






















































Managing your data
If you'll be using Elasticsearch as a search engine or a distributed data store, it's important to understand concepts on how Elasticsearch stores and manages your data.
Getting ready
To work with Elasticsearch data, a user must have basic knowledge of data management and JSON (https://en.wikipedia.org/wiki/JSON) data format that is the lingua franca for working with Elasticsearch data and services.
How it works...
Our main data container is called index (plural indices) and it can be considered similar to a database in the traditional SQL world. In an index, the data is grouped in data types called mappings in Elasticsearch. A mapping describes how the records are composed (fields). Every record, that must be stored in Elasticsearch, must be a JSON object.
Natively, Elasticsearch is a schema-less data store: when you put records in it, during insert it processes the records, splits it in fields, and updates the schema to manage the inserted data.
To manage huge volumes of records, Elasticsearch uses the common approach to split an index into multiple parts (shards) so that they can be spread on several nodes. The shard management is transparent to user usage: all common record operations are managed automatically in Elasticsearch's application layer.
Every record is stored in only a shard; the sharding algorithm is based on record ID, so many operations, that require loading and changing of records/objects, can be achieved without hitting all the shards, but only the shard (and their replicas) that contains your object.
The following schema compares Elasticsearch structure with SQL and MongoDB ones:
|
Elasticsearch |
SQL |
MongoDB |
|
Index (indices) |
Database |
Database |
|
Shard |
Shard |
Shard |
|
Mapping/Type |
Table |
Collection |
|
Field |
Column |
Field |
|
Object (JSON object) |
Record (tuples) |
Record (BSON object) |
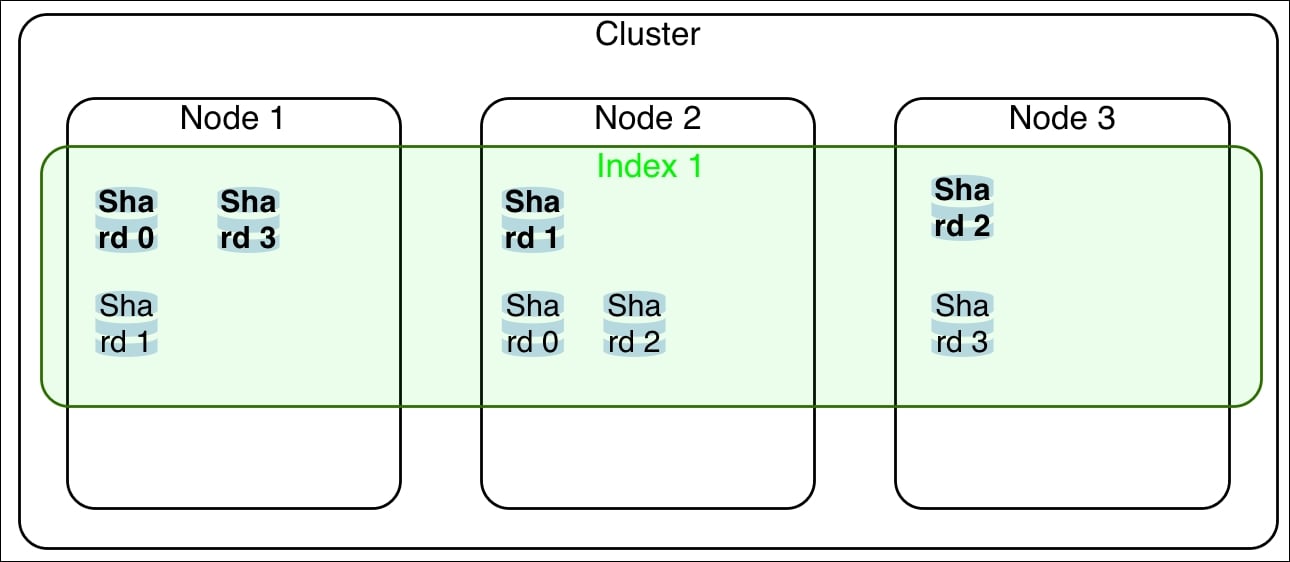
The following screenshot is a conceptual representation of an Elasticsearch cluster with three nodes, one index with four shards and replica set to 1 (primary shards are in bold):
There's more...
Elasticsearch, to ensure safe operations on index/mapping/objects, internally has rigid rules about how to execute operations.
In Elasticsearch the operations are divided into:
Cluster/Index operations: All write actions are locking, first they are applied to the master node and then to the secondary one. The read operations are typically broadcasted to all the nodes.
Document operations: All write actions are locking only for the single hit shard. The read operations are balanced on all the shard replicas.
When a record is saved in Elasticsearch, the destination shard is chosen based on:
The unique identifier (ID) of the record. If the ID is missing, it is auto generated by Elasticsearch
If routing or parent (we'll see it in the parent/child mapping) parameters are defined, the correct shard is chosen by the hash of these parameters
Splitting an index in a shard allows you to store your data in different nodes, because Elasticsearch tries to balance the shard distribution on all the available nodes.
Every shard can contain up to 232 records (about 4.9 Billions), so the real limit to shard size it is the storage size.
Shards contain your data, and during the search process all the shards are used to calculate and retrieve results: so Elasticsearch performance in big data scales horizontally with the number of shards.
All native records operations (that is, index, search, update, and delete) are managed in shards.
The shard management is completely transparent to the user. Only advanced users tend to change the default shard routing and management to cover their custom scenarios, for example, if there is a requirement to put customer data in the same shard to speed up his operations (search/index/analytics).
Best practices
It's best practice not to have too big in size shard (over 10Gb) to avoid poor performance in indexing due to continuous merging and resizing of index segments.
While indexing (a record update is equal to indexing a new element) Lucene, the Elasticsearch engine, writes the indexed documents in blocks (segments/files) to speed up the write process. Over time the small segments are deleted and their sum up is written as a new fragment. Having big fragments due to big shards with a lot of data slows down the indexing performance.
It is not good to over-allocate the number of shards to avoid poor search performance because Elasticsearch works in a map and reduce way due to native distribute search. Shards consist of the worker that does the job of indexing/searching and the master/client nodes do the redux part (collect the results from shards and compute the result to be sent to the user). Having a huge number of empty shards in indices consumes only memory and increases search times due to an overhead on network and results aggregation phases.
See also
You can also view more information about Shard at http://en.wikipedia.org/wiki/Shard_(database_architecture)






