






















































Reverse engineering a dynamic web page
So far, we have tried to scrape data from a web page the same way as introduced in Chapter 2, Scraping the Data. However, it did not work because the data is loaded dynamically with JavaScript. To scrape this data, we need to understand how the web page loads this data, a process known as reverse engineering. Continuing the example from the preceding section, in Firebug, if we click on the Console tab and then perform a search, we will see that an AJAX request is made, as shown in this screenshot:
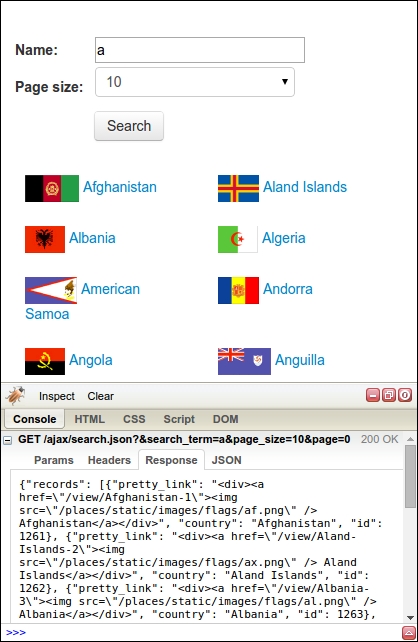
This AJAX data is not only accessible from within the search web page, but can also be downloaded directly, as follows:
>>> html = D('http://example.webscraping.com/ajax/search.json?page=0&page_size=10&search_term=a')The AJAX response returns data in JSON format, which means Python's json module can be used to parse this into a dictionary, as follows:
>>> import json
>>> json.loads(html)
{u'error': u'',
u'num_pages': 22,
...
