to be updated and a write part that performs the updates, which must be executed in two separate steps. In other words, the actual update of rows must not affect the selection of which rows to update. This problem of ensuring that the write cursor of an update plan does not affect the read cursor is known as “Halloween protection” as it was discovered by IBM researchers more than 40 years ago, precisely on Halloween.
For the Query Optimizer to do its job efficiently in the shortest amount of time possible, data professionals need to do their part, which can be distilled into three main principles:
- Design for performance
Ensure that our tables are designed with purposeful use of the appropriate data types and lengths, that our most used predicates are covered by indexes, and that the engine is allowed to identify and create the required statistical information.
- Write simple T-SQL queries
Be purposeful with the number of joined tables, how the joins are expressed, the number of columns needed for the result set, how parameters and variables are declared, and which data transformations are used. Complexity comes at a cost and it may be a wise strategy to break down long T-SQL statements into smaller parts that create intermediate result sets.
- Maintain our database health
From a performance standpoint alone, ensure that index maintenance and statistics updates are done regularly.
At this point, it starts to become clear that how we write a query is fundamental to achieving good performance. But it is equally important to make sure the Query Optimizer is given a chance to do its job to produce an efficient query plan. That job is dependent on having metadata available that accurately portrays the data distribution in base tables and indexes. Later in this book, in Chapter 5, Writing Elegant T-SQL Queries, we will further distill what data professionals need to know to write efficient T-SQL that performs well.
Also, in the Mechanics of the Query Optimizer chapter, we will cover the Query Optimizer and the estimation process in greater detail. Understanding how the SQL Database Engine optimizes a query and what the process looks like is a fundamental step toward troubleshooting query performance – a task that every data professional will do at some point in their career.
Now that we have reviewed query compilation and optimization, the next step is query execution, which we will explore in the following section.









