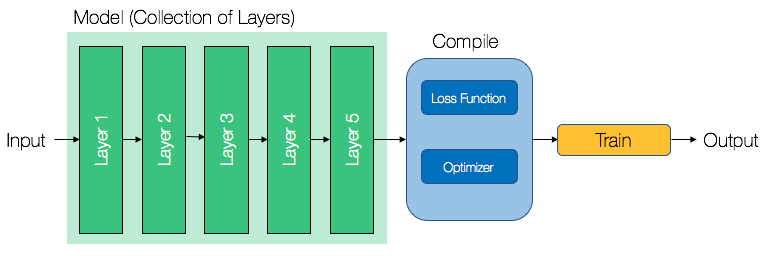
Let's take a look at how we can use Keras to build the two-layer neural network that we introduced earlier. To build a linear collection of layers, first declare a Sequential model in Keras:
from keras.models import Sequential
model = Sequential()
This creates an empty Sequential model that we can now add layers to. Adding layers in Keras is simple and similar to stacking Lego blocks on top of one another. We start by adding layers from the left (the layer closest to the input):
from keras.layers import Dense
# Layer 1
model.add(Dense(units=4, activation='sigmoid', input_dim=3))
# Output Layer
model.add(Dense(units=1, activation='sigmoid'))
Stacking layers in Keras is as simple as calling the model.add() command. Notice that we had to define the number of units in each layer. Generally, increasing the number of units increases the complexity of the model, as it means that there are more weights to be trained. For the first layer, we had to define input_dim. This informs Keras the number of features (that is, columns) in the dataset. Also, note that we have used a Dense layer. A Dense layer is simply a fully connected layer. In later chapters, we will introduce other kinds of layers, specific to different types of problems.
We can verify the structure of our model by calling the model.summary() function:
print(model.summary())
The output is shown in the following screenshot:
The number of params is the number of weights and biases we need to train for the model that we have just defined.
Once we are satisfied with our model's architecture, let's compile it and start the training process:
from keras import optimizers
sgd = optimizers.SGD(lr=1)
model.compile(loss='mean_squared_error', optimizer=sgd)
Note that we have defined the learning rate of the sgd optimizer to be 1.0 (lr=1). In general, the learning rate is a hyperparameter of the neural network that needs to be tuned carefully depending on the problem. We will take a closer look at tuning hyperparameters in later chapters.
The mean_squared_error loss function in Keras is similar to the sum-of-squares error that we have defined earlier. We are using the SGD optimizer to train our model. Recall that gradient descent is the method of updating the weights and biases by moving it toward the derivative of the loss function with respect to the weights and biases.
Let's use the same data that we used earlier to train our neural network. This will allow us to compare the predictions obtained using Keras versus the predictions obtained when we created our neural network from scratch earlier.
Let's define an X and Y NumPy array, corresponding to the features and the target variables respectively:
import numpy as np
# Fixing a random seed ensures reproducible results
np.random.seed(9)
X = np.array([[0,0,1],
[0,1,1],
[1,0,1],
[1,1,1]])
y = np.array([[0],[1],[1],[0]])
Finally, let's train the model for 1500 iterations:
model.fit(X, y, epochs=1500, verbose=False)
To get the predictions, run the model.predict() command on our data:
print(model.predict(X))
The preceding code gives the following output:
Comparing this to the predictions that we obtained earlier, we can see that the results are extremely similar. The major advantage of using Keras is that we did not have to worry about the low-level implementation details and mathematics while building our neural network, unlike what we did earlier. In fact, we did no math at all. All we did in Keras was to call a series of APIs to build our neural network. This allows us to focus on high-level details, enabling rapid experimentation.























































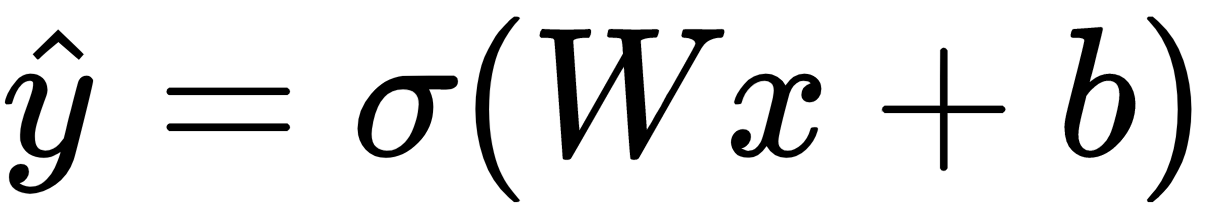
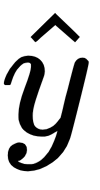 is the output,
is the output,  is the activation function,
is the activation function, 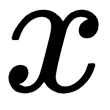 is the input, and
is the input, and 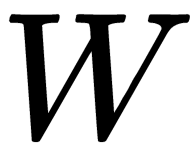 and
and 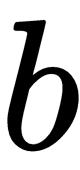 are the weights and biases respectively.
are the weights and biases respectively.






















