






















































Kubernetes basic workflow
We saw earlier a typical workflow showing how Kubernetes works with Kubernetes components, and how they collaborate with each other, in the Cluster architecture and components section. When you’re using kubectl commands, a YAML specification, or another way to invoke an API call, the API server creates a Pod definition and the scheduler identifies the available node to place the new Pod on. The scheduler does two things: filtering and scoring. The filtering step finds a set of available candidate nodes to place the Pod, and the scoring step ranks the most fitting Pod placement.
The API server then passes that information to the kubelet agent on the target worker node. The kubelet then creates the Pod on the node and instructs the container runtime engine to deploy the application image. Once it’s done, the kubelet communicates the status back to the API server, which then updates the data in the etcd store, and the user will be notified that the Pod has been created.
This mechanism is repeated every time we perform a task and talk to the Kubernetes cluster, either by using kubectl commands, deploying a YAML definition file, or using other ways to trigger a REST API call through the API server.
The following diagram shows the process that we just described:
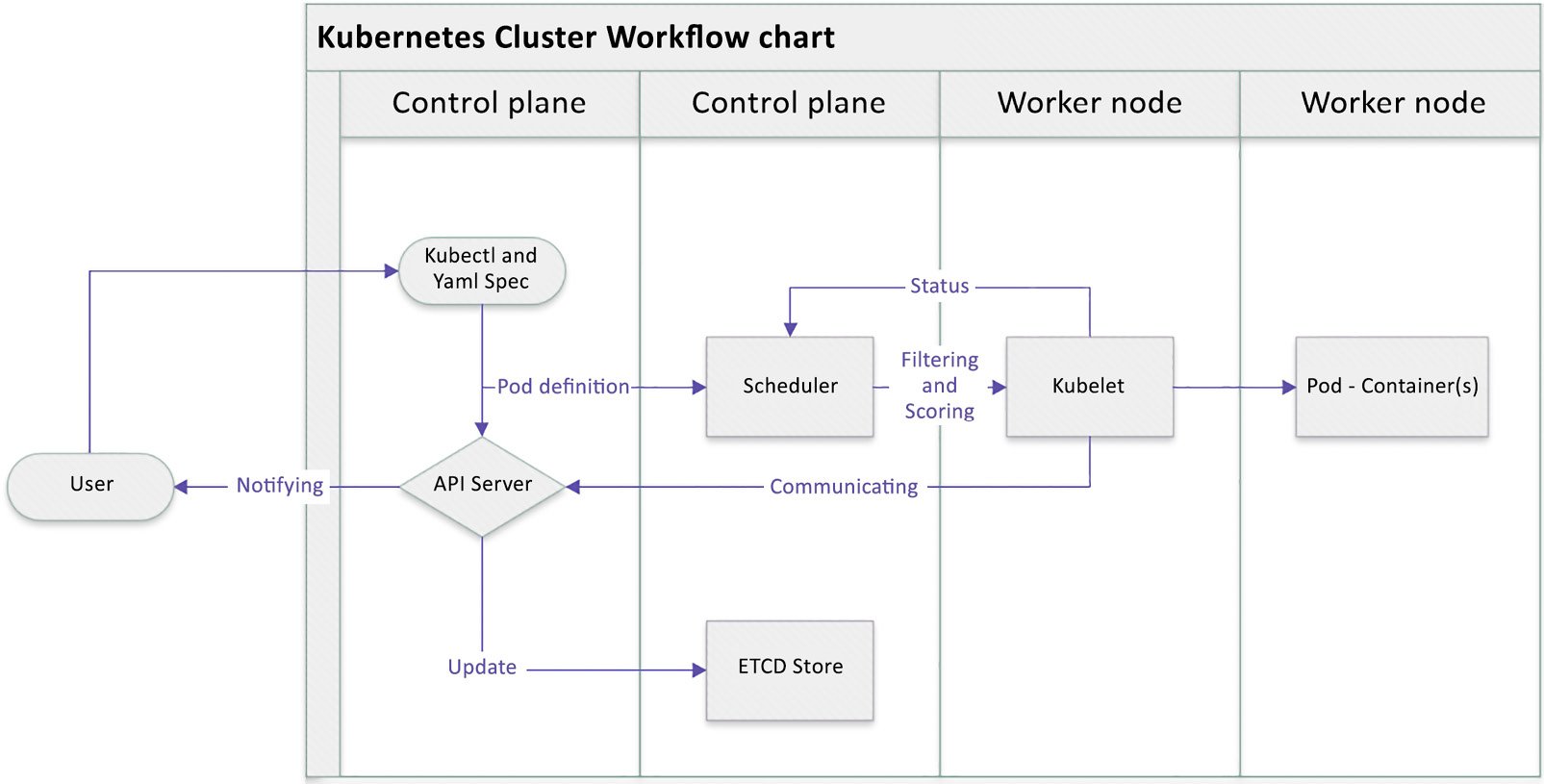
Figure 1.5 – Kubernetes cluster basic workflow
Knowing the basic Kubernetes workflow will help you understand how Kubernetes cluster components collaborate with each other and lay the foundation for learning about the Kubernetes plugin model and API objects.
Kubernetes plugin model
One of the most important reasons for Kubernetes to dominate the market and become the new normal of the cloud-native ecosystem is that it is flexible, highly configurable, and has a highly extensible architecture. Kubernetes is highly configurable and extensible on the following layers:
- Container runtime: The container runtime is the lowest software virtualization layer running containers. This layer supports a variety of runtimes in the market thanks to the Container Runtime Interface (CRI) plugin. The CRI contains a set of protocol buffers, specifications, a gRPC API, libraries, and tools. We’ll cover how to cooperate with different runtimes when provisioning the Kubernetes cluster in Chapter 2, Installing and Configuring Kubernetes Clusters.
- Networking: The networking layer of Kubernetes is defined by kubenet or the Container Network Interface (CNI), which is responsible for configuring network interfaces for Linux containers, in our case, mostly Kubernetes Pods. The CNI is actually a Cloud Native Computing Foundation (CNCF) project that includes CNI specifications, plugins, and libraries. We’ll cover more details about Kubernetes networking in Chapter 7, Demystifying Kubernetes Networking.
- Storage: The storage layer of Kubernetes was one of the most challenging parts at a time prior to Container Storage Interface (CSI) being introduced as a standard interface for exposing block and file storage systems. The storage volumes are managed by storage drivers tailored by storage vendors, this part previously being part of Kubernetes source code. The CSI compatible volume drivers are served for users to attach or mount the CSI volumes to the Pods running in the Kubernetes cluster. We’ll cover storage management in Kubernetes in Chapter 5, Demystifying Kubernetes Storage.
They can be easily laid out as shown in the following diagram:
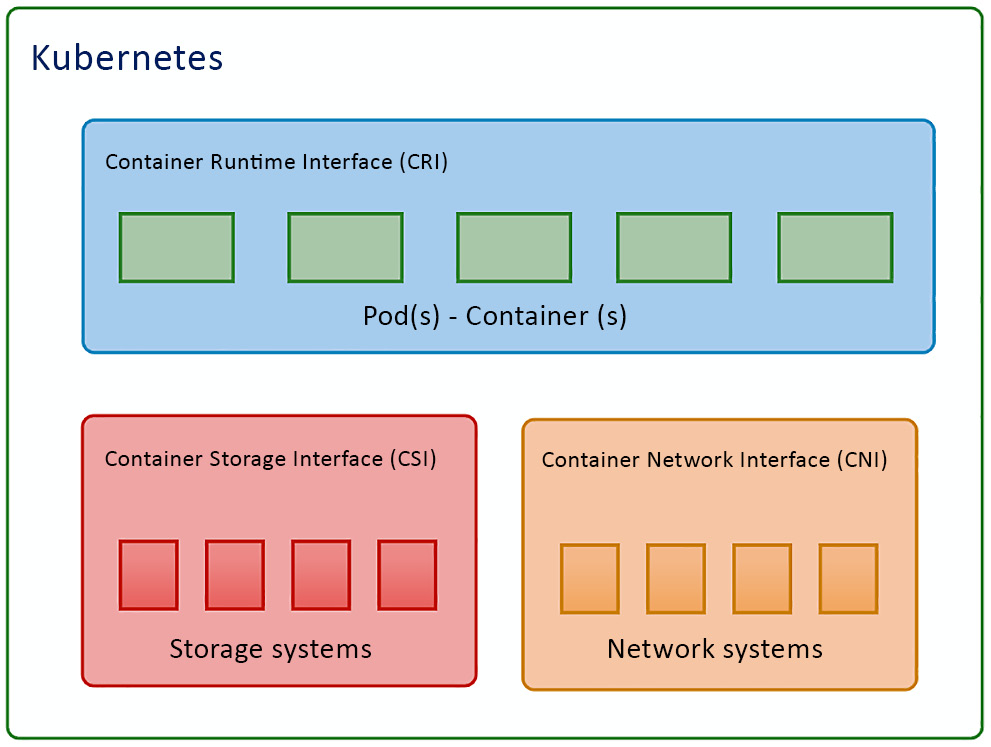
Figure 1.6 – Kubernetes plugin model
A good understanding of the Kubernetes plugin model will help you not only in your daily work as a Kubernetes administrator but also to lay the foundation to help you quickly learn about Kubernetes ecosystems and cloud-native community standards.










