






















































Working with extracts instead of live connections
Nearly all data sources allow the option of either connecting live or extracting the data. A few cloud-based data sources require an extract. Conversely, OLAP data sources cannot be extracted and require live connections.
Extracts extend the way in which Tableau works with data. Consider the following diagram:
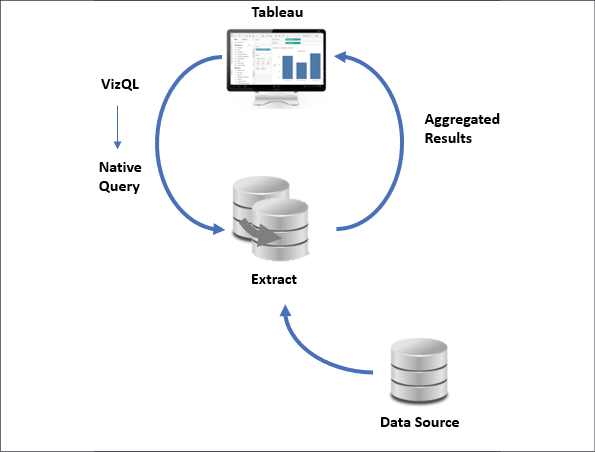
Figure 2.21: Data from the original Data Source is extracted into a self-contained snapshot of the data
When using a live connection, Tableau issues queries directly to the data source (or uses data in the cache, if possible). When you extract the data, Tableau pulls some or all of the data from the original source and stores it in an extract file. Prior to version 10.5, Tableau used a Tableau Data Extract (.tde) file. Starting with version 10.5, Tableau uses Hyper extracts (.hyper) and will convert .tde files to .hyper as you update older workbooks.
The fundamental paradigm of how Tableau works with data does not change, but you'll notice that Tableau is now querying and getting results from the extract. Data can be retrieved from the source again to refresh the extract. Thus, each extract is a snapshot of the data source at the time of the latest refresh. Extracts offer the benefit of being portable and extremely efficient.
Creating extracts
Extracts can be created in multiple ways, as follows:
- Select Extract on the Data Source screen as follows. The Edit... link will allow you to configure the extract:

Figure 2.22: Select either Live or Extract for a connection and configure options for the extract by clicking Edit.
- Select the data source from the Data menu, or right-click the data source on the data pane and select Extract data. You will be given a chance to set configuration options for the extract, as demonstrated in the following screenshot:

Figure 2.23: The Extract data… option
- Developers may create an extract using the Tableau Hyper API. This API allows you to use Python, Java, C++, or C#/.NET to programmatically read and write Hyper extracts. The details of this approach are beyond the scope of this book, but documentation is readily available on Tableau's website at https://help.tableau.com/current/api/hyper_api/en-us/index.html.
- Certain tools, such as
AlteryxorTableau Prep, can output Tableau extracts.
You'll have quite a few options for configuring an extract. To edit these options, select Extract and then Edit… on the Data Source screen or Extract data… from the context menu of a connection in the Data pane. When you configure an extract, you will be prompted to select certain options, as shown here:
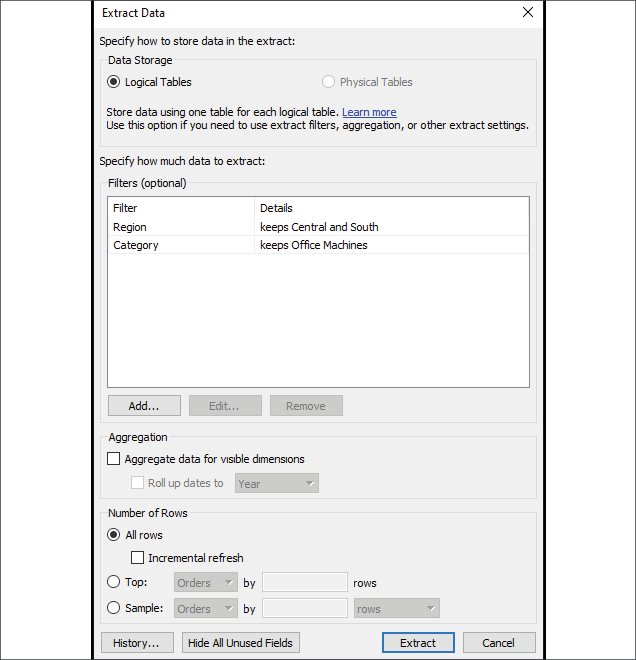
Figure 2.24: The Extract Data dialog gives quite a few options for how to configure the extract
You have a great deal of control when configuring an extract. Here are the various options, and the impact your choices will make on performance and flexibility:
- Depending on the data source and object model you've created, you may select between Logical Tables and Physical Tables. We'll explore the details in Chapter 13, Understanding the Tableau Data Model, Joins, and Blends.
- You may optionally add extract Filters, which limit the extract to a subset of the original source. In this example only, records where Region is Central or South and where Category is Office Machines will be included in the extract.
- You may aggregate an extract by checking the box. This means that data will be rolled up to the level of visible dimensions and, optionally, to a specified date level, such as year or month.
Visible fields are those that are shown in the data pane. You may hide a field from the Data Source screen or from the data pane by right-clicking a field and selecting Hide. This option will be disabled if the field is used in any view in the workbook.
Hiddenfields are not available to be used in a view.Hiddenfields are not included in an extract as long as they are hidden prior to creating or optimizing the extract.
In the preceding example, if only the Region and Category dimensions were visible, the resulting extract would only contain two rows of data (one row for Central and another for South). Additionally, any measures would be aggregated at the Region/Category level and would be done with respect to the Extract filters. For example, Sales would be rolled up to the sum of sales in Central/Office Machines and South/Office Machines. All measures are aggregated according to their default aggregation.
You may adjust the number of rows in the extract by including all rows or a sampling of the top n rows in the dataset. If you select all rows, you can indicate an incremental refresh. If your source data incrementally adds records, and you have a field such as an identity column or date field that can be used reliably to identify new records as they are added, then an incremental extract can allow you to add those records to the extract without recreating the entire extract. In the preceding example, any new rows where Row ID is higher than the highest value of the previous extract refresh would be included in the next incremental refresh.
Incremental refreshes can be a great way to deal with large volumes of data that grow over time. However, use incremental refreshes with care, because the incremental refresh will only add new rows of data based on the field you specify. You won't get changes to existing rows, nor will rows be removed if they were deleted at the source. You will also miss any new rows if the value for the incremental field is less than the maximum value in the existing extract.
Now that we've considered how to create and configure extracts, let's turn our attention to using them.
Performance
There are two types of extracts in Tableau:
- Tableau Data Extracts (
.tdefiles): prior to Tableau 10.5, these were the only type of extract available. - Hyper (
.hyperfiles) are available in Tableau 10.5 or later.
Depending on scale and volume, both .hyper and .tde extracts may perform faster than most traditional live database connections. For the most part, Tableau will default to creating Hyper extracts. Unless you are using older versions of Tableau, there is little reason to use the older .tde. The incredible performance of Tableau extracts is based on several factors, including the following:
- Hyper extracts make use of a hybrid of OLTP and OLAP models and the engine determines the optimal query. Tableau Data Extracts are columnar and very efficient to query.
- Extracts are structured so they can be loaded quickly into memory without additional processing and moved between memory and disk storage, so the size is not limited to the amount of RAM available, but RAM is efficiently used to boost performance.
- Many calculated fields are materialized in the extract. The pre-calculated value stored in the extract can often be read faster than executing the calculation every time the query is executed. Hyper extracts extend this by potentially materializing many aggregations.
You may choose to use extracts to increase performance over traditional databases. To maximize your performance gain, consider the following actions:
- Prior to creating the extract, hide unused fields. If you have created all desired visualizations, you can click the Hide Unused Fields button on the Extract dialog to hide all fields not used in any view or calculation.
- If possible, use a subset of data from the original source. For example, if you have historical data for the last 10 years but only need the last two years for analysis, then filter the extract by the
Datefield. - Optimize an extract after creating or editing calculated fields or deleting or hiding fields.
- Store extracts on solid-state drives.
Although performance is one major reason to consider using extracts, there are other factors to consider, which we will do next.
Portability and security
Let's say that your data is hosted on a database server accessible only from inside your office network. Normally, you'd have to be onsite or using a VPN to work with the data. Even cloud-based data sources require an internet connection. With an extract, you can take the data with you and work offline.
An extract file contains data extracted from the source. When you save a workbook, you may save it as a Tableau workbook (.twb) file or a Tableau Packaged Workbook (.twbx) file. Let's consider the difference:
- A Tableau workbook (
.twb) contains definitions for all the connections, fields, visualizations, and dashboards, but does not contain any data or external files, such as images. A Tableau workbook can be edited in Tableau Desktop and published to Tableau Server. - A Tableau packaged workbook (
.twbx) contains everything in a (.twb) file but also includes extracts and external files that are packaged together in a single file with the workbook. A packaged workbook using extracts can be opened with Tableau Desktop, Tableau Reader, and published to Tableau Public or Tableau Online.
A packaged workbook file (.twbx) is really just a compressed .zip file. If you rename the extension from .twbx to .zip, you can access the contents as you would any other .zip file.
There are a couple of security considerations to keep in mind when using an extract. First, any security layers that limit which data can be accessed according to the credentials used will not be effective after the extract is created. An extract does not require a username or password. All data in an extract can be read by anyone. Second, any data for visible (non-hidden) fields contained in an extract file (.hyper or .tde), or an extract contained in a packaged workbook (.twbx), can be accessed even if the data is not shown in the visualization. Be very careful to limit access to extracts or packaged workbooks containing sensitive or proprietary data.
When to use an extract
You should consider various factors when determining whether to use an extract. In some cases, you won't have an option (for example, OLAP requires a live connection and some cloud-based data sources require an extract). In other cases, you'll want to evaluate your options.
In general, use an extract when:
- You need better performance than you can get with the live connection.
- You need the data to be portable.
- You need to use functions that are not supported by the database data engine (for example,
MEDIANis not supported with a live connection to SQL Server). - You want to share a packaged workbook. This is especially true if you want to share a packaged workbook with someone who uses the free Tableau Reader, which can only read packaged workbooks with data extracted.
In general, do not use an extract when you have any of the following use cases:
- You have sensitive data that should not be accessible by certain users, or you have no control over who will be able to access the extract. However, you may hide sensitive fields prior to creating the extract, in which case they are no longer part of the extract.
- You need to manage security based on login credentials. (However, if you are using Tableau Server, you may still use extracted connections hosted on Tableau Server that are secured by a login. We'll consider sharing your work with Tableau Server in Chapter 16, Sharing Your Data Story).
- You need to see changes in the source data updated in real time.
- The volume of data makes the time required to build the extract impractical. The number of records that can be extracted in a reasonable amount of time will depend on factors such as the data types of fields, the number of fields, the speed of the data source, and network bandwidth. The Hyper engine typically builds
.hyperextracts much faster than the older.tdefiles were built.
With an understanding of how to create, manage, and use extracts (and when not to use them), we'll turn our attention to various ways of filtering data in Tableau.



















