






















































Modern systems and dealing with complexity
As we saw in the previous section, there are several reasons why software endeavors fail. In this section, we will try to understand how software gets built, what the currently prevailing realities are, and what adjustments we need to make in order to cope.
How software gets built
Building successful software is an iterative process of constantly refining knowledge and expressing it in the form of models. We have attempted to capture the essence of the process at a high level here:
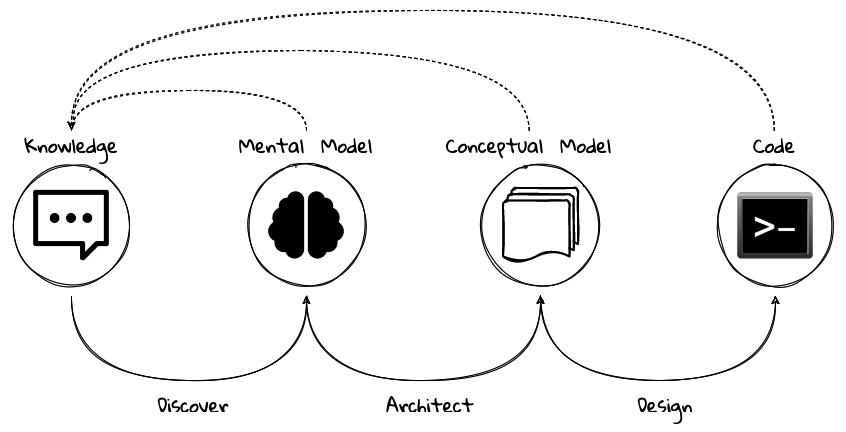
Figure 1.5 – Building software is a continuous refinement of knowledge and models
Before we express a solution in working code, it is necessary to understand what the problem entails, why the problem is important to solve, and finally, how it can be solved. Irrespective of the methodology used (waterfall, agile, and/or anything in between), the process of building software is one where we need to constantly use our knowledge to refine mental/conceptual models to be able to create valuable solutions.
Complexity is inevitable
We find ourselves in the midst of the fourth industrial revolution, where the world is becoming more and more digital—with technology being a significant driver of value for businesses. There have been exponential advances in computing technology, as illustrated by Moore’s law:
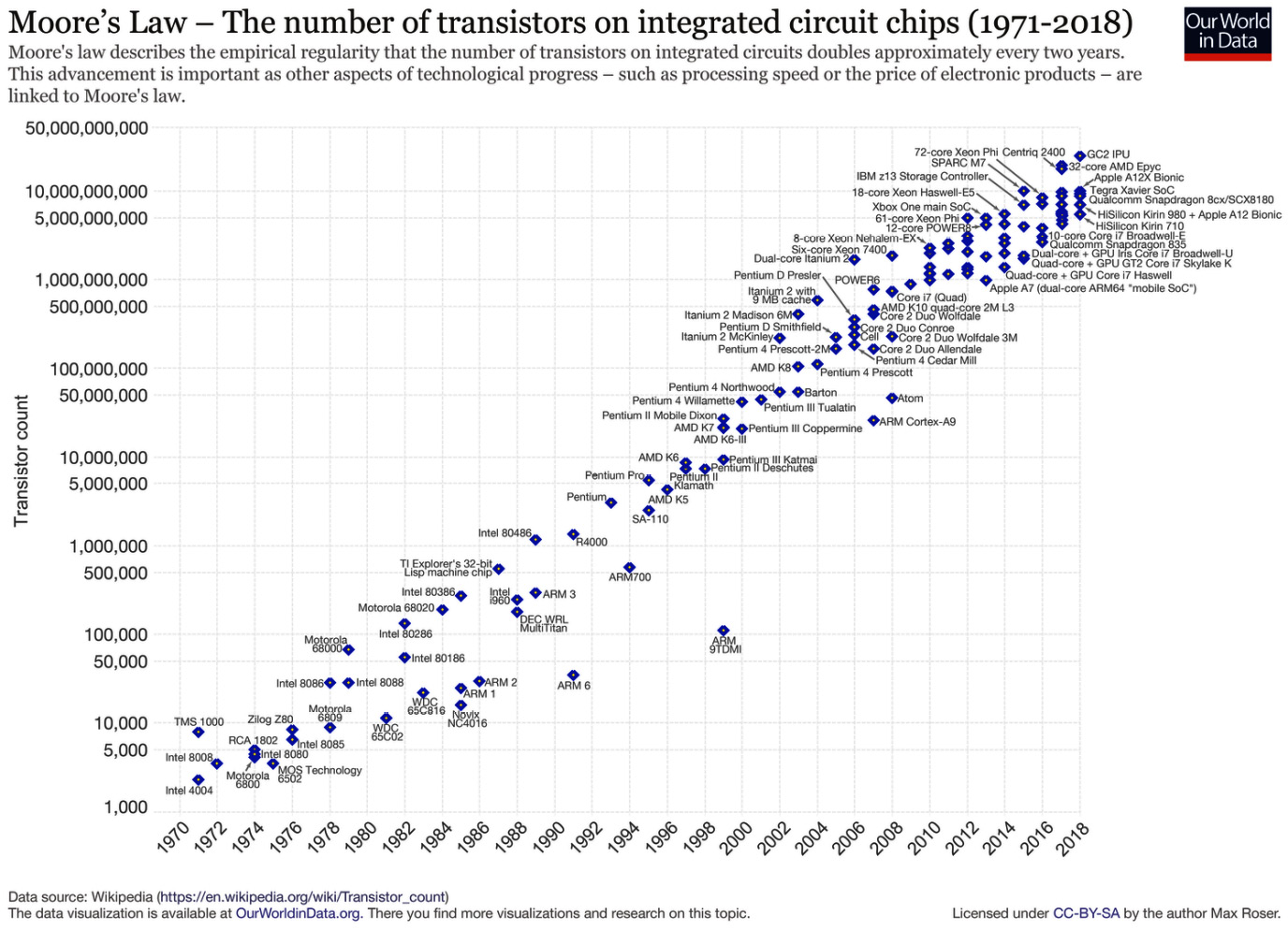
Figure 1.6 – Moore’s law
This has also coincided with the rise of the internet.
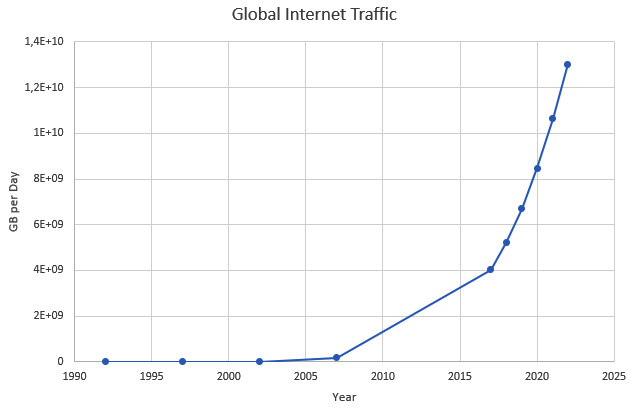
Figure 1.7 – Global internet traffic
This has meant that companies are being required to modernize their software systems much more rapidly than they ever have. Along with all this, the onset of commodity computing services, such as the public cloud, has led to a move away from expensive centralized computing systems to more distributed computing ecosystems. As we attempt to build our most complex solutions, monoliths are being replaced by an environment of distributed, collaborating microservices. Modern philosophies and practices, such as automated testing, architecture fitness functions, continuous integration, continuous delivery, DevOps, security automation, and infrastructure as code, to name a few, are disrupting the way we deliver software solutions.
All these advances introduce their own share of complexity. Instead of attempting to control the amount of complexity, there is a need to embrace and cope with it.
Optimizing the feedback loop
As we enter an age of encountering our most complex business problems, we need to embrace new ways of thinking, development philosophy, and an arsenal of techniques to iteratively evolve mature software solutions that will stand the test of time. We need better ways of communicating, analyzing problems, arriving at a collective understanding, creating and modeling abstractions, and then implementing and enhancing the solution.
To state the obvious—we’re all building software with seemingly brilliant business ideas on one side and our ever-demanding customers on the other, as shown here:
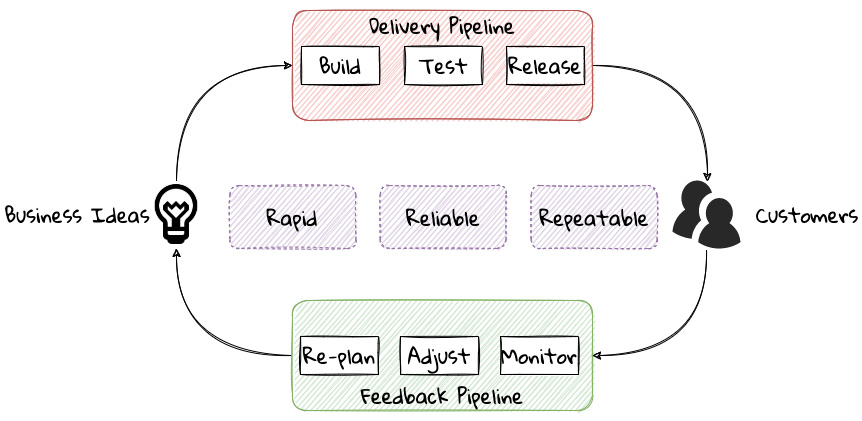
Figure 1.8 – The software delivery continuum
In between, we have two chasms to cross—the delivery pipeline and the feedback pipeline. The delivery pipeline enables us to put software in the hands of our customers, whereas the feedback pipeline allows us to adjust and adapt. As we can see, this is a continuum. If we are to build better, more valuable software, this continuum, this potentially infinite loop, has to be optimized!
To optimize this loop, we need three characteristics to be present: we need to be fast, we need to be reliable, and we need to do this over and over again. In other words, we need to be rapid, reliable, and repeatable—all at the same time! Take any one of these away and it just won’t sustain.
DDD promises to provide answers on how to do this in a systematic manner. In the upcoming section, and indeed the rest of this book, we will examine what DDD is and why it is indispensable when working to provide solutions for non-trivial problems in today’s world of massively distributed teams and applications.


