






















































ELK Stack installation
A Java runtime is required to run ELK Stack. The latest version of Java is recommended for the installation. At the time of writing this book, the minimum requirement is Java 7. You can use the official Oracle distribution, or an open source distribution, such as OpenJDK.
You can verify the Java installation by running the following command in your shell:
> java -version java version "1.8.0_40" Java(TM) SE Runtime Environment (build 1.8.0_40-b26) Java HotSpot(TM) 64-Bit Server VM (build 25.40-b25, mixed mode)
If you have verified the Java installation in your system, we can proceed with the ELK installation.
Installing Elasticsearch
When installing Elasticsearch during production, you can use the method described below, or the Debian or RPM packages provided on the download page.
Tip
You can download the latest version of Elasticsearch from https://www.elastic.co/downloads/elasticsearch.
curl –O https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-1.5.2.tar.gz
Note
If you don't have cURL, you can use the following command to install it:
sudo apt-get install curl
Then, unpack the zip file on your local filesystem:
tar -zxvf elasticsearch-1.5.2.tar.gz
And then, go to the installation directory:
cd elasticsearch-1.5.2
Note
Elastic, the company behind Elasticsearch, recently launched Elasticsearch 2.0 with some new aggregations, better compression options, simplified query DSL by merging query and filter concepts, and improved performance.
More details can be found in the official documentation:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html.
Running Elasticsearch
In order to run Elasticsearch, execute the following command:
$ bin/elasticsearch
Add the -d flag to run it in the background as a daemon process.
We can test it by running the following command in another terminal window:
curl 'http://localhost:9200/?pretty'
This shows you an output similar to this:
{
"status" : 200,
"name" : "Master",
"cluster_name" : "elasticsearch",
"version" : {
"number" : "1.5.2",
"build_hash" : "c88f77ffc81301dfa9dfd81ca2232f09588bd512",
"build_timestamp" : "2015-05-13T13:05:36Z",
"build_snapshot" : false,
"lucene_version" : "4.10.3"
},
"tagline" : "You Know, for Search"
}We can shut down Elasticsearch through the API as follows:
curl -XPOST 'http://localhost:9200/_shutdown'
Elasticsearch configuration
Elasticsearch configuration files are under the config folder in the Elasticsearch installation directory. The config folder has two files, namely elasticsearch.yml and logging.yml. The former will be used to specify configuration properties of different Elasticsearch modules, such as network address, paths, and so on, while the latter will specify logging-related configurations.
The configuration file is in the YAML format and the following sections are some of the parameters that can be configured.
Network Address
To specify the address where all network-based modules will bind and publish to:
network :
host : 127.0.0.1Paths
To specify paths for data and log files:
path: logs: /var/log/elasticsearch data: /var/data/elasticsearch
The cluster name
To give a name to a production cluster, which is used to discover and auto join nodes:
cluster: name: <NAME OF YOUR CLUSTER>
The node name
To change the default name of each node:
node: name: <NAME OF YOUR NODE>
Elasticsearch plugins
Elasticsearch has a variety of plugins that ease the task of managing indexes, cluster, and so on. Some of the mostly used ones are the Kopf plugin, Marvel, Sense, Shield, and so on, which will be covered in the subsequent chapters. Let's take a look at the Kopf plugin here.
Kopf is a simple web administration tool for Elasticsearch that is written in JavaScript, AngularJS, jQuery and Twitter bootstrap. It offers an easy way of performing common tasks on an Elasticsearch cluster. Not every single API is covered by this plugin, but it does offer a REST client, which allows you to explore the full potential of the Elasticsearch API.
In order to install the elasticsearch-kopf plugin, execute the following command from the Elasticsearch installation directory:
bin/plugin -install lmenezes/elasticsearch-kopf
Now, go to this address to see the interface: http://localhost:9200/_plugin/kopf/.
You can see a page similar to this, which shows Elasticsearch nodes, shards, a number of documents, size, and also enables querying the documents indexed.

Elasticsearch Kopf UI
Installing Logstash
First, download the latest Logstash TAR file from the download page.
Tip
Check for the latest Logstash release version at https://www.elastic.co/downloads/logstash.
curl –O http://download.elastic.co/logstash/logstash/logstash-1.5.0.tar.gz
Then, unpack the GZIP file on your local filesystem:
tar -zxvf logstash-1.5.0.tar.gz
Now, you can run Logstash with a basic configuration.
Running Logstash
Run Logstash using -e flag, followed by the configuration of standard input and output:
cd logstash-1.5.0 bin/logstash -e 'input { stdin { } } output { stdout {} }'
Now, when we type something in the command prompt, we will see its output in Logstash as follows:
hello logstash 2015-05-15T03:34:30.111Z 0.0.0.0 hello logstash
Here, we are running Logstash with the
stdin input and the stdout output as this configuration prints whatever you type in a structured format as the output. The -e flag allows you to quickly test the configuration from the command line.
Now, let's try the codec setting for output for a pretty formatted output. Exit from the running Logstash by issuing a Ctrl + C command, and then we need to restart Logstash with the following command:
bin/logstash -e 'input { stdin { } } output { stdout { codec => rubydebug } }'
Now, enter some more test input:
Hello PacktPub
{
"message" => " Hello PacktPub",
"@timestamp" => "2015-05-20T23:48:05.335Z",
"@version" => "1",
"host" => "packtpub"
}The output that you see is the most common output that we generally see from Logstash:
"message"includes the complete input message or the event line"@timestamp"will include the timestamp of the time when the event was indexed; or if date filter is used, this value can also use one of the fields in the message to get a timestamp specific to the event"host"will generally represent the machine where this event was generated
Logstash with file input
Logstash can be easily configured to read from a log file as input.
For example, to read Apache logs from a file and output to a standard output console, the following configuration will be helpful:
input {
file {
type => "apache"
path => "/user/packtpub/intro-to-elk/elk.log"
}
}
output {
stdout {
codec => rubydebug
}
}Logstash with Elasticsearch output
Logstash can be configured to output all inputs to an Elasticsearch instance. This is the most common scenario in an ELK platform:
bin/logstash -e 'input { stdin { } } output { elasticsearch { host = localhost } }'
Then type 'you know, for logs
You will be able to see indexes in Elasticsearch through http://localhost:9200/_search.
Configuring Logstash
Logstash configuration files are in the JSON format. A Logstash config file has a separate section for each type of plugin that you want to add to the event processing pipeline. For example:
# This is a comment. You should use comments to describe
# parts of your configuration.
input {
...
}
filter {
...
}
output {
...
}Each section contains the configuration options for one or more plugins. If you specify multiple filters, they are applied in the order of their appearance in the configuration file.
When you run logstash, you use the -flag to read configurations from a configuration file or even from a folder containing multiple configuration files for each type of plugin—input, filter, and output:
bin/logstash –f ../conf/logstash.conf
Note
If you want to test your configurations for syntax errors before running them, you can simply check with the following command:
bin/logstash –configtest ../conf/logstash.conf
This command just checks the configuration without running logstash.
Logstash runs on JVM and consumes a hefty amount of resources to do so. Logstash, at times, has significant memory consumption. Obviously, this could be a great challenge when you want to send logs from a small machine without harming application performance.
In order to save resources, you can use the Logstash forwarder (previously known as Lumberjack). The forwarder uses Lumberjack's protocol, enabling you to securely ship compressed logs, thus reducing resource consumption and bandwidth. The sole input is file/s, while the output can be directed to multiple destinations.
Other options do exist as well, to send logs. You can use rsyslog on Linux machines, and there are other agents for Windows machines, such as nxlog and syslog-ng. There is another lightweight tool to ship logs called Log-Courier (https://github.com/driskell/log-courier), which is an enhanced fork of the Logstash forwarder with some improvements.
Installing Logstash forwarder
Download the latest Logstash forwarder release from the download page.
Tip
Check for the latest Logstash forwarder release version at https://www.elastic.co/downloads/logstash.
Prepare a configuration file that contains input plugin details and ssl certificate details to establish a secure communication between your forwarder and indexer servers, and run it using the following command:
Logstash forwarder -config Logstash forwarder.conf
And in Logstash, we can use the Lumberjack plugin to get data from the forwarder:
input {
lumberjack {
# The port to listen on
port => 12345
# The paths to your ssl cert and key
ssl_certificate => "path/to/ssl.crt"
ssl_key => "path/to/ssl.key"
# Set the type of log.
type => "log type"
}Logstash plugins
Some of the most popular Logstash plugins are:
- Input plugin
- Filters plugin
- Output plugin
Input plugin
Some of the most popular Logstash input plugins are:
- file: This streams log events from a file
- redis: This streams events from a redis instance
- stdin: This streams events from standard input
- syslog: This streams syslog messages over the network
- ganglia: This streams ganglia packets over the network via udp
- lumberjack: This receives events using the lumberjack protocol
- eventlog: This receives events from Windows event log
- s3: This streams events from a file from an s3 bucket
- elasticsearch: This reads from the Elasticsearch cluster based on results of a search query
Filters plugin
Some of the most popular Logstash filter plugins are as follows:
- date: This is used to parse date fields from incoming events, and use that as Logstash timestamp fields, which can be later used for analytics
- drop: This drops everything from incoming events that matches the filter condition
- grok: This is the most powerful filter to parse unstructured data from logs or events to a structured format
- multiline: This helps parse multiple lines from a single source as one Logstash event
- dns: This filter will resolve an IP address from any fields specified
- mutate: This helps rename, remove, modify, and replace fields in events
- geoip: This adds geographic information based on IP addresses that are retrieved from
Maxminddatabase
Output plugin
Some of the most popular Logstash output plugins are as follows:
- file: This writes events to a file on disk
- e-mail: This sends an e-mail based on some conditions whenever it receives an output
- elasticsearch: This stores output to the Elasticsearch cluster, the most common and recommended output for Logstash
- stdout: This writes events to standard output
- redis: This writes events to redis queue and is used as a broker for many ELK implementations
- mongodb: This writes output to mongodb
- kafka: This writes events to Kafka topic
Installing Kibana
Before we can install and run Kibana, it has certain prerequisites:
- Elasticsearch should be installed, and its HTTP service should be running on port
9200(default). - Kibana must be configured to use the host and port on which Elasticsearch is running (check out the following Configuring Kibana section).
Download the latest Kibana release from the download page.
Tip
Check for the latest Kibana release version at https://www.elastic.co/downloads/kibana.
curl –O https://download.elastic.co/kibana/kibana/kibana-4.0.2-linux-x64.tar.gz
Then, unpack kibana-4.0.2-linux-x64.tar.gz on your local file system and create a soft link to use a short name.
tar -zxvf kibana-4.0.2-linux-x64.tar.gz ln -s kibana-4.0.2-linux-x64 kibana
Then, you can explore the kibana folder:
cd kibana
Configuring Kibana
The Kibana configuration file is present in the config folder inside the kibana installation:
config/kibana.yml
Following are some of the important configurations for Kibana.
This controls which port to use.
port: 5601.
Property to set the host to bind the server is:
host: "localhost".
Set the elasticsearch_url to point at your Elasticsearch instance, which is localhost by default.
elasticsearch_url: http://localhost:9200
Running Kibana
Start Kibana manually by issuing the following command:
bin/kibana
You can verify the running Kibana instance on port 5601 by placing the following URL in the browser:
http://localhost:5601
This should fire up the Kibana UI for you.

Kibana UI
Note
We need to specify Index name or pattern that has to be used to show data indexed in Elasticsearch. By default, Kibana assumes the default index as logstash-* as it is assuming that data is being fed to Elasticsearch through Logstash. If you have changed the name of the index in Logstash output plugin configuration, then we need to change that accordingly.
Kibana 3 versus Kibana 4
Kibana 4 is a major upgrade over Kibana 3. Kibana 4 offers some advanced tools, which provides more flexibility in visualization and helps us use some of the advanced features of Elasticsearch. Kibana 3 had to be installed on a web server; Kibana 4 is released as a standalone application. Some of the new features in Kibana 4 as compared to Kibana 3 are as follows:
- Search results highlighting
- Shipping with its own web server and using Node.js on the backend
- Advanced aggregation-based analytics features, for example, unique counts, non-date histograms, ranges, and percentiles
Kibana interface
As you saw in the preceding screenshot of the Kibana UI, the Kibana interface consists of four main components—Discover, Visualize, Dashboard, and Settings.
Discover
The Discover page helps to interactively explore the data matching the selected index pattern. This page allows submitting search queries, filtering the search results, and viewing document data. Also, it gives us the count of matching results and statistics related to a field. If the timestamp field is configured in the indexed data, it will also display, by default, a histogram showing distribution of documents over time.

Kibana Discover Page
Visualize
The Visualize page is used to create new visualizations based on different data sources—a new interactive search, a saved search, or an existing saved visualization. Kibana 4 allows you to create the following visualizations in a new visualization wizard:
- Area chart
- Data table
- Line chart
- Markdown widget
- Metric
- Pie chart
- Tile map
- Vertical bar chart
These visualizations can be saved, used individually, or can be used in dashboards.
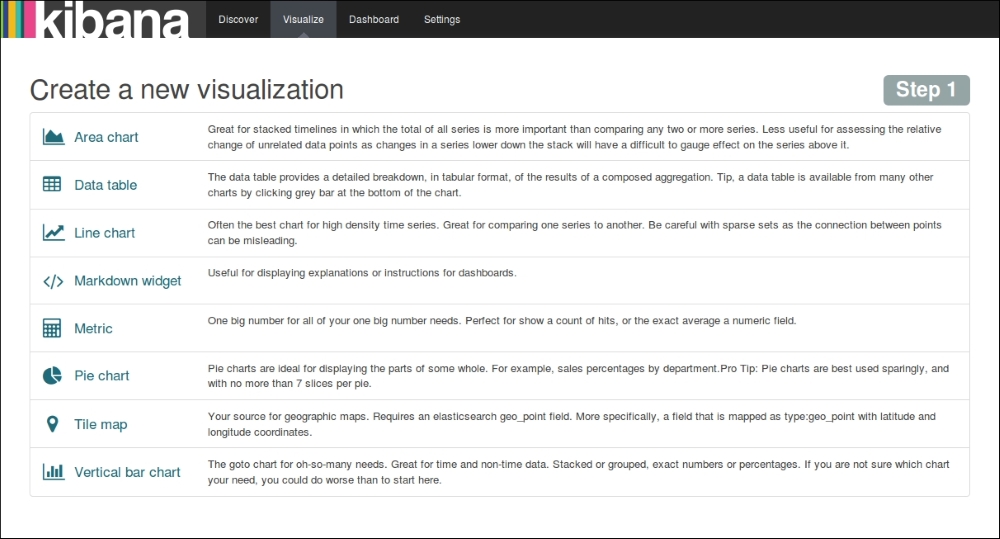
Kibana Visualize Page
Dashboard
Dashboard is a collection of saved visualizations in different groups. These visualizations can be arranged freely with a drag and drop kind of feature, and can be ordered as per the importance of the data. Dashboards can be easily saved, shared, and loaded at a later point in time.
Settings
The Settings page helps configure Elasticsearch indexes that we want to explore and configures various index patterns. Also, this page shows various indexed fields in one index pattern and data types of those fields. It also helps us create scripted fields, which are computed on the fly from the data.


