






















































Perturbations and image evasion attack techniques
Perturbations are essential to deceiving ML models in evasion attacks. Perturbations are crafted modifications that cause a model to make incorrect predictions when applied to input data. Perturbations are crafted using advanced calculations to make them as imperceptible as possible, and this can make them highly effective in escaping the attention of humans or even AI systems.
This subtle manipulation of data is central to evasion tactics, aiming to either confound the model entirely (untargeted attacks) or misguide it to a specific, erroneous outcome (targeted attacks). The sophistication of these techniques lies in their ability to alter the data imperceptibly to human observers while leading the AI astray—a trait that underscores their potential danger and the necessity for robust defenses.
Generating perturbations relies on the precise calculation of adversarial AI using optimization techniques that involve gradient descent with respect to normal input and is not dissimilar to the use of gradient descent in neural networks, as we discussed in Chapter 1. Perturbations are calculated with precision by fine-tuning norms, which are important parameters to create adversarial samples that meet the evasion and undetectability criteria. Norms are mathematical measures to quantify the following:
- The size of perturbation, in other words, the features to alter (L1 norm)
- Its closeness – or Euclidean distance – to the original sample (L2 norm)
- The maximum change to any feature in the data (infinity norm, or L∞)
By fine-tuning these norms, we craft changes that are subtle enough to remain undetected by the human eye and significant enough to mislead the model.
Different algorithms and techniques have been developed to perform this task, and each brings its unique approach and complexity. The effect of these techniques may differ depending on the type of the network (e.g., CNN or RNN) and its complexity and attackers will have to experiment with them
In the next few sections, we will delve into the best-known techniques, including the Fast Gradient Sign Method (FGSM), the Basic Iterative Method (BIM), the Projected Gradient Descent (PGD), the Carlini and Wagner (C&W) attack, and the Jacobian-based Saliency Map Attack (JSMA).
These methods vary in intent and suitability, from FGSM’s broad and rapid approach to PGD’s careful, multi-step optimization and JSMA’s precise targeting. The C&W attack, in particular, is noted for its effectiveness against models equipped with defensive strategies. This is not an exhaustive list of techniques but represents a good sample of the approaches an attacker may use to stage an evasion attack.
By understanding these techniques, we also understand the spectrum of challenges we may encounter when defending against evasion attacks.
We will use our ImRecS sample to describe evasion attacks using a couple of attack scenarios.
Evasion attack scenarios
ImRecS has decided to move away from their own CIFAR-10 CNN and adopt a pretrained ResNet50. This is to allow handling images of higher resolution and future flexibility.
The CTO of ImRecS has blogged about the transition as a sign of their team adopting better technologies. This is picked by a group of adversaries that has been planning to evade ImRecS’s notice.
The adversaries will aim to find perturbations in two attack scenarios:
- Untargeted evasion: The attackers can see a fast and easy way to evade the detection of planes
- Targeted evasion: The attackers are seeking a more sophisticated evasion so that planes are misclassified to birds, to avoid raising suspicion
The attackers experiment with three different images (plane1.jpg, plane2.jpg, and plane3.jpg), shown in the following figure, classified by ResNet50 as 404 (airliner), 908 (wing), and 404 (airliner), respectively:

Figure 7.1 – Test images for evasion attacks
We will start with the simplest one, FGSM.
One-step perturbation with FGSM
FGSM is a foundational technique in adversarial ML. It is a white-box attack, meaning the attacker has access to the model architecture and weights. FGSM works by using the gradients of the neural network to create an adversarial example.
It does it in the opposite direction of the usual gradient descent of a neural network. It perturbs an image by adjusting each pixel in the direction that increases the loss with respect to the target label. For an input image, FGSM adds or subtracts a small error to each pixel in the direction of the gradient, increasing the classification loss.
FGSM is quick and efficient, making it accessible to entry-level attackers but also suitable for testing model robustness against adversarial examples in scenarios where computational resources or time are limited.
This provides a unique opportunity for attackers to utilize ResNet50 and stage evasion attacks against ImRecS’s prediction API.
Attack example
Assume that you are the attacker and have decided to use ART to try out the FGSM attack using Keras with the TensorFlow backend. Once you have created and tested perturbations locally, you will try them against the ImRecS service.
You can create your own adversarial FSGM lab by following these steps.
First, ensure you have the necessary packages installed:
pip install tensorflow keras art
Now, let’s implement FGSM with the following code in a Jupyter notebook. The code illustrates how to do a simple untargeted attack (i.e., any incorrect classification) and demonstrates the basic workflow ART uses to stage evasion attacks with various techniques.
The workflow for any evasion attack in ART is similar:
- We load the target or shadow models in black-box attacks. In this case, we know the target uses ResNet and will use a copy directly using the built-in Keras function:
from tensorflow.keras.applications.resnet_v2 import ResNet50V2 # Load a pre-trained ResNet50 model trained on ImageNet model = ResNet50V2(weights='imagenet')
- Create an ART classifier wrapper for the model:
from art.estimators.classification import KerasClassifier # create an classifier from the model and constrain input ranges to range for image values i.e 0..255 # use_logits=false to denote a model using probabilities for its output and is the default value. You can specify True if the target model outputs raw logits. classifier = KerasClassifier(model=model, clip_values=(0, 255), use_logits=False)
- Use an ART attack object –
FastGradientMethodin our case – and create perturbations. The object will apply the technique and its math transparently, shielding you from complicated details. The following code shows you how that is done for an untargeted attack:from art.attacks.evasion import FastGradientMethod # Craft adversarial examples using FGSM def fgsm_attack(model, sample, epsilon = 0.01): fgsm = FastGradientMethod(estimator=classifier, eps=epsilon) # Generate the adversarial example x_adv = fgsm.generate(x=sample) adv_img = show_adversarial_images(sample,x_adv) return x_adv, adv_img
The code will use
FastGradientMethodto create an FSGM attack with the estimator and a configurableepsilonvalue to return an adversarial image. Theepsilonvalue determines the magnitude of the perturbation; it needs to be small enough to keep the modifications imperceptible, but this will not always be possible.We can display the original image, the perturbation, and the adversarial image using a helper function:
def show_adversarial_images(sample, x_adv): # Calculate the perturbation perturbation = x_adv - sample # Scaling perturbation for visualization perturbation_display = perturbation / (2 * np.max(np.abs(perturbation))) + 0.5 perturbation_img = keras_image.array_to_img(perturbation_display[0]) original_img = keras_image.array_to_img(sample[0]) adv_img = keras_image.array_to_img(x_adv[0]) # Show images side by side show_images([original_img, perturbation_img, adv_img], ['Original Image', 'Perturbation', 'Adversarial Image']) print('prediction for original image: \n',predict(sample)) print('prediction for adversarial image: \n',predict(x_adv)) return adv_imgNote the
predictmethod is a utility function in the notebook to call the model’spredictfunction and format the response. - Test against the target model and fine-tune the parameters until you get it right. You most likely will. In our case, we will use a preloaded plane image:
plane1 = load_preprocess_show('../images/plane1.png') _,_ = fgsm_attack(model,plane1)
The following screenshot shows the results of our FSGM attack, which successfully misclassifies an airliner as a warplane with the minimum of effort by adding an imperceptible perturbation to the original image:
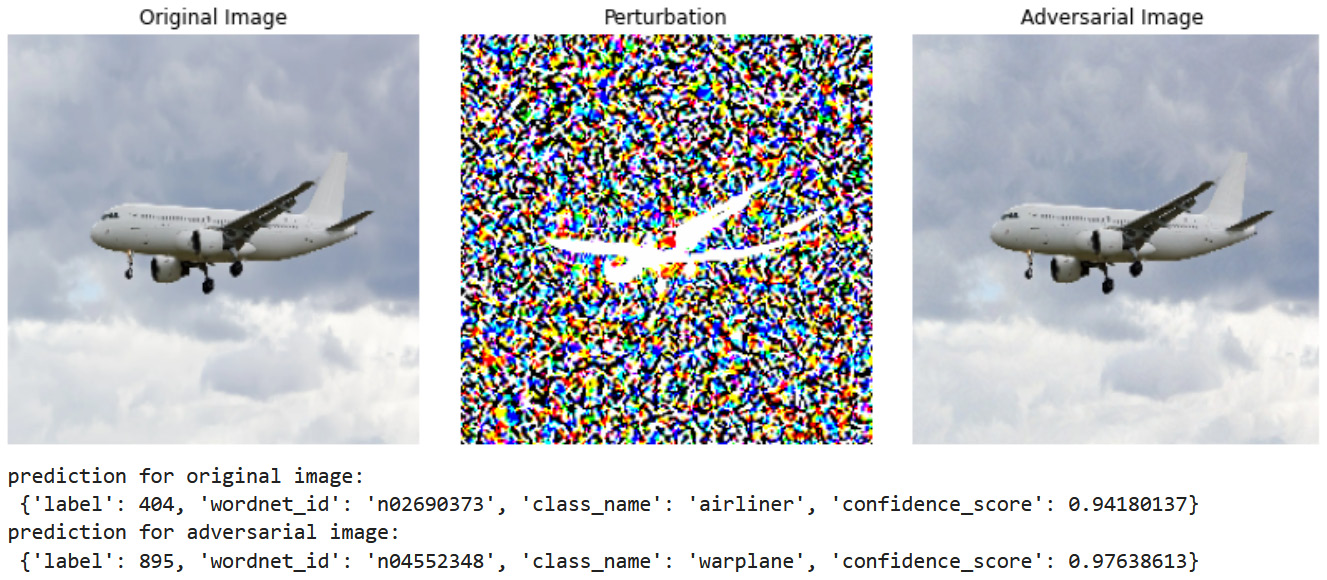
Figure 7.2 – FSGM attack successfully misclassifying an airliner
Repeating the attacks for the two other images proves unsuccessful. Although the perturbation misclassifies the images, the misclassification is to airship, which is not useful for the attacker. The method produces more convincing misclassifications, but only if we increase epsilon dramatically, which makes the image visibly change.
Similarly, targeted attacks with FSGM fail. The targeted attack is almost identical to the previous one, except that we define the target label, one-hot-encode it, pass it to our attack object, and set the targeted parameter to True:
from art.attacks.evasion import FastGradientMethod # Craft adversarial examples using FGSM for targeted attacks def fgsm_targeted_attack(sample, target_label=None, classifier=classifier, epsilon=0.01): target_one_hot = np.zeros((1, 1000)) target_one_hot[0, target_label] = 1 fgsm = FastGradientMethod(estimator=classifier, eps=epsilon, targeted=True, y=target_one_hot) # Generate the adversarial example x_adv = fgsm.generate(x=sample, y=target_class) adv_img = show_adversarial_images(sample, x_adv) return x_adv, adv_img
We can now test it as follows:
_, _ = fgsm_targeted_attack(plane1, target_class=8)
Here, 8 is the ImageNet label for a hen. We test it against a number of bird labels:
bird_labels = [8, 10, 11, 12, 13] # Imagenets Class IDs for Hen, Brambling, Goldfinch, Junco, Indigo bunting
The targeted attack is unsuccessful, with the first and third planes being classified correctly or misclassified as happened with the untargeted attack. The second image is misclassified in an untargeted way as shovel, alp, and, a few times, ptarmigan.
The FGSM method is an important concept to understand in the field of adversarial ML, as it showcases the vulnerability of neural networks to seemingly minor perturbations. It is, however, a relatively simple one-step technique. The following section will discuss more advanced multi-step techniques to generate perturbations.
Basic Iterative Method (BIM)
BIM is an enhancement over single-step adversarial attack methods such as FGSM. While FGSM makes a single large update to the input image, BIM applies multiple small updates, iteratively nudging the input image toward the adversarial target. This iterative nature often results in more effective and subtle perturbations.
Attack example
The BIM implementation in ART uses a PGD attack under the hood by setting the step size and number of iterations accordingly. However, PGD offers more flexibility and robustness compared to BIM. We will cover PGD later in this chapter. For now, here is an example of how you’d use BIM in ART:
from art.attacks.evasion import BasicIterativeMethod def bmi_attack(sample, wrapper=classifier, epsilon=0.01, eps_step=0.001, max_iter=10, batch_size=32): bmi = BasicIterativeMethod(estimator=wrapper, eps=epsilon, eps_step=0.001, max_iter=10,batch_size=32) # Generate the adversarial example x_adv = bmi.generate(x=sample) adv_img = show_adversarial_images(sample,x_adv) return x_adv, adv_img _,_ = bmi_attack(plane1)
The results are similar to FSGM but an attacker has the option to fine-tune the other parameters.
Note
We have covered BIM here for completeness. In attack scenarios, attackers will use PGD.
One of the challenges in adapting FSGM and BIM to complex real-world scenarios is that both treat all input data uniformly. In the next section, we will explore a different technique that focuses on changing the most important data points.
Jacobian-based Saliency Map Attack (JSMA)
While FGSM and BIM represent broad strokes in the adversarial landscape, JSMA is a fine brush that paints targeted and precise adversarial examples. Unlike FGSM, which perturbs all pixels uniformly, or BIM, which iteratively applies perturbations, JSMA computes a saliency map for a sample, which identifies data points whose modification would have the most significant impact on the output classification. The technique can be applied to images, text, and tabular data. For images, for instance, it changes a select few pixels with the most significant impact on the output. This calculation is based on the gradients of the output with respect to the input image and will maximally affect the class scores according to the Jacobian matrix of the model. This selective approach often results in minimal and less detectable modifications, making JSMA particularly suitable for targeted attacks. It is a computationally intensive technique because it involves calculating the forward derivative of the model to construct a saliency map, from which the most influential pixels are identified for modification.
Attack example
Implementing JSMA with ART is straightforward using the attack = SaliencyMapMethod
(classifier=classifier, theta=0.1, gamma=0.1) statement. The classifier parameter is an ART wrapper to the target or shadow model. theta is the amount of perturbation introduced in each step, and gamma is the maximum fraction affected (e.g., pixels), expressed as a value between 0 and 1. You can also specify an optional batch size, which we have not used in our sample, and being an iterative method. This example looks similar to the previous one, except for the creation of the attack. We exploit this ART encapsulation by creating a general attack method and passing the attack-specific parameters. The generic method looks as follows:
def attack(sample, attack_class, wrapper=classifier, **kwargs): attack_instance = attack_class(wrapper, **kwargs) x_adv = attack_instance.generate(x=sample) adv_img = show_adversarial_images(sample, x_adv) return x_adv, adv_img
We can then use it as follows, passing the sample and the attack type:
from art.attacks.evasion import SaliencyMapMethod _, _ = attack(plane1, SaliencyMapMethod, theta=0.1, gamma=1, batch_size=1)
This helps reuse the code and focus on the attack-specific parameters rather than boilerplate code.
We can go a step further and create a single attack method to cater for our different attack methods, for both untargeted and targeted attacks, as shown in the following code:
import inspect # Unified attack function for both targeted and untargeted attacks def has_targeted_parameter(attack_class): signature = inspect.signature(attack_class) return 'targeted' in signature.parameters def attack(sample, attack_class,target_label=None, wrapper=classifier, **kwargs): if target_label is not None: target_one_hot = np.zeros((1, 1000)) target_one_hot[0, target_label] = 1 if has_targeted_parameter(attack_class): print(f"creating an instance)" attack_instance = attack_class(wrapper, targeted=True, **kwargs) prin else: attack_instance = attack_class(wrapper, **kwargs) x_adv = attack_instance.generate(x=sample, y=target_one_hot) else: attack_instance = attack_class(wrapper, **kwargs) x_adv = attack_instance.generate(x=sample) adv_img = show_adversarial_images(sample, x_adv) return x_adv, adv_img
The code checks whether a target_label has been supplied and, if so, it instantiates the attack classes for a targeted attack; otherwise, it proceeds as before. The JSMA implementation has built-in support for targeted attacks and it does not require the targeted=True parameter, which when passed throws an error. We use inspect to bypass this limitation and provide a single implementation.
The attack takes time to complete but is successful on all three images in untargeted attacks and targeted attacks. In targeted attacks, it succeeds in the first three attacks but produces slightly different bird labels for the last two; planes are misclassified as house_finch and junco, instead of junco and indigo_bunting. But this is still a success for our attack scenario.
Note
Despite its computational demands, JSMA is a highly effective evasion technique. JSMA and FSGM have also been used against deep reinforcement learning models. You can find out more details in the research paper Adversarial Attacks and Defense in Deep Reinforcement Learning (DRL)-Based Traffic Signal Controllers by Ammar Haydari, Michael Zhang, and Chen-Nee Chuah, 2021, at https://par.nsf.gov/servlets/purl/10349108.
JSMA, like FGSM and BIM, relies predominately on gradients. In the next section, we will see a more sophisticated approach.
Carlini and Wagner (C&W) attack
The C&W attack is a sophisticated and powerful targeted adversarial technique that stands out due to its efficacy and the difficulty in defending against it. Unlike the earlier mentioned methods, such as FGSM, BIM, and JSMA, which predominantly rely on manipulating the gradients of the model to generate adversarial examples, the C&W attack takes a different route. It formulates the creation of adversarial examples as an optimization problem, aiming to find the smallest possible perturbation that can cause a misclassification to a specific target class while also striving to keep the perturbation imperceptible.
The C&W attack differs from FGSM and BIM in that it doesn’t solely depend on the gradient sign but optimizes for the smallest change needed to alter the classification. This results in a more subtle and often more effective perturbation. In contrast to JSMA, which selectively alters a small subset of features, the C&W attack considers the entire image, optimizing the perturbation across all pixels in a way that is tuned to the specific model’s loss landscape.
Attack example
To implement the C&W attack using ART, first ensure you have ART installed
Like the previous examples, ART encapsulates C&W as an evasion attack object, and we can reuse the generic implementation by supplying the appropriate parameters. Because we use different parameters than the defaults, we create a thin wrapper to avoid having to supply the parameter values all the time:
from art.attacks.evasion import CarliniL2Method def cw_attack(sample, wrapper=classifier, confidence=0.1, batch_size=1, learning_rate=0.01, max_iter=10): return attack(sample, CarliniL2Method, confidence=confidence, batch_size=batch_size, learning_rate=learning_rate, max_iter=max_iter)
We can now call the attack as follows:
_,_ = cw_attack(plane1)
Adjusting confidence affects how noticeable and robust the adversarial example is, with higher values increasing both the effect and detectability. learning_rate controls the speed and precision of the optimization, where a higher rate can lead to quicker but potentially less accurate results, and a lower rate improves fine-tuning at the cost of speed. Finally, max_iter sets the limit on iterations, with more iterations allowing for more detailed adjustments but taking longer, and fewer iterations speeding up the attack but possibly reducing its effectiveness. Balancing these parameters can take a lot of experimentation.
The C&W attack is a sophisticated attack method that is designed to bypass defenses using its optimization approach. It is interesting to inspect the quality of perturbations both targeted and across the image, as shown in the following figure:

Figure 7.3 – C&W-generated perturbation
However, the method is quite computationally intensive. It takes longer to run out of all of the attacks we have used so far, taking 30 minutes per attack on a powerful workstation (48-core CPU, 128 GB RAM, NVIDIA RTX-4090 GPU with 24 GB VRAM).
The following section will look at the PGD attack. This advanced attack method is less computationally intensive and can be used for both untargeted and targeted methods and has become a benchmark in evaluating adversarial robustness.
Projected Gradient Descent (PGD)
PGD is one of the most popular and effective methods for generating adversarial examples. It is an iterative attack that is widely used due to its effectiveness against various ML models. Unlike one-step attacks such as FGSM, which apply a single large update to the input, PGD applies multiple smaller updates, refining the perturbation at each step. Compared to BIM, it offers more flexibility and robustness as it includes options for random initialization, different norms (e.g., L1, L2, and L∞), and adaptive step sizes, allowing for a broader range of attack strategies and more effective adversarial example generation.
This process allows PGD to find adversarial examples that are closer to the original input in the input space while still misleading the model. Compared to the JSMA and C&W attacks, PGD is faster and more flexible, although it may require more fine-tuning than JSMA to succeed, and unlike C&W, it may not find the minimum perturbation required to induce a misclassification.
Attack example
We can use our attack function to implement a PGD attack, passing the Projected
GradientDescent class and relevant parameters.
Like in FSGM, the eps parameter determines the maximum perturbation allowed, influencing how noticeable and effective the adversarial changes are. eps_step controls the step size in each iteration, where smaller steps lead to more precise but slower adjustments. The max_iter parameter sets the number of iterations the attack runs, affecting the refinement and strength of the adversarial example; more iterations allow for thorough optimization, while fewer iterations quicken the process but may lessen the attack’s impact. The default options create visibly distorted images and as a result, we use different defaults. To avoid retyping the parameters, like with C&W, we create a thin wrapper as follows:
from art.attacks.evasion import ProjectedGradientDescent for bird_label in bird_labels: for plane in planes: _,_ = attack(plane, ProjectedGradientDescent, target_label=bird_label, eps=0.03, eps_step=0.001, max_iter=10, batch_size=1)
We can now reuse it in our attacks or model evaluations with one line:
pgd_attack(plane1)
We have covered the basic types of evasion techniques and the approaches they follow. Using ART and the consolidated function we developed, it is straightforward to evaluate models for adversarial robustness against evasion attacks.
ART is constantly expanding its catalog of evasion attacks, incorporating attacks published in new research. For more information, see the ART documentation on evasion attacks at https://adversarial-robustness-toolbox.readthedocs.io/en/latest/modules/attacks/evasion.html.
Because of the encapsulation ART offers, you can extend the generic function used in this book to incorporate new evasion attacks relevant to your use cases.
Adversarial patches – bridging digital and physical evasion techniques
Adversarial patches represent a paradigm shift in the domain of adversarial AI. Unlike methods such as FGSM, BIM, C&W, or PGD, which typically introduce fine-tuned, often imperceptible perturbations, adversarial patches are localized alterations designed to be superimposed onto a segment of the input, such as part of an image.
Attack scenarios
Traditional evasion techniques often require access to the model’s gradient information to craft perturbations that are spread across the input, making them inherently suited for digital attacks. Adversarial patches, conversely, do not need such detailed knowledge and can be crafted to be highly visible yet still effective, making them uniquely suited to physical-world applications.
For example, a physical adversarial patch could be placed on a road sign to mislead an autonomous vehicle’s vision system—a direct and tangible interaction with the AI. Alternatively, by creating a patch attached to a car, an attacker can bypass CCTV object detection. This type of attack leverages the physical attributes of the patch, such as shape, color, and pattern, to exploit the model’s vulnerabilities.
Adversarial patches can be used in the digital domain, too. In digital attacks, adversarial patches are inserted into digital images or video frames before being fed into the AI system, causing similar misclassifications as they would in the real world.
In our case, our attack scenario will try and use a patch to misclassify a car as an animal, evading CCTV object detection.
Attack example
We can generate an adversarial patch using ART. As always, first, ensure you have ART installed:
pip install adversarial-robustness-toolbox
Then, we can proceed with the following code in a Jupyter notebook:
from art.attacks.evasion import AdversarialPatch
import tensorflow as tf
... load a ResNet50v2 and wrap it in an ART classifier called wrapper as before
# Create the adversarial patch attack
ap = AdversarialPatch(classifier=wrapper, rotation_max=22.5, scale_min=0.4, scale_max=scale_max,
learning_rate=learning_rate,
max_iter=500, batch_size=16,
patch_shape=(224, 224, 3))
# load sample image to attack
img = load_preprocess('../images/racing-car.jpg')
# set the target to a tabby cat
target_class = 281 # 'tabby cat' class in ImageNet
y_one_hot = np.zeros(1000)
y_one_hot[target_class] = 1.0
y_target = np.expand_dims(y_one_hot, axis=0) # Shape (1, 1000)
#generate the patch
patch, _ = ap.generate(x=img, y=y_target) The code demonstrates the creation of an adversarial patch using ART’s AdversarialPatch class, applying it to an input image, and then feeding the altered image into a pre-trained model to assess its impact. The attack is successful as it misclassifies the car as siamese_cat or fox_squirrel, which, although not a tabby cat, may meet the attack scenario objectives. Sometimes it misclassifies it as an airliner, but the classification depends on the position of the patch on the image. An attacker knowing where to place the patch would evade object recognition without raising suspicion when viewing predictions.
The next screenshot shows the two images side by side with the patch position causing a fox_squirrel misclassification:

Figure 7.4 – The fox_squirrel misclassification
You can find the full example in the Targeted Adversarial Patch notebook. It showcases the generation of the patch, its application at a specified scale and position, and the subsequent misclassification by the AI model.











