






















































In this section, we're going to cover the basics of the CSV library and how to work with CSV files. To do this, we will be taking a closer look at the structure of a CSV file; how to install the Text.CSV Haskell library; and how to retrieve data from a CSV file from within Haskell.
Now to begin, we need a CSV file. So, I'm going to tab over to my Haskell environment, which is just a Debian Linux virtual machine running on my computer, and I'm going to go to the website at retrosheet.org. This is a website for baseball statistics, and we are going to use them to demonstrate the CSV library. Find the link for Data Downloads and click Game Logs, as follows:
Now, scroll down just a little bit and you should see game logs for every single season, going all the way back to 1871. For now, I would like to stick with the most recent complete season, which is 2015:
So, go ahead and click the 2015 link. We will have the option to download a ZIP file, so go ahead and click OK. Now, I'm going to tab over to my Terminal:
Let's go into the Downloads folder, and if we hit ls, we see that there's our ZIP file. Let's unzip that file and see what we have. Let's open up GL2015.TXT. This is a CSV file, and will display something like the following:
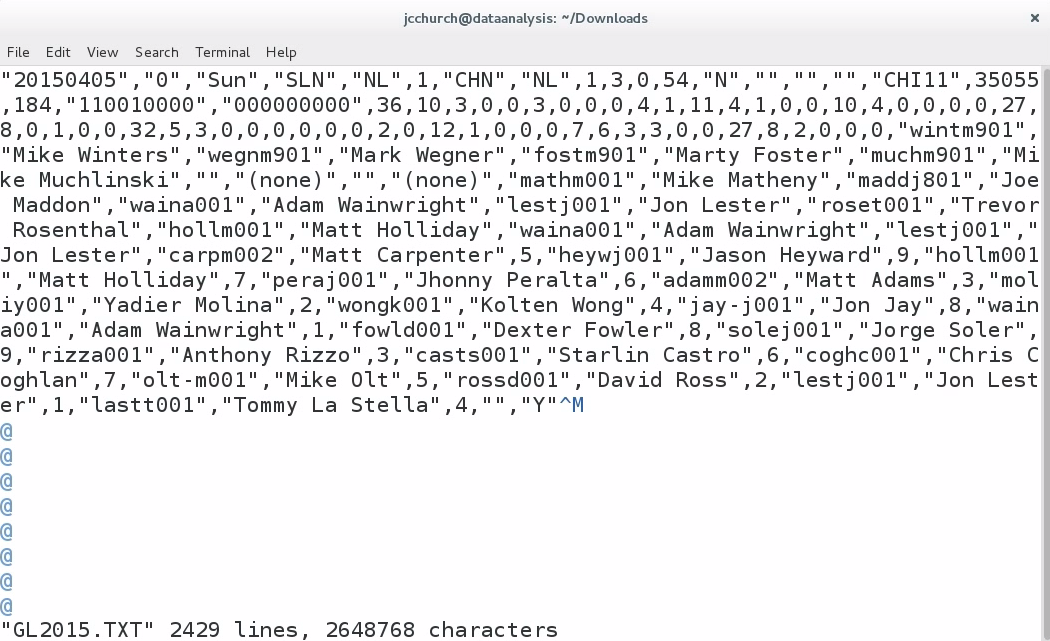
A CSV file is a file of comma-separated values. So, you'll see that we have a file divided up, where each line in this file is a record, and each record represents a single game of baseball in the 2015 season; and inside every single record is a listing of values, separated by a comma. So, the very first game in this dataset is a game between the St. Louis Cardinals—that's SLN—and the Chicago Cubs—that's CHN—and this game took place on March 5th 2015. The final score of this first game was 3-0, and every line in this file is a different game.
Now, CSV isn't a standard, but there are a few properties of a CSV file which I consider to be safe. Consider the following as my suggestions. A CSV file should keep one record per line. The first line should be a description of each column. In a future section, I'm going to tell you that we need to remove the header line; and you'll see that this particular file doesn't have this header line. I still like to see the description line for each column of values. If a field in a record includes a comma, then that field should be surrounded by double quote marks. Now we don't see an example of this—at least, not on this first line—but we do see examples of many values having quote marks surrounding the file, such as the very first value in the file, the date:

In a CSV file, if a field is surrounded by quote marks, then it is optional, unless it has a comma inside that value. While we're here, I would like to make a note of the tenth column in this file, which contains the number 3 on this particular row. This represents the away-team score in every single record of this file. Make a note that our first value on the tenth column is a 3—we're going to come back to that later on.
Our next task is installing the Text.CSV library; we do this using the Cabal tool, which connects with the Hackage repository and downloads the Text.CSV library:
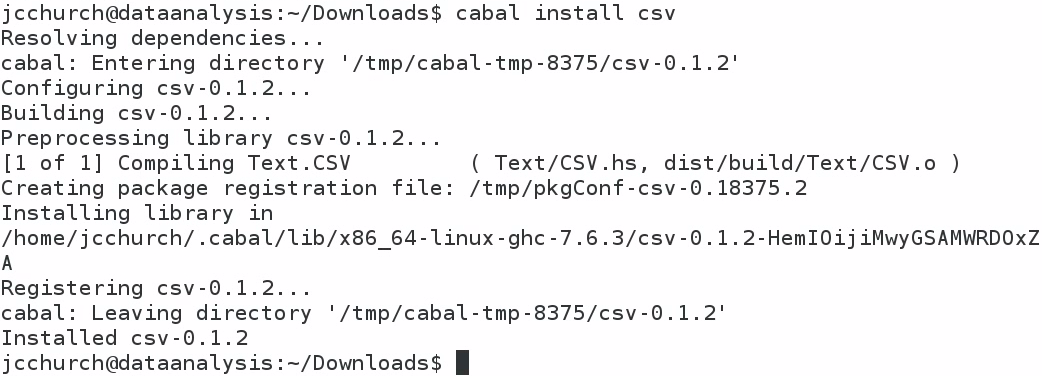
The command that we use to start the install, shown in the first line of the preceding screenshot, is cabal install csv. It takes a moment to download the file, but it should download and install the Text.CSV library in our home folder. Now, let me describe what I currently have in my home folder:
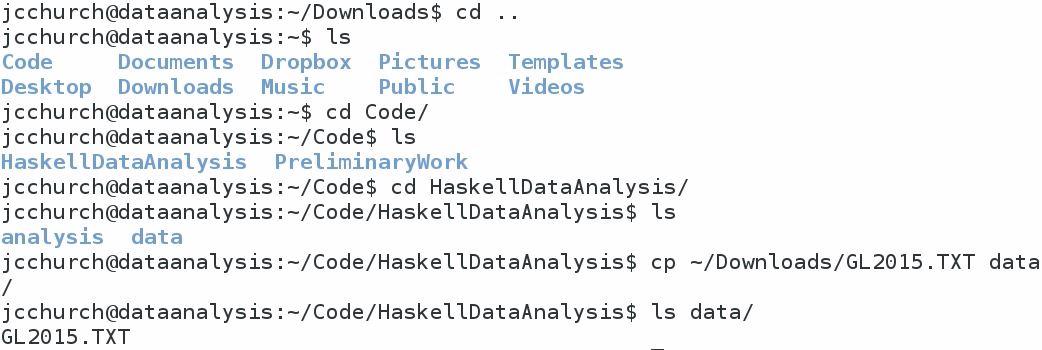
I like to create a directory for my code called Code; and inside here, I have a directory called HaskellDataAnalysis. And inside HaskellDataAnalysis, I have two directories, called analysis and data. In the analysis folder, I would like to store my notebooks. In the data folder, I would like to store my datasets.
That way, I can keep a clear distinction between analysis files and data files. That means I need to move the data file, just downloaded, into my data folder. So, copy GL2015.TXT from our Downloads folder into our data folder. If I do an ls on my data folder, I'll see that I've got my file. Now, I'm going to go into my analysis folder, which currently contains nothing, and I'm going to start the Jupyter Notebook as follows:
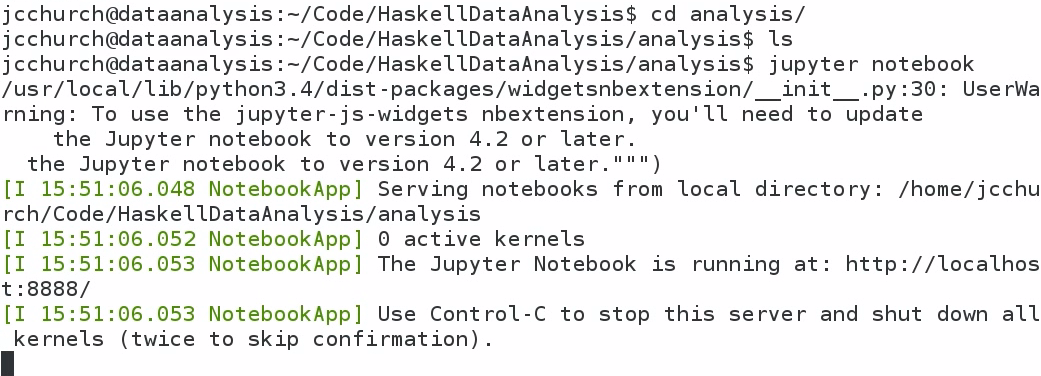
Type in jupyter notebook, which will start a web server on your computer. You can use your web browser in order to interact with Haskell:
The address for the Jupyter Notebook is the localhost, on port 8888. Now I'm going to create a new Haskell notebook. To do this, I click on the New drop-down button on the right side of the screen, and I find Haskell:
Let's begin by renaming our notebook Baseball, because we're going to be looking at baseball statistics:
I need to import the Text.CSV file that we just installed. Now, if your cursor is sitting in a text field and you hit Enter, you'll just be making that text field larger, as shown in the following screenshot. Instead, in order to submit expressions to the Jupyter environment, you have to hit hit Shift + Enter on the keyboard:
So, now that we've imported Text.CSV, let's create our Baseball dataset and parse the dataset. The command for this is parseCSVFromFile, after which we pass in the location of our text file:

Great. If you didn't get a File Not Found error at this point, then that means you have successfully parsed the data from the CSV file. Now, let's explore the type of baseball data. To do this, we enter type and baseball, which is what we just created, and we see that we have either a parsing error or a CSV file:

I've already done this, so I know that there aren't any parsing errors in our CSV file, but if there were, they would be represented by ParseError. So I can promise you that if you've gotten this far, you know that we have a working CSV file. Now, I'll be honest: I don't know why the CSV library does this, but the last element in every CSV data is a single empty list, and I call this empty list the "empty row". What I would like to do is to create a quick function, called noEmptyRows, that removes any row of data that doesn't have at least two pieces of information in it:

So, if we have a parsing error, we're just going to return back an empty list, and if we actually have data, we're going to filter out any row that does not have at least two pieces of information in that row. Now, let's apply our noEmptyRows to our Baseball dataset:
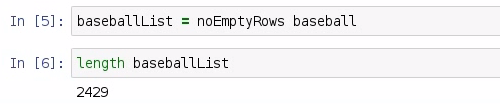
I'm going to call this baseballList. Then we can do a quick check to see the length of the baseballList, and we should have 2,429 rows representing 2,429 games played in the 2015 season.
Now let's look at the type of baseballList, and we see that we have a list of fields:

Now, you may be asking yourself: What's a field? We can explore a field using info, and doing so will bring up a window from the bottom of the screen:
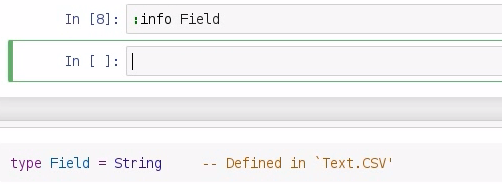
It says type Field = String, and it's defined in this Text.CSV library. So, just remember that a field is just a string.
Now, because every value is a field that is also a string, that means that if I do math on strings, it's going to produce an error message, as shown in the following screenshot:
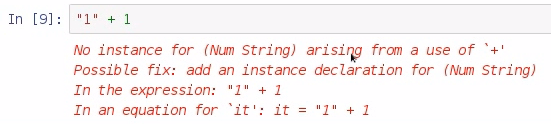
So what I need to do is to parse that information from a string to something else that I can use, such as an int or a double, and I do that with the read command. Let's look at an example:
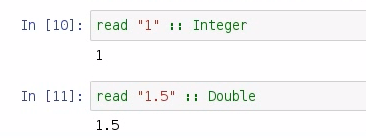
So if I say read "1", it will be parsed as an Integer, or, if I say read "1.5", then it will be parsed as a Double.
So, armed with this knowledge of parsing data from strings, we can parse a whole column of data. Create a readIndex function, and let's say that, in our case, each value is a cell:

So for each cell in our dataset, we're going to pass in our original Baseball dataset—this is an Either; and we're going to say that we need an Int index position in our list; and we are going to return a list of cells. This requires two arguments: the csv, and the index position that we need. And we are going to map over each record, and we're going to read whatever exists at the specified index position. We also need the noEmptyRows function that we discussed earlier.
Now, if you recall earlier, I said that the away-team scores in our CSV file exist on column 10, and because Haskell is a zero-based index file, that means we need to pass in index 9 to our readIndex function:

Here, we parse this list that's returned as a list of integers, and we are returned a listing of every single away-team score in Major League Baseball. The very first element in our list is a 3, because that is the first record of the file.
In this section, you learned about the structure of a CSV file, how to install the Text.CSV library, and how to pull a little bit of information out of that CSV file using the CSV library. In the next section, we're going to discuss how to create our own module for descriptive statistics, and how to write a function for the range of a dataset.




