






















































Introducing Azure Databricks
With these and other limitations in mind, Databricks was designed. It is a cloud-based platform that uses Apache Spark as a backend and builds on top of it, to add features including the following:
- Highly reliable data pipelines
- Data science at scale
- Simple data lake integration
- Built-in security
- Automatic cluster management
Built as a joint effort by Microsoft and the team that started Apache Spark, Azure Databricks also allows easy integration with other Azure products, such as Blob Storage and SQL databases, alongside AWS services, including S3 buckets. It has a dedicated support team that assists the platform's clients.
Databricks streamlines and simplifies the setup and maintenance of clusters while supporting different languages, such as Scala and Python, making it easy for developers to create ETL pipelines. It also allows data teams to have real-time, cross-functional collaboration thanks to its notebook-like integrated workspace, while keeping a significant amount of backend services managed by Azure Databricks. Notebooks can be used to create jobs that can later be scheduled, meaning that locally developed notebooks can be deployed to production easily. Other features that make Azure Databricks a great tool for any data team include the following:
- A high-speed connection to all Azure resources, such as storage accounts.
- Clusters scale and are terminated automatically according to use.
- The optimization of SQL.
- Integration with BI tools such as Power BI and Tableau.
Let's examine the architecture of Databricks next.
Examining the architecture of Databricks
Each Databricks cluster is a Databricks application composed of a set of pre-configured, VMs running as Azure resources managed as a single group. You can specify the number and type of VMs that it will use while Databricks manages other parameters in the backend. The managed resource group is deployed and populated with a virtual network called VNet, a security group that manages the permissions of the resources, and a storage account that will be used, among other things, as the Databricks filesystem. Once everything is deployed, users can manage these clusters through the Azure Databricks UI. All the metadata used is stored in a geo-replicated and fault-tolerant Azure database. This can all be seen in Figure 1.1:
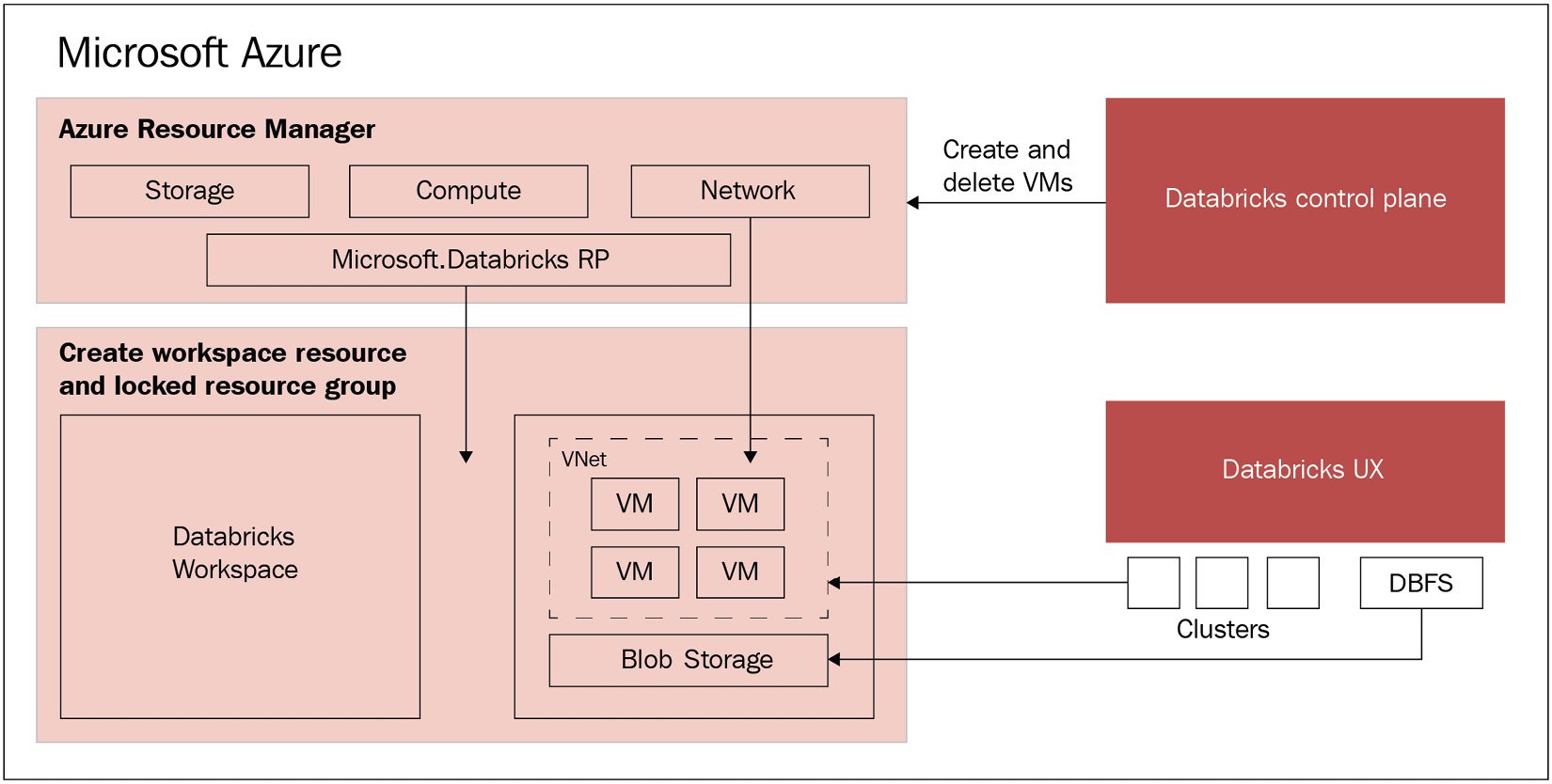
Figure 1.1 – Databricks architecture
The immediate benefit this architecture gives to users is that there is a seamless connection with Azure, allowing them to easily connect Azure Databricks to any resource within the same Azure account and have a centrally managed Databricks from the Azure control center with no additional setup.
As mentioned previously, Azure Databricks is a managed application on the Azure cloud that is composed by a control plane and a data plane. The control plane is on the Azure cloud and hosts services such as cluster management and jobs services. The data plane is a component that includes the aforementioned VNet, NSG, and the storage account that is known as DBFS.
You could also deploy the data plane in a customer-managed VNet to allow data engineering teams to build and secure the network architecture according to their organization policies. This is called VNet injection.
Now that we have seen how everything is laid out under the hood, let's discuss some of the core concepts behind Databricks.


