























































Training a neural network is a process of coming up with optimal weights for a neural network architecture by repeating the two key steps, forward-propagation and backpropagation with a given learning rate.
In forward-propagation, we apply a set of weights to the input data, pass it through the defined hidden layers, perform the defined nonlinear activation on the hidden layers' output, and then connect the hidden layer to the output layer by multiplying the hidden-layer node values with another set of weights to estimate the output value. Then, we finally calculate the overall loss corresponding to the given set of weights. For the first forward-propagation, the values of the weights are initialized randomly.
In backpropagation, we decrease the loss value (error) by adjusting weights in a direction that reduces the overall loss. Further, the magnitude of the weight update is the gradient times the learning rate.
The process of feedforward propagation and backpropagation is repeated until we achieve as minimal a loss as possible. This implies that, at the end of the training, the neural network has adjusted its weights 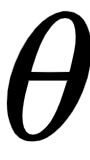 such that it predicts the output that we want it to predict. In the preceding toy example, after training, the updated network will predict a value of 0 as output when {1,1} is fed as input as it is trained to achieve that.
such that it predicts the output that we want it to predict. In the preceding toy example, after training, the updated network will predict a value of 0 as output when {1,1} is fed as input as it is trained to achieve that.























