It is crucial to identify the type of data under analysis. In this section, we are going to learn about different types of data that you can encounter during analysis. Different disciplines store different kinds of data for different purposes. For example, medical researchers store patients' data, universities store students' and teachers' data, and real estate industries storehouse and building datasets. A dataset contains many observations about a particular object. For instance, a dataset about patients in a hospital can contain many observations. A patient can be described by a patient identifier (ID), name, address, weight, date of birth, address, email, and gender. Each of these features that describes a patient is a variable. Each observation can have a specific value for each of these variables. For example, a patient can have the following:
PATIENT_ID = 1001
Name = Yoshmi Mukhiya
Address = Mannsverk 61, 5094, Bergen, Norway
Date of birth = 10th July 2018
Email = yoshmimukhiya@gmail.com
Weight = 10
Gender = Female
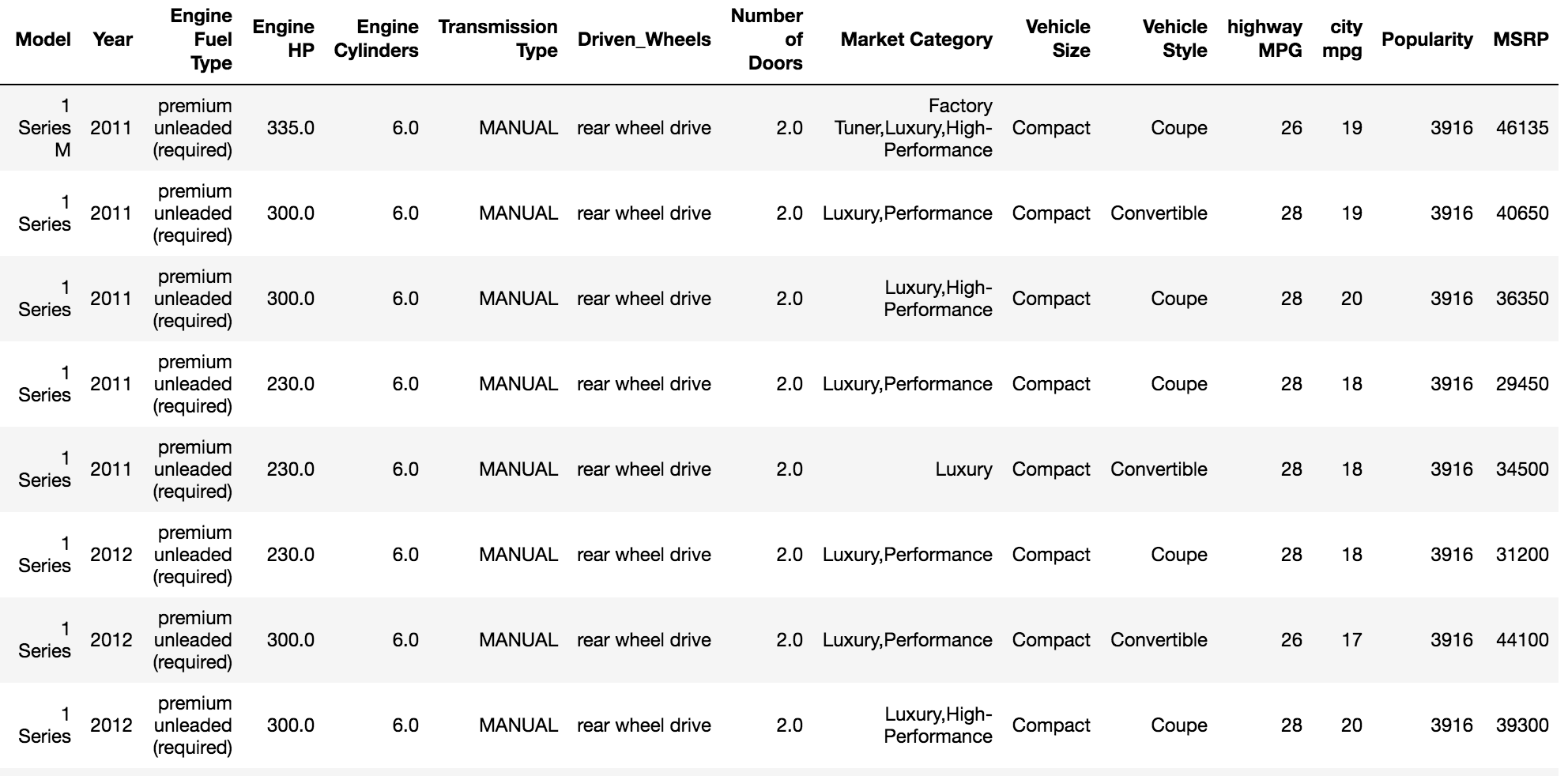
These datasets are stored in hospitals and are presented for analysis. Most of this data is stored in some sort of database management system in tables/schema. An example of a table for storing patient information is shown here:
|
PATIENT_ID |
NAME |
ADDRESS |
DOB |
|
Gender |
WEIGHT |
|
001 |
Suresh Kumar Mukhiya |
Mannsverk, 61 |
30.12.1989 |
skmu@hvl.no |
Male |
68 |
|
002 |
Yoshmi Mukhiya |
Mannsverk 61, 5094, Bergen |
10.07.2018 |
yoshmimukhiya@gmail.com |
Female |
1 |
|
003 |
Anju Mukhiya |
Mannsverk 61, 5094, Bergen |
10.12.1997 |
anjumukhiya@gmail.com |
Female |
24 |
|
004 |
Asha Gaire |
Butwal, Nepal |
30.11.1990 |
aasha.gaire@gmail.com |
Female |
23 |
|
005 |
Ola Nordmann |
Danmark, Sweden |
12.12.1789 |
ola@gmail.com |
Male |
75 |
To summarize the preceding table, there are four observations (001, 002, 003, 004, 005). Each observation describes variables (PatientID, name, address, dob, email, gender, and weight). Most of the dataset broadly falls into two groups—numerical data and categorical data.