






















































Advanced process concepts and tools
This marks the beginning of the “advanced” section of this chapter. While you don’t need to master all the concepts in this section to work effectively with Linux processes, they can be extremely helpful. If you have a few extra minutes, we recommend at least familiarizing yourself with each one.
Signals
How does systemctl tell your web server to re-read its configuration files? How can you politely ask a process to shut down cleanly? And how can you kill a malfunctioning process immediately, because it’s bringing your production application to its knees?
In Unix and Linux, all of this is done with signals. Signals are numerical messages that can be sent between programs. They’re a way for processes to communicate with each other and with the operating system, allowing processes to send and receive specific messages.
These messages can be used to communicate a variety of things to a process, for example, indicating that a particular event has happened or that a specific action or response is required.
Practical uses of signals
Let’s look at a few examples of the practical value that the signal mechanism enables. Signals can be used to implement inter-process communication; for example, one process can send a signal to another process indicating that it’s finished with a particular task and that the other process can now start working. This allows processes to coordinate their actions and work together in a smooth and efficient manner, much like execution threads in programming languages (but without the associated memory sharing).
Another common application of process signals is to handle program errors. For example, a process can be designed to catch the SIGSEGV signal, which indicates a segmentation fault. When a process receives this signal, it can trap that signal and then take action to log the error, dump core for debugging purposes, or clean up any resources that were being used before shutting down gracefully.
Process signals can also be used to implement graceful shutdowns. For example, when a system is shutting down, a signal can be sent to all processes to give them a chance to save their state and clean up any resources they were using, via “trapping” signals.
Trapping
Many of the signals can be “trapped” by the processes that receive them: this is essentially the same idea as catching and handling an error in a programming language.
If the receiving process has a handler function for the signal that’s being sent, then that handler function is run. That’s how programs re-read their configuration without restarting, and finish their database writes and close their file handles after receiving the shutdown signal.
The kill command
However, it’s not just processes that communicate via signals: the frighteningly named (and, technically speaking, incorrectly named) kill is a program that allows users to send signals to processes, too.
One of the most common uses of user-sent processes via the kill command is to interrupt a process that is no longer responding. For example, if a process is stuck in an infinite loop, a “kill” signal can be sent to force it to stop.
The kill command allows you to send a signal to a process by specifying its PID. If the process you’d like to terminate has PID 2600, you’d run:
kill 2600
This command would send signal 15 (SIGTERM, or “terminate”) to the process, which would then have a chance to trap the signal and shut down cleanly.
Note
As you can see from the included table of standard signal numbers, the default signal that kill sends is “terminate” (signal 15), not “kill” (SIGKILL is 9). The kill program is not just for killing processes but also for sending any kind of signal. It’s really confusingly named and I’m sorry about that – it’s just one of those idiosyncrasies of Unix and Linux that you’ll get used to.
If you don’t want to send the default signal 15, you can specify the signal you’d like to send with a dash; to send a SIGHUP to the same process, you’d run:
kill –1 2600
Running man signal will give you a list of signals that you can send:
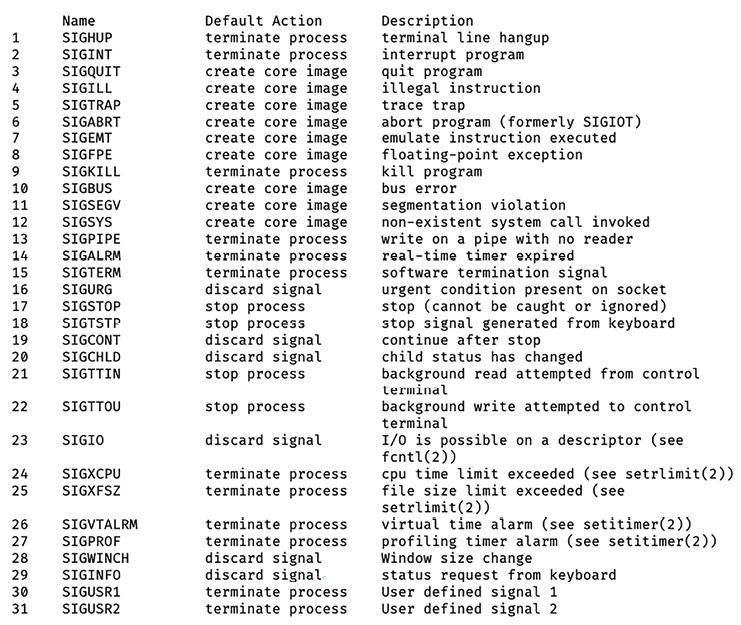
Figure 2.6: Example of output of the man signal command
It pays – sometimes quite literally, in engineering interviews – to be familiar with a few of these:
SIGHUP(1) – “hangup”: interpreted by many applications – for example, nginx – as “re-read your configuration because I’ve made changes to it.”SIGINT(2) – “interrupt”: often interpreted the same asSIGTERM- “please shut down cleanly.”SIGTERM(15) – “terminate”: nicely asks a process to shut down.SIGUSR1(30) andSIGUSR2(31) are sometimes used for application-defined messaging For example, SIGUSR1 asks nginx to re-open the log files it’s writing to, which is useful if you’ve just rotated them.SIGKILL(9) –SIGKILLcannot be trapped and handled by processes. If this signal is sent to a program, the operating system will kill that program immediately. Any cleanup code, like flushing writes or safe shutdown, is not performed, so this is generally a last resort, since it could lead to data corruption.
If you want to explore Linux a bit deeper, feel free to poke around the /proc directory. That’s definitely beyond the basics, but it’s a directory that contains a filesystem subtree for every process, where live information about the processes is looked up as you read those files.
/proc
In practice, this knowledge can come in handy during troubleshooting when you’ve identified a misbehaving (or mysterious) process and want to know exactly what it’s doing in real time.
You can learn a lot about a process by poking around in its /proc subdirectory and casually googling.
Many of the tools we show you in this chapter actually use /proc to gather process information, and only show you a subset of what’s there. If you want to see everything and do the filtering yourself, /proc is the place to look.
lsof – show file handles that a process has open
The lsof command shows all files that a process has opened for reading and writing. This is useful because it only takes one small bug for a program to leak file handles (internal references to files that it has requested access to). This can lead to resource usage issues, file corruption, and a long list of strange behavior.
Thankfully, getting a list of files that a process has open is easy. Just run lsof and pass the –p flag with a PID (you’ll usually have to run this as root). This will return the list of files that the process (in this case, with PID 1589) has open:
~ lsof -p 1589
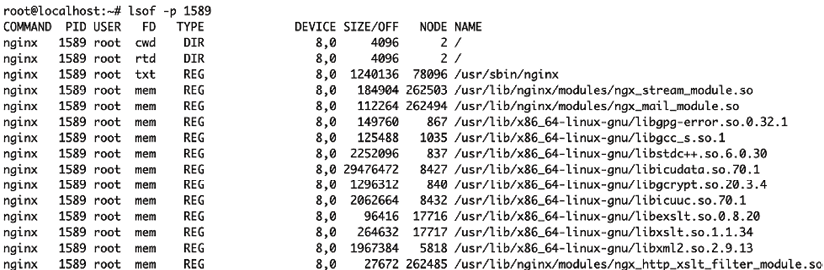
Figure 2.7: Example of list of files opened by the 1589 process using the lsof -p 1589 command
The above is the output for an nginx web server process. The first line shows you the current working directory for the process: in this case, the root directory (/). You can also see that it has file handles open on its own binary (/usr/sbin/nginx) and various libraries in /usr/lib/.
Further down, you might notice a few more interesting filepaths:

Figure 2.8: Further opened files of the 1589 process
This listing includes the log files nginx is writing to, and socket files (Unix, IPv4, and IPv6) that it’s reading and writing to. In Unix and Linux, network sockets are just a special kind of file, which makes it easy to use the same core toolset across a wide variety of use cases – tools that work with files are extremely powerful in an environment where almost everything is represented as a file.
Inheritance
Except for the very first process, init (PID 1), all processes are created by a parent process, which essentially makes a copy of itself and then “forks” (splits) that copy off. When a process is forked, it typically inherits its parent’s permissions, environment variables, and other attributes.
Although this default behavior can be prevented and changed, it’s a bit of a security risk: software that you run manually receives the permissions of your current user (or even root privileges, if you use sudo). All child processes that might be created by that process – for example, during installation, compilation, and so on – inherit those permissions.
Imagine a web server process that was started with root privileges (so it could bind to a network port) and environment variables containing cloud authentication keys (so it could grab data from the cloud). When this main process forks off a child process that needs neither root privileges nor sensitive environment variables, it’s an unnecessary security risk to pass those along to the child. As a result, dropping privileges and clearing environment variables is a common pattern in services spawning child processes.
From a security perspective, it is important to keep this in mind to prevent situations where information such as passwords or access to sensitive files could be leaked. While it is outside the scope of this book to go into details of how to avoid this, it’s important to be aware of this if you’re writing software that’s going to run on Linux systems.


