Let's now look at the following core concepts in Spark and PySpark:
- SparkContext
- SparkConf
- Spark shell
 United States
United States
 United Kingdom
United Kingdom
 India
India
 Germany
Germany
 France
France
 Canada
Canada
 Russia
Russia
 Spain
Spain
 Brazil
Brazil
 Australia
Australia
 Argentina
Argentina
 Austria
Austria
 Belgium
Belgium
 Bulgaria
Bulgaria
 Chile
Chile
 Colombia
Colombia
 Cyprus
Cyprus
 Czechia
Czechia
 Denmark
Denmark
 Ecuador
Ecuador
 Egypt
Egypt
 Estonia
Estonia
 Finland
Finland
 Greece
Greece
 Hungary
Hungary
 Indonesia
Indonesia
 Ireland
Ireland
 Italy
Italy
 Japan
Japan
 Latvia
Latvia
 Lithuania
Lithuania
 Luxembourg
Luxembourg
 Malaysia
Malaysia
 Malta
Malta
 Mexico
Mexico
 Netherlands
Netherlands
 New Zealand
New Zealand
 Norway
Norway
 Philippines
Philippines
 Poland
Poland
 Portugal
Portugal
 Romania
Romania
 Singapore
Singapore
 Slovakia
Slovakia
 Slovenia
Slovenia
 South Africa
South Africa
 South Korea
South Korea
 Sweden
Sweden
 Switzerland
Switzerland
 Taiwan
Taiwan
 Thailand
Thailand
 Turkey
Turkey
 Ukraine
Ukraine

Let's now look at the following core concepts in Spark and PySpark:
SparkContext is an object or concept within Spark. It is a big data analytical engine that allows you to programmatically harness the power of Spark.
The power of Spark can be seen when you have a large amount of data that doesn't fit into your local machine or your laptop, so you need two or more computers to process it. You also need to maintain the speed of processing this data while working on it. We not only want the data to be split among a few computers for computation; we also want the computation to be parallel. Lastly, you want this computation to look like one single computation.
Let's consider an example where we have a large contact database that has 50 million names, and we might want to extract the first name from each of these contacts. Obviously, it is difficult to fit 50 million names into your local memory, especially if each name is embedded within a larger contacts object. This is where Spark comes into the picture. Spark allows you to give it a big data file, and will help in handling and uploading this data file, while handling all the operations carried out on this data for you. This power is managed by Spark's cluster manager, as shown in the following diagram:
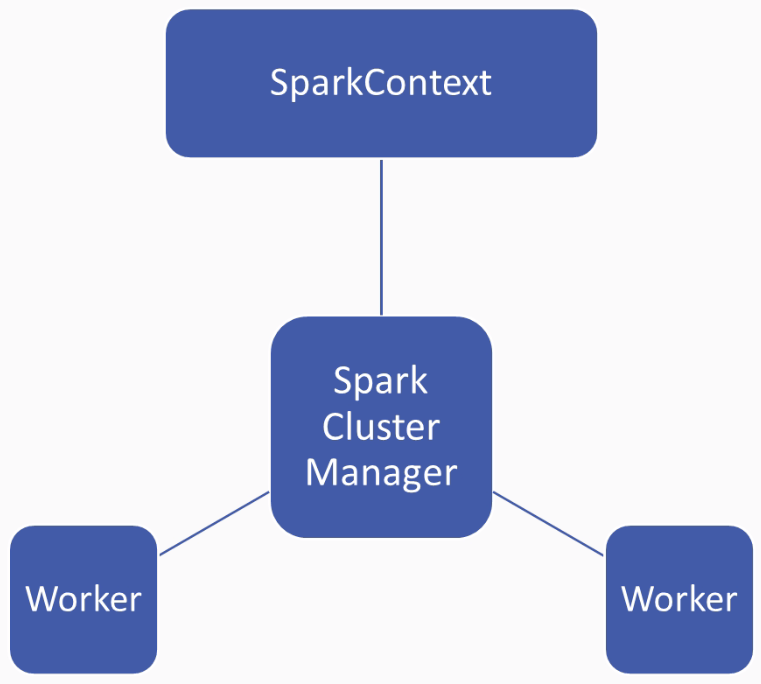
The cluster manager manages multiple workers; there could be 2, 3, or even 100. The main point is that Spark's technology helps in managing this cluster of workers, and you need a way to control how the cluster is behaving, and also pass data back and forth from the clustered rate.
A SparkContext lets you use the power of Spark's cluster manager as with Python objects. So with a SparkContext, you can pass jobs and resources, schedule tasks, and complete tasks the downstream from the SparkContext down to the Spark Cluster Manager, which will then take the results back from the Spark Cluster Manager once it has completed its computation.
Let's see what this looks like in practice and see how to set up a SparkContext:
from pyspark import SparkContext
sc = SparkContext('local', 'hands on PySpark')
visitors = [10, 3, 35, 25, 41, 9, 29]
df_visitors = sc.parallelize(visitors)
df_visitors_yearly = df_visitors.map(lambda x: x*365).collect()
print(df_visitors_yearly)
Let's take an example; if we were to analyze the synthetic datasets of visitor counts to our clothing store, we might have a list of visitors denoting the daily visitors to our store. We can then create a parallelized version of the DataFrame, call sc.parallelize(visitors), and feed in the visitors datasets. df_visitors then creates for us a DataFrame of visitors. We can then map a function; for example, making the daily numbers and extrapolating them into a yearly number by mapping a lambda function that multiplies the daily number (x) by 365, which is the number of days in a year. Then, we call a collect() function to make sure that Spark executes on this lambda call. Lastly, we print out df_ visitors_yearly. Now, we have Spark working on this computation on our synthetic data behind the scenes, while this is simply a Python operation.
We will go back into our Spark folder, which is spark-2.3.2-bin-hadoop2.7, and start our PySpark binary by typing .\bin\pyspark.
We can see that we've started a shell session with Spark in the following screenshot:

Spark is now available to us as a spark variable. Let's try a simple thing in Spark. The first thing to do is to load a random file. In each Spark installation, there is a README.md markdown file, so let's load it into our memory as follows:
text_file = spark.read.text("README.md")
If we use spark.read.text and then put in README.md, we get a few warnings, but we shouldn't be too concerned about that at the moment, as we will see later how we are going to fix these things. The main thing here is that we can use Python syntax to access Spark.
What we have done here is put README.md as text data read by spark into Spark, and we can use text_file.count() can get Spark to count how many characters are in our text file as follows:
text_file.count()
From this, we get the following output:
103
We can also see what the first line is with the following:
text_file.first()
We will get the following output:
Row(value='# Apache Spark')
We can now count a number of lines that contain the word Spark by doing the following:
lines_with_spark = text_file.filter(text_file.value.contains("Spark"))
Here, we have filtered for lines using the filter() function, and within the filter() function, we have specified that text_file_value.contains includes the word "Spark", and we have put those results into the lines_with_spark variable.
We can modify the preceding command and simply add .count(), as follows:
text_file.filter(text_file.value.contains("Spark")).count()
We will now get the following output:
20
We can see that 20 lines in the text file contain the word Spark. This is just a simple example of how we can use the Spark shell.
SparkConf allows us to configure a Spark application. It sets various Spark parameters as key-value pairs, and so will usually create a SparkConf object with a SparkConf() constructor, which would then load values from the spark.* underlying Java system.
There are a few useful functions; for example, we can use the sets() function to set the configuration property. We can use the setMaster() function to set the master URL to connect to. We can use the setAppName() function to set the application name, and setSparkHome() in order to set the path where Spark will be installed on worker nodes.



















