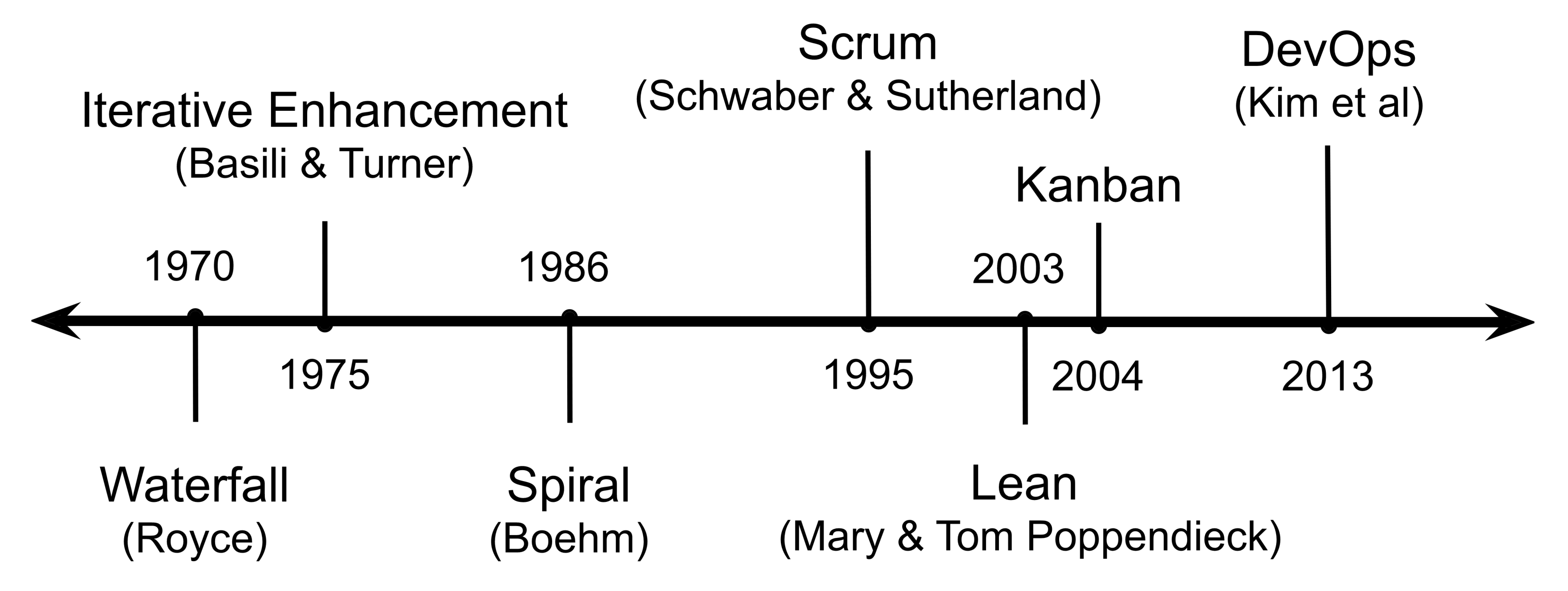
CAMS was originally invented by Damon Edwards and John Willis. Let's explore each one of these terms in a bit more detail.
As with other agile models, corporate culture is an integral part of DevOps methodology. To this end, Edwards and Willis recommend that engineering teams extend the use of practices such as Scrum and Kanban to manage both development and operations. Culture-wise, an extremely important piece of advice that Edwards and Willis offered is that each company must internally evolve its own culture and set of values that suit its unique set of needs instead of simply copying them over from other organizations because they just seem to be working in a particular context. The latter could lead to what is known as the Cargo Cult effect, which eventually creates a toxic work environment that can cause issues with employee retainment.
The second tenet of the CAMS model is automation. As we discussed in a previous section, automation is all about eliminating potential human sources of errors when executing tedious, repetitive tasks. In the context of DevOps, this is usually accomplished by doing the following:
- Deploying a CI/CD system to ensure that all the changes are thoroughly tested before they get pushed to production
- Treating infrastructure as code and managing it as such, that is, storing it in a version control system (VCS), having engineers review and audit infrastructure changes, and finally deploying them via tools such as Chef (https://www.chef.io/), puppet (https://puppet.com/), Ansible (https://www.ansible.com/), and Terraform (https://www.terraform.io/)
The letter M in CAMS stands for measurement. Being able to not only capture service operation metrics but also act on them offers two significant advantages to engineering teams. To begin with, the team can always be apprised of the health of the services they manage. When a service misbehaves, the metrics monitoring system will fire an alert and some of the team members will typically get paged. When this happens, having access to a rich set of metrics allows teams to quickly assess the situation and attempt to remedy any issue.
Of course, monitoring is not the only use case for measuring: services that are managed by DevOps teams are, in most cases, long-lived and therefore bound to evolve or expand over time; it stands to reason that teams will be expected to improve on and optimize the services they manage. High-level performance metrics help identify services with a high load that need to be scaled, while low-level performance metrics will indicate slow code paths that need to be optimized. In both cases, measuring can be used as a feedback loop to the development process to aid teams in deciding what to work on next.
The last letter in the CAMS model stands for sharing. The key ideas here are as follows:
- To promote visibility throughout the organization
- To encourage and facilitate knowledge sharing across teams
Visibility is quite important for all stakeholders. First of all, it allows all the members of the organization to be constantly aware of what other teams are currently working on. Secondly, it offers engineers a clear perspective of how each team's progress is contributing to the long-term strategic goals of the organization. One way to achieve this is by making the team's Kanban board accessible to other teams in the organization.
The model inventors encourage teams to be transparent about their internal processes. By allowing information to flow freely across teams, information silos can be prevented. For instance, senior teams will eventually evolve their own streamlined deployment process. By making this knowledge available to other, less senior, teams, they can directly exploit the learnings of more seasoned teams without having to reinvent the wheel. Apart from this, teams will typically use a set of internal dashboards to monitor the services they manage. There is a definite benefit in making these public to other teams, especially ones that serve as upstream consumers for those services.
At this point, it is important to note that, in many cases, transparency extends beyond the bounds of the company. Lots of companies are making a subset of their ops metrics available to their customers by setting up status pages, while others go even further and publish detailed postmortems on outages.