























































Limitations of neural networks
In this section, we will discuss in detail the issues faced by neural networks, which will become the stepping stone for building deep learning networks.
Vanishing gradients, local optimum, and slow training
One of the major issues with neural networks is the problem of "vanishing gradient" (References [8]). We will try to give a simple explanation of the issue rather than exploring the mathematical derivations in depth. We will choose the sigmoid activation function and a two-layer neural network, as shown in the following figure, to demonstrate the issue:
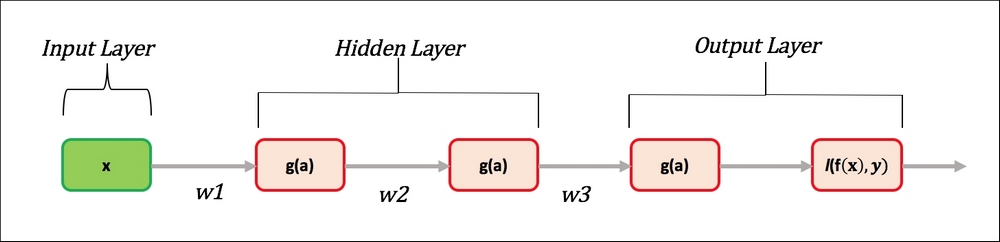
Figure 5: Vanishing Gradient issue.
As we saw in the activation function description, the sigmoid function squashes the output between the range 0 and 1. The derivative of the sigmoid function g'(a) = g(a)(1 – g(a)) has a range between 0 and 0.25. The goal of learning is to minimize the output loss, that is,  . In general, the output error does not go to 0, so maximum iterations; a user-specified parameter determines...
. In general, the output error does not go to 0, so maximum iterations; a user-specified parameter determines...























