






















































Model and prediction-centric debugging
The predictions of a model in the training, testing, and production stages could help us detect issues with the models and find opportunities to improve them. Here, we will briefly review some aspects of model- and prediction-centric model debugging. You can read more details about these problems and other considerations in achieving a reliable model, how to identify the source of the issues, and how to resolve them in future chapters of this book.
Underfitting and overfitting
When we train a model, such as a supervised learning model, the goal is to have high performance not just in training but also in testing. When a model has low performance even in a training set, we need to deal with the issue of underfitting. We can develop more complicated models, such as a random forest or deep learning model, instead of linear and logistic regression models. More complex models might result in lower underfitting, but they might cause overfitting and result in lower generalizability of the prediction to test or production data (Figure 1.5):
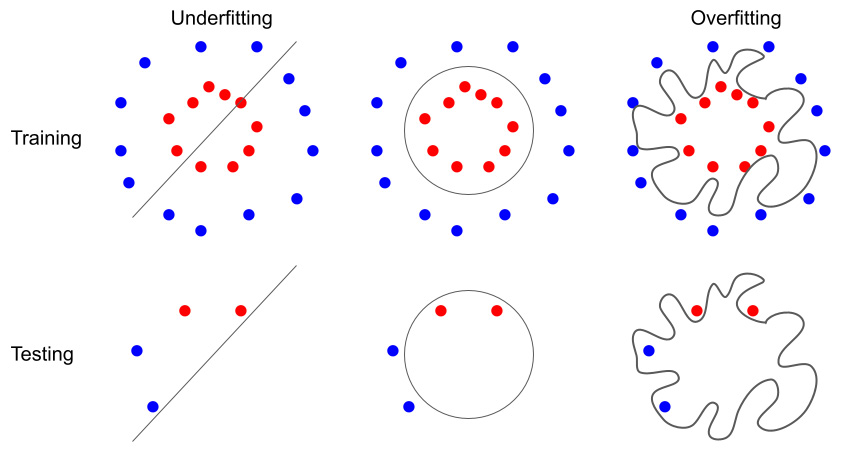
Figure 1.5 – Schematic illustration of underfitting and overfitting
Algorithm and hyperparameter selection determine the level of complexity and the chance of underfitting or overfitting when training and testing a machine learning model. For example, by choosing a model that can learn nonlinear patterns instead of linear models, your model could have a higher chance of low underfitting as it could identify more complex patterns in training data. But at the same time, you could increase the chance of overfitting as some of the complex patterns in the training data might not be generalizable to the test data (Figure 1.5). There are approaches to assess underfitting and overfitting that will help you develop a high-performance and generalizable model. We will discuss these in future chapters.
Model hyperparameters
Some parameters can affect the performance of a machine learning model that usually do not get optimized automatically in the training process. These are called hyperparameters. We will go through examples of such hyperparameters, such as the number of trees in a random forest model or the size of hidden layers in neural network models, in future chapters.
Inference in model testing and production
The eventual goal of machine learning modeling is to have a highly effective model in production. When we test the model, we are assessing its generalizability, but we cannot be sure about its performance on the data it has not seen. The data that’s used for training machine learning models could become out of date. For example, the changes in the trends of the clothing market could make predictions of a model for clothing recommendation unreliable.
There are different concepts in this topic, such as data variance, data drift, and model drift, all of which we will cover in the next few chapters.
Data or hyperparameters for changing landscapes
When we train a machine learning model with specific training data and a set of hyperparameters, the values of model parameters get changed so that they’re as close to an optimum point as possible for a defined objective or loss function. The two other tools to achieve a better model are providing better data for training and selecting better hyperparameters. Each algorithm has a capacity for performance improvement. By playing with model hyperparameters alone, you cannot develop the best possible model. In the same way, by increasing the quality and quantity of your data and keeping your model hyperparameters the same, you could also not achieve the best performance possible. So, data and hyperparameters come hand in hand. Before you read the next chapters, remember that by spending more time and money on hyperparameter optimization alone, you cannot necessarily get a better model. We will look at this in more detail later in this book.


