






















































Preparing and testing the serve script in Python
In this recipe, we will create a sample serve script using Python that loads the model and sets up a Flask server for returning predictions. This will provide us with a template to work with and test the end-to-end training and deployment process before adding more complexity to the serve script. The following diagram shows the expected behavior of the Python serve script that we will prepare in this recipe. The Python serve script loads the model file from the /opt/ml/model directory and runs a Flask web server on port 8080:
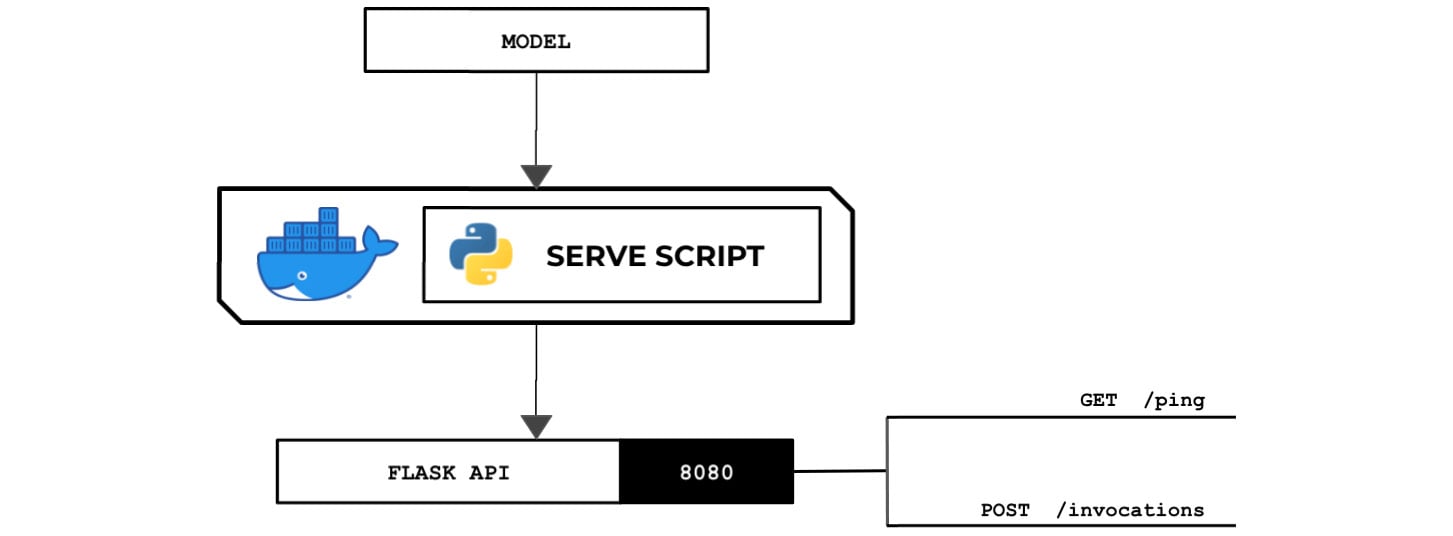
Figure 2.49 – The Python serve script loads and deserializes the model and runs a Flask API server that acts as the inference endpoint
The web server is expected to have the /ping and /invocations endpoints. This standalone Python script will run inside a custom container that allows the Python train and serve scripts to run.
Getting ready
Make sure you have completed the Preparing and testing the train script in Python recipe.
How to do it…
We will start by preparing the serve script:
- Inside the
ml-pythondirectory, double-click theservefile to open it inside the Editor pane:
Figure 2.50 – Locating the empty serve script inside the ml-python directory
Here, we can see three files under the
ml-pythondirectory. Remember that in the Setting up the Python and R experimentation environments recipe, we prepared an emptyservescript:
Figure 2.51 – Empty serve file
In the next couple of steps, we will add the lines of code for the
servescript. - Add the following code to the
servescript to import and initialize the prerequisites:#!/usr/bin/env python3 import numpy as np from flask import Flask from flask import Response from flask import request from joblib import dump, load
- Initialize the Flask app. After that, define the
get_path()function:app = Flask(__name__) PATHS = { 'hyperparameters': 'input/config/hyperparameters.json', 'input': 'input/config/inputdataconfig.json', 'data': 'input/data/', 'model': 'model/' } def get_path(key): return '/opt/ml/' + PATHS[key] - Define the
load_model()function by adding the following lines of code to theservescript:def load_model(): model = None filename = get_path('model') + 'model' print(filename) model = load(filename) return modelNote that the filename of the model here is
modelas we specified this model artifact filename when we saved the model using thedump()function in the Preparing and testing the train script in Python recipe.Important note
Note that it is important to choose the right approach when saving and loading machine learning models. In some cases, machine learning models from untrusted sources may contain malicious instructions that cause security issues such as arbitrary code execution! For more information on this topic, feel free to check out https://joblib.readthedocs.io/en/latest/persistence.html.
- Define a function that accepts the POST requests for the
/invocationsroute:@app.route("/invocations", methods=["POST"]) def predict(): model = load_model() post_body = request.get_data().decode("utf-8") payload_value = float(post_body) X_test = np.array( [payload_value] ).reshape(-1, 1) y_test = model.predict(X_test) return Response( response=str(y_test[0]), status=200 )This function has five parts: loading the trained model using the
load_model()function, reading the POST request data using therequest.get_data()function and storing it inside thepost_bodyvariable, transforming the prediction payload into the appropriate structure and type using thefloat(),np.array(), andreshape()functions, making a prediction using thepredict()function, and returning the prediction value inside aResponseobject.Important note
Note that the implementation of the
predict()function in the preceding code block can only handle predictions involving single payload values. At the same time, it can't handle different types of input similar to how built-in algorithms handle CSV, JSON, and other types of request formats. If you need to provide support for this, additional lines of code need to be added to the implementation of thepredict()function. - Prepare the
/pingroute and handler by adding the following lines of code to theservescript:@app.route("/ping") def ping(): return Response(response="OK", status=200) - Finally, use the
app.run()method and bind the web server to port8080:app.run(host="0.0.0.0", port=8080)
Tip
You can access a working copy of the
servescript file in this book's GitHub repository: https://github.com/PacktPublishing/Machine-Learning-with-Amazon-SageMaker-Cookbook/blob/master/Chapter02/ml-python/serve. - Create a new Terminal in the bottom pane, below the Editor pane:

Figure 2.52 – New Terminal
Here, we can see a Terminal tab already open. If you need to create a new one, simply click the plus (+) sign and then click New Terminal. We will run the next few commands in this Terminal tab.
- Install the
Flaskframework usingpip. We will use Flask for our inference API endpoint:pip3 install flask
- Navigate to the
ml-pythondirectory:cd /home/ubuntu/environment/opt/ml-python
- Make the
servescript executable usingchmod:chmod +x serve
- Test the
servescript using the following command:./serve
This should start the Flask app, as shown here:

Figure 2.53 – Running the serve script
Here, we can see that our
servescript has successfully run aflaskAPI web server on port8080.Finally, we will trigger this running web server.
- Open a new Terminal window:

Figure 2.54 – New Terminal
As we can see, we are creating a new Terminal tab as the first tab is already running the
servescript. - In a separate Terminal window, test the
pingendpoint URL using thecurlcommand:SERVE_IP=localhost curl http://$SERVE_IP:8080/ping
Running the previous line of code should yield an
OKmessage from the/pingendpoint. - Test the invocations endpoint URL using the
curlcommand:curl -d "1" -X POST http://$SERVE_IP:8080/invocations
We should get a value similar or close to
881.3428400857507after invoking theinvocationsendpoint.
Now, let's see how this works!
How it works…
In this recipe, we prepared the serve script in Python. The serve script makes use of the Flask framework to generate an API that allows GET requests for the /ping route and POST requests for the /invocations route.
The serve script is expected to load the model file(s) from the /opt/ml/model directory and run a backend API server inside the custom container. It should provide a /ping route and an /invocations route. With these in mind, our bare minimum Flask application template may look like this:
from flask import Flask
app = Flask(__name__)
@app.route("/ping")
def ping():
return <RETURN VALUE>
@app.route("/invocations", methods=["POST"])
def predict():
return <RETURN VALUE>
The app.route() decorator maps a specified URL to a function. In this template code, whenever the /ping URL is accessed, the ping() function is executed. Similarly, whenever the /invocations URL is accessed with a POST request, the predict() function is executed.
Note
Take note that we are free to use any other web framework (for example, the Pyramid Web Framework) for this recipe. So long as the custom container image has the required libraries for the script that's been installed, then we can import and use these libraries in our script files.

