






















































Unordered Associative Container
Overview
With the new C++11 standard, C++ has four unordered associative containers: std::unordered_map, std::unordered_multimap, std::unordered_set and std::unordered_multiset. They have a lot in common with their namesakes, the ordered associative containers. The difference is that the unordered ones have a richer interface and their keys are not sorted.
This shows the declaration of a std::unordered_map.
template< class key, class val, class Hash= std::hash<key>,
class KeyEqual= std::equal_to<key>,
class Alloc= std::allocator<std::pair<const key, val>>>
class unordered_map;
Like std::map, std::unordered_map has an allocator, but std::unordered_map needs no comparison function. Instead std::unordered_map needs two additional functions: One, to determine the hash value of its key: std::has<key> and second, to compare the keys for equality: std::equal_to<key>. Because of the three default template parameters , you have only to provide the type of the key and the value of the std::unordered_map: std::unordered_map<char,int> unordMap.
Keys and Values
There are special rules for the key and the value of an unordered associative container.
The key has to be
- equal comparable,
- available as hash value,
- copyable or moveable.
The value has to be
- default constructible,
- copyable or moveable.
Performance
Performance - that’s the simple reason - why the unordered associative containers were so long missed in C++. In the example below, one million randomly created values are read from a 10 million big std::map and std::unordered_map. The impressive result is that the linear access time of an unordered associative container is 20 times faster than the access time of an ordered associative container. That is just the difference between constant and logarithmic complexity O(log n) of these operations.
// associativeContainerPerformance.cpp
...
#include <map>#include <unordered_map>...
using std::chrono::duration;
static const long long mapSize= 10000000;
static const long long accSize= 1000000;
...
// read 1 million arbitrary values from a std::map
// with 10 million values from randValues
auto start= std::chrono::system_clock::now();
for (long long i= 0; i < accSize; ++i){myMap[randValues[i]];}
duration<double> dur= std::chrono::system_clock::now() - start;
std::cout << dur.count() << " sec"; // 9.18997 sec
// read 1 million arbitrary values from a std::unordered_map
// with 10 million values
auto start2= std::chrono::system_clock::now();
for (long long i= 0; i < accSize; ++i){ myUnorderedMap[randValues[i]];}
duration<double> dur2= std::chrono::system_clock::now() - start2;
std::cout << dur2.count() << " sec"; // 0.411334 sec
The Hash Function
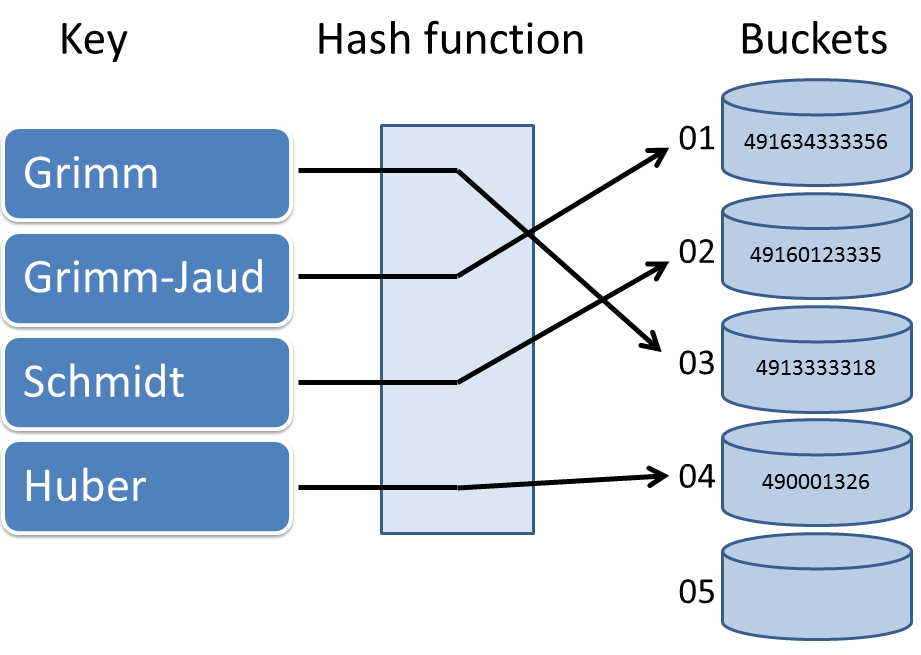
The reason for the constant access time of the unordered associative container is the hash function, which is schematically shown here. The hash function maps the key to its value the so-called has value. A hash function is good if it produces as few collisions as possible and equally distributes the keys onto the buckets. Because the execution of the hash function takes a constant amount of time, the access of the elements is in the base case also constant.
The hash function
- is already defined for the built-in types like boolean, natural numbers and floating point numbers,
- is available for
std::stringandstd::wstring, - generates for a C string
const chara hash value of the pointer address, - can be defined for user-defined data types.
For user-defined types which are used as a key for an unordered associative container, you have to keep two requirements to keep in mind. They need a hash function and have to be comparable to equal.
// unorderedMapHash.cpp
...
#include <unordered_map>...
struct MyInt{
MyInt(int v):val(v){}
bool operator== (const MyInt& other) const {
return val == other.val;
}
int val;
};
struct MyHash{
std::size_t operator()(MyInt m) const {
std::hash<int> hashVal;
return hashVal(m.val);
}
};
std::ostream& operator << (std::ostream& st, const MyInt& myIn){
st << myIn.val ;
return st;
}
typedef std::unordered_map<MyInt, int, MyHash> MyIntMap;
MyIntMap myMap{{MyInt(-2), -2}, {MyInt(-1), -1}, {MyInt(0), 0}, {MyInt(1), 1}};
for(auto m : myMap) std::cout << "{" << m.first << "," << m.second << "} ";
// {MyInt(1),1} {MyInt(0),0} {MyInt(-1),-1} {MyInt(-2),-2}
std::cout << myMap[MyInt(-2)] << std::endl; // -2
The Details
The unordered associative containers store their indices in buckets. In which bucket the index goes is due to the hash function, which maps the key to the index. If different keys are mapped to the same index, it’s called a collision. The hash function tries to avoid this.
Indices are typically be stored in the bucket as a linked list. Since the access to the bucket is constant, the access in the bucket is linear. The number of buckets is called capacity, the average number of elements for each bucket is called the load factor. In general, the C++ runtime generates new buckets if the load factor is greater than 1. This process is called rehashing and can also explicitly be triggered:
// hashInfo.cpp
...
#include <unordered_set>...
using namespace std;
void getInfo(const unordered_set<int>& hash){
cout << "hash.bucket_count(): " << hash.bucket_count();
cout << "hash.load_factor(): " << hash.load_factor();
}
unordered_set<int> hash;
cout << hash.max_load_factor() << endl; // 1
getInfo(hash);
// hash.bucket_count(): 1
// hash.load_factor(): 0
hash.insert(500);
cout << hash.bucket(500) << endl; // 5
// add 100 abitrary values
fillHash(hash, 100);
getInfo(hash);
// hash.bucket_count(): 109
// hash.load_factor(): 0.88908
hash.rehash(500);
getInfo(hash);
// hash.bucket_count(): 541
// hash.load_factor(): 0.17298
cout << hash.bucket(500); // 500
With the method max_load_factor, you can read and set the load factor. So you can influence the probability of collisions and rehashing. I want to emphasise one point in the short example above. The key 500 is at first in the 5th bucket, but after rehashing is in the 500th bucket.





