























































Python for Data Wrangling
There is always a debate on whether to perform the wrangling process using an enterprise tool or by using a programming language and associated frameworks. There are many commercial, enterprise-level tools for data formatting and pre-processing that do not involve much coding on the part of the user. These examples include the following:
General purpose data analysis platforms such as Microsoft Excel (with add-ins)
Statistical discovery package such as JMP (from SAS)
Modeling platforms such as RapidMiner
Analytics platforms from niche players focusing on data wrangling, such as Trifacta, Paxata, and Alteryx
However, programming languages such as Python provide more flexibility, control, and power compared to these off-the-shelf tools.
As the volume, velocity, and variety (the three Vs of big data) of data undergo rapid changes, it is always a good idea to develop and nurture a significant amount of in-house expertise in data wrangling using fundamental programming frameworks so that an organization is not beholden to the whims and fancies of any enterprise platform for as basic a task as data wrangling:
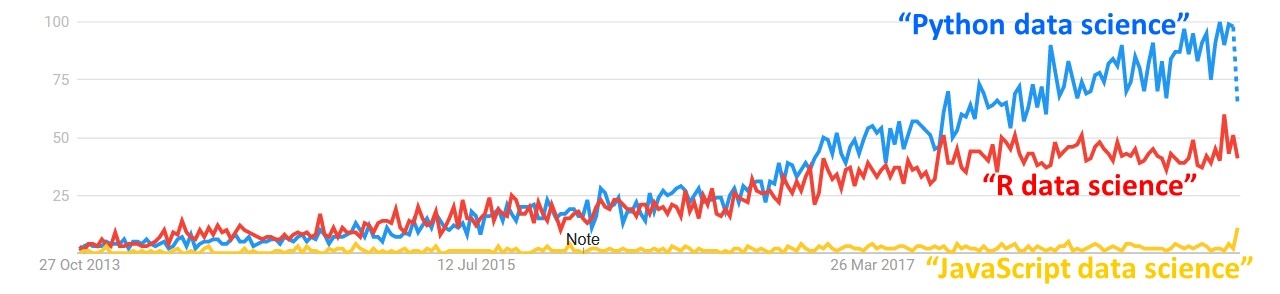
Figure 1.2: Google trend worldwide over the last Five years
A few of the obvious advantages of using an open source, free programming paradigm such as Python for data wrangling are the following:
General purpose open source paradigm putting no restriction on any of the methods you can develop for the specific problem at hand
Great ecosystem of fast, optimized, open source libraries, focused on data analytics
Growing support to connect Python to every conceivable data source type
Easy interface to basic statistical testing and quick visualization libraries to check data quality
Seamless interface of the data wrangling output with advanced machine learning models
Python is the most popular language of choice of machine learning and artificial intelligence these days.


















