






















































Cyber anonymity
We have discussed how our privacy can be compromised and different levels of privacy.
Cyber anonymity is the state of being unknown. With cyber anonymity, the activities performed in cyberspace will remain, but the state will be unknown. As an example, if an attacker performs an attack anonymously, the attack will still be effective but the attacker’s identity will be unknown. Being completely anonymous is a complex process as there are multiple layers of collecting information, as explained earlier.
If we look at the same set of layers that we discussed, to be anonymous in cyberspace, we need to concentrate on each layer. The main idea here is for the attacker to eliminate all traces of themselves as if even a single amount of information is left, they can be identified. That’s how many anonymous groups have been traced, in some cases after many years of research.
There was one case related to the world-famous Silk Road, an anonymous marketplace on the dark web mostly selling drugs to over 100,000 buyers around the world. Later, the Federal Bureau of Investigation (FBI) seized the site. With the site, the United States government seized over 1 billion US dollars' worth of Bitcoin connected to Silk Road. Even though the main actors behind Silk Road were arrested, the administrators of the site started Silk Road 2, but that was also seized by the US government. However, the site was completely anonymous for a few years until the FBI traced and shut it down. According to the media, the infamous Dread Pirate Roberts, the pseudonym of Ross Ulbricht, the founder of Silk Road, was taken down because of a misconfigured server. This server was used to maintain the cyber anonymity of Silk Road, but due to a single misconfiguration, it uncovered the real IPs of some requests instead of them being anonymous. As a result, the FBI was able to track down the communication and traced the perpetrator using the IP.
This is a classic example to illustrate how even though efforts were made to remain anonymous on all layers, a small mistake revealed their whereabouts. This is why it is stated that cyber anonymity is a complicated process that involves various technologies. Also, it requires concentrating on all the layers to be completely anonymous. There are many common technologies, including Virtual Private Networks (VPNs), proxy servers, censorship circumvention tools, and chain proxies, that help with maintaining cyber anonymity, which will be discussed in upcoming chapters.
Typically, all operating systems, applications, and appliances are designed to keep different types of information in the form of logs to maintain accountability and to be able to help with troubleshooting. This information can be volatile or static. Volatile information will be available until the next reboot or shutdown of the system in memory. Forensic and memory-capturing tools can be used to dump volatile data, which can then be analyzed to find out specific information.
Static data can be found in temporary files, registries, log files, and other locations, depending on the operating system or application. Some information that is available is created by the user activity and some is created as a part of the system process.
If you need to maintain complete anonymity, this information is useful as you need to minimize or prevent the footprints created in different layers. To overcome this challenge, the most used technique is using live boot systems. Most Linux systems provide the flexibility of running a live operating system, using CDs/DVDs, live boot USB drives, or virtual systems directly connected to an ISO file. Some operating systems that have the live boot option available are as follows:
- Kali Linux live boot – penetration testing environment
- Parrot Security or Parrot OS live boot – security testing
- Gentoo – based on FreeBSD
- Predator OS
- Knoppix – based on Debian
- PCLinuxOS – based on Mandrake
- Ubuntu – based on Debian
- Kubuntu – KDE Ubuntu version
- Xubuntu – light Ubuntu version that uses an Xfce desktop environment
- Damn Small Linux – Debian (Knoppix remaster)
- Puppy Linux – Barry Kauler wrote almost everything from scratch
- Ultimate Boot CD (UBCD) – diagnostics CD
- openSUSE Live – based on the Jurix distribution
- SystemRescue CD – Linux system on a bootable CD-ROM for repairing your system and your data after a crash
- Feather Linux – Knoppix remaster (based on Debian)
- FreeBSD – derived from BSD
- Fedora – another community-driven Linux distribution
- Linux Mint – an elegant remix based on Ubuntu
- Hiren’s BootCD PE (Preinstallation Environment) – Windows 10-based live CD with a range of free tools
Once you boot from live boot systems, it reduces or prevents creating logs and temporary files on the actual operating system straight away. Once the live boot system is shut down or rebooted, volatile data and static data are created because your activities are completely removed; when you boot next time, it will be a brand-new operating system. If you require, you always have the option to permanently install most of these operating systems.
Whenever you access the internet, DNS information will be cached in the local system until you manually remove it, the Time to Live (TTL) value is reached, or you run an automated tool. When you access any website, the local DNS resolver resolves it and keeps it in the cache until the TTL value becomes 0. When configuring DNS on the domain service provider’s portal or DNS server, usually, the TTL values are added.
As an example, by using the nslookup command, we can check the TTL value.
Let’s use nslookup on microsoft.com:
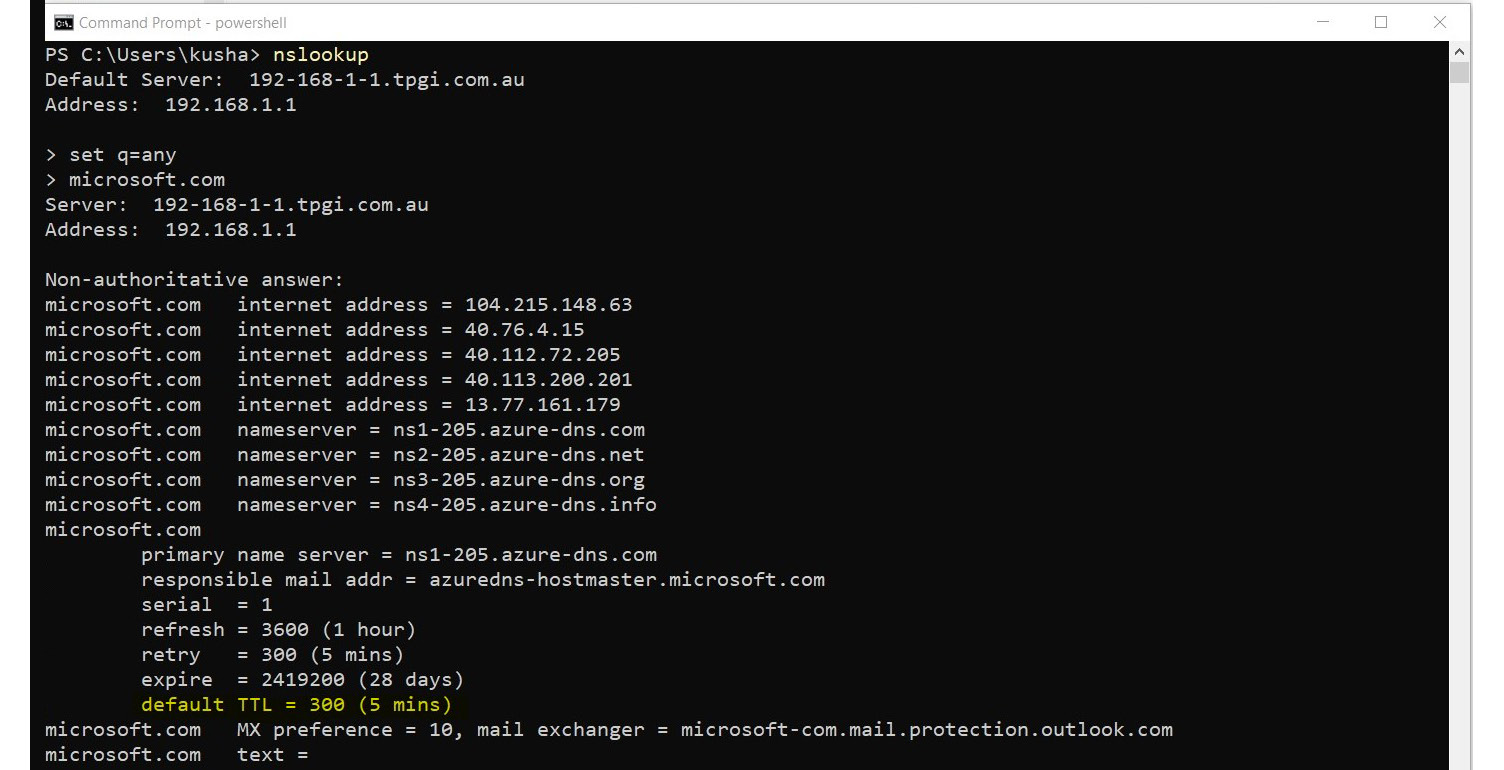
Figure 1.10 – DNS information retrieval with nslookup
This shows the TTL value of microsoft.com is 300 seconds/5 minutes.
If we access the Microsoft website, this DNS entry will be cached in the local cache.
We can check this by executing ipconfig /displaydns on Windows Command Prompt.
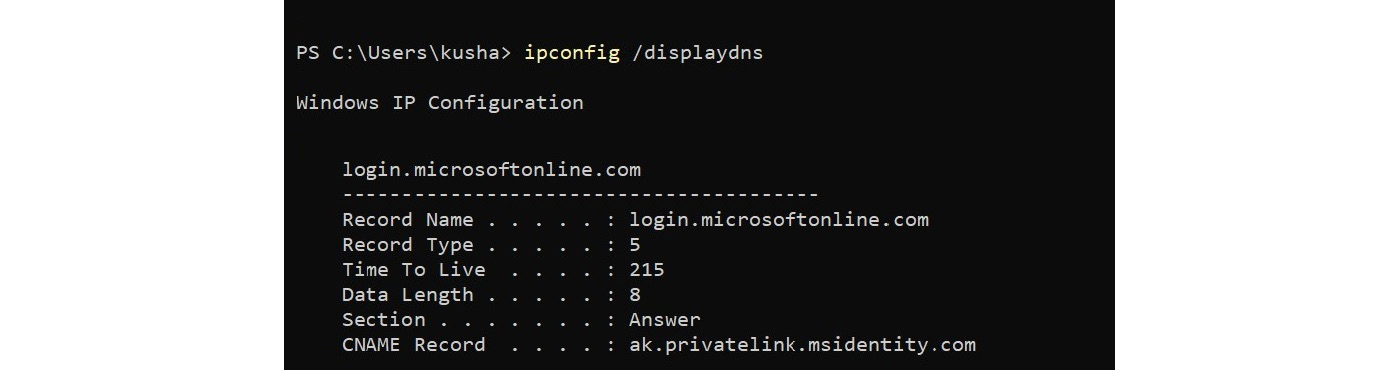
Figure 1.11 – Information retrieved by ipconfig/displaydns
If you are using PowerShell, you can use the Get-DnsClientCache cmdlet to get a similar result.
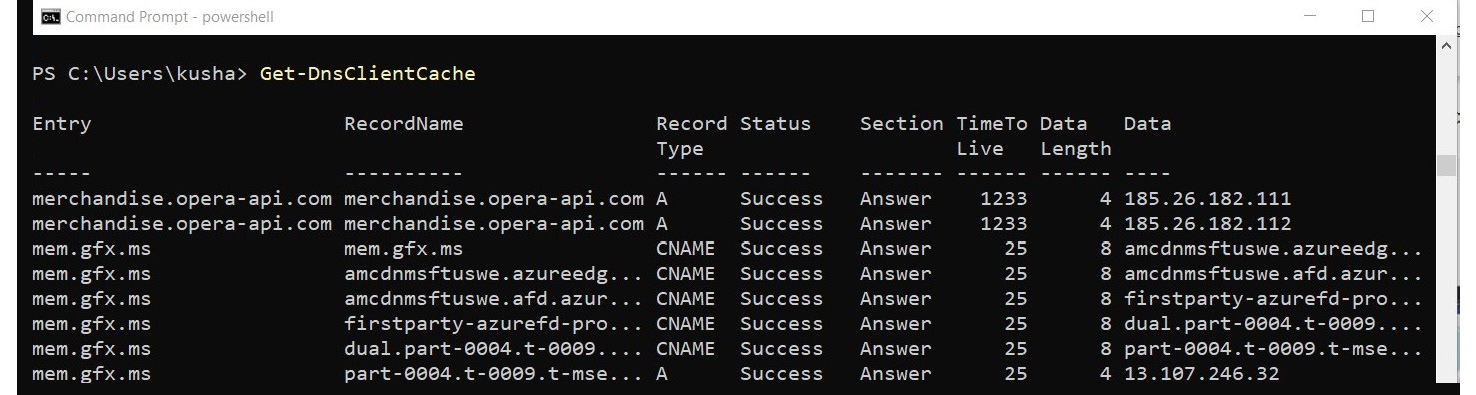
Figure 1.12 – Information retrieved by Get-DnsClientCache
This information is categorized as volatile information. However, until your next reboot or shutdown, these entries will be there if the TTL value has not reached 0.
If you execute the preceding command a few times, with some intervals, you will realize every time you run it, the TTL value of the result is always less than the previous TTL value. When the TTL value becomes 0, the entry will be automatically removed. This is how DNS has been designed, to provide optimum performance during the runtime and when you change the DNS entry. That’s the reason why when you change the DNS entry, it can take up to 48 hours to completely replicate the DNS as some clients might still have resolved IPs from DNS entries in their cache.
This is not just the case on the local cache; if you have DNS servers in the infrastructure, these DNS servers also cache the resolved DNS entries for later use.



