






















































Q-learning is considered one of the most popular and often used foundational RL methods . The method itself was developed by Chris Watkins in 1989 as part of his thesis, Learning from Delayed Rewards. Q-learning or rather Deep Q-learning, which we will cover in Chapter 6, Going Deep with DQN, became so popular because of its use by DeepMind (Google) to play classic Atari games better than a human. What Watkins did was show how an update could be applied across state-action pairs using a learning rate and discount factor gamma.
This improved the update equation into a Q or quality of state-action update equation, as shown in the following formula:
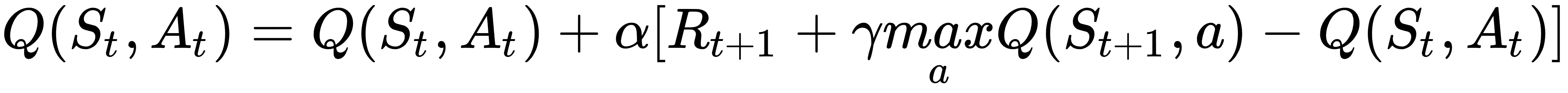
In the previous equation, we have the following:
 The current state-action quality being updated
The current state-action quality being updated The learning rate
The learning rate The reward for the next state
The reward for the next state Gamma, the discount factor
Gamma, the discount factor Take the max best or greedy action...
Take the max best or greedy action...








