






















































Python and the Anaconda Package Management System
In this book, we will use the Python programming language. Python is a top language for data science and is one of the fastest growing programming languages. A commonly cited reason for Python's popularity is that it is easy to learn. If you have Python experience, that's great; however, if you have experience with other languages, such as C, Matlab, or R, you shouldn't have much trouble using Python. You should be familiar with the general constructs of computer programming to get the most out of this book. Examples of such constructs are for loops and if statements that guide the control flow of a program. No matter what language you have used, you are likely familiar with these constructs, which you will also find in Python.
A key feature of Python, that is different from some other languages, is that it is zero-indexed; in other words, the first element of an ordered collection has an index of 0. Python also supports negative indexing, where index-1 refers to the last element of an ordered collection and negative indices count backwards from the end. The slice operator, :, can be used to select multiple elements of an ordered collection from within a range, starting from the beginning, or going to the end of the collection.
Indexing and the Slice Operator
Here, we demonstrate how indexing and the slice operator work. To have something to index, we will create a list, which is a mutable ordered collection that can contain any type of data, including numerical and string types. "Mutable" just means the elements of the list can be changed after they are first assigned. To create the numbers for our list, which will be consecutive integers, we'll use the built-in range() Python function. The range() function technically creates an iterator that we'll convert to a list using the list() function, although you need not be concerned with that detail here. The following screenshot shows a basic list being printed on the console:
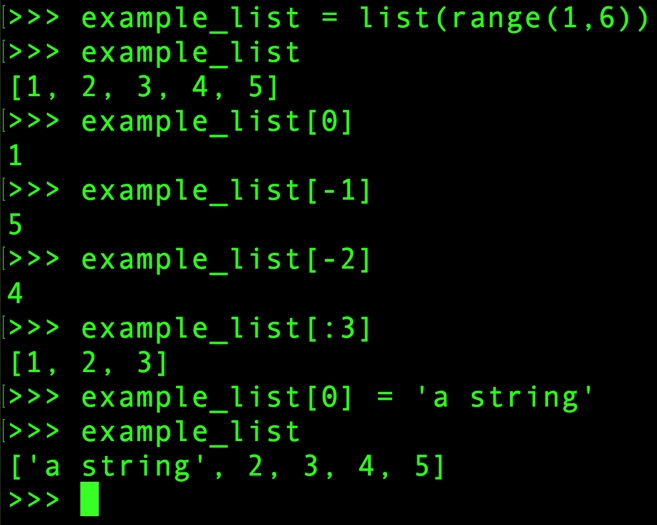
Figure 1.1: List creation and indexing
A few things to notice about Figure 1.1: the endpoint of an interval is open for both slice indexing and the range() function, while the starting point is closed. In other words, notice how when we specify the start and end of range(), endpoint 6 is not included in the result but starting point 1 is. Similarly, when indexing the list with the slice [:3], this includes all elements of the list with indices up to, but not including, 3.
We've referred to ordered collections, but Python also includes unordered collections. An important one of these is called a dictionary. A dictionary is an unordered collection of key:value pairs. Instead of looking up the values of a dictionary by integer indices, you look them up by keys, which could be numbers or strings. A dictionary can be created using curly braces {} and with the key:value pairs separated by commas. The following screenshot is an example of how we can create a dictionary with counts of fruit – examine the number of apples, then add a new type of fruit and its count:
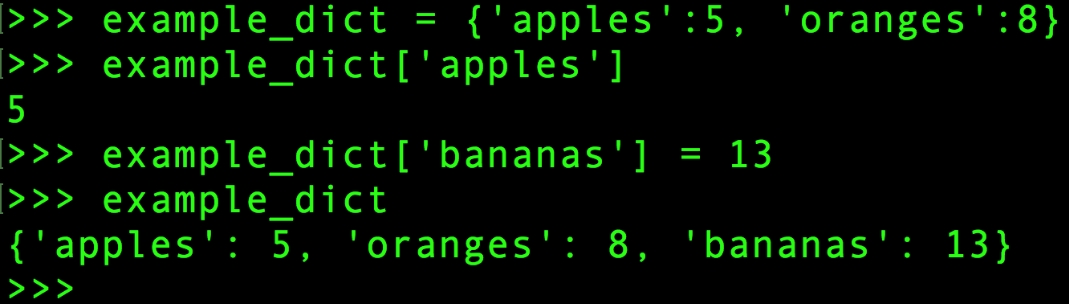
Figure 1.2: An example dictionary
There are many other distinctive features of Python and we just want to give you a flavor here, without getting into too much detail. In fact, you will probably use packages such as pandas (pandas) and NumPy (numpy) for most of your data handling in Python. NumPy provides fast numerical computation on arrays and matrices, while pandas provides a wealth of data wrangling and exploration capabilities on tables of data called DataFrames. However, it's good to be familiar with some of the basics of Python—the language that sits at the foundation of all of this. For example, indexing works the same in NumPy and pandas as it does in Python.
One of the strengths of Python is that it is open source and has an active community of developers creating amazing tools. We will use several of these tools in this book. A potential pitfall of having open source packages from different contributors is the dependencies between various packages. For example, if you want to install pandas, it may rely on a certain version of NumPy, which you may or may not have installed. Package management systems make life easier in this respect. When you install a new package through the package management system, it will ensure that all the dependencies are met. If they aren't, you will be prompted to upgrade or install new packages as necessary.
For this book, we will use the Anaconda package management system, which you should already have installed. While we will only use Python here, it is also possible to run R with Anaconda.
Note
Environments
If you previously had Anaconda installed and were using it prior to this book, you may wish to create a new Python 3.x environment for the book. Environments are like separate installations of Python, where the set of packages you have installed can be different, as well as the version of Python. Environments are useful for developing projects that need to be deployed in different versions of Python. For more information, see https://conda.io/docs/user-guide/tasks/manage-environments.html.
Exercise 1: Examining Anaconda and Getting Familiar with Python
In this exercise, you will examine the packages in your Anaconda installation and practice some basic Python control flow and data structures, including a for loop, dict, and list. This will confirm that you have completed the installation steps in the preface and show you how Python syntax and data structures may be a little different from other programming languages you may be familiar with. Perform the following steps to complete the exercise:
Note
The code file for this exercise can be found here: http://bit.ly/2Oyag1h.
Open up a Terminal, if you're using macOS or Linux, or a Command Prompt window in Windows. Type conda list at the command line. You should observe an output similar to the following:
Figure 1.3: Selection of packages from conda list
You can see all the packages installed in your environment. Look how many packages already come with the default Anaconda installation! These include all the packages we will need for the book. However, installing new packages and upgrading existing ones is easy and straightforward with Anaconda; this is one of the main advantages of a package management system.
Type python in the Terminal to open a command-line Python interpreter. You should obtain an output similar to the following:

Figure 1.4: Command-line Python
You should also see some information about your version of Python, as well as the Python command prompt (>>>). When you type after this prompt, you are writing Python code.
Note
Although we will be using the Jupyter Notebook in this book, one of the aims of this exercise is to go through the basic steps of writing and running Python programs on the command prompt.
Write a for loop at the command prompt to print values from 0 to 4 using the following code:
for counter in range(5): ... print(counter) ...
Once you hit Enter when you see (...) on the prompt, you should obtain this output:

Figure 1.5: Output of a for loop at the command line
Notice that in Python, the opening of the for loop is followed by a colon, and the body of the loop requires indentation. It's typical to use four spaces to indent a code block. Here, the for loop prints the values returned by the range() iterator, having repeatedly accessed them using the counter variable with the in keyword.
Note
For many more details on Python code conventions, refer to the following: https://www.python.org/dev/peps/pep-0008/.
Now, we will return to our dictionary example. The first step here is to create the dictionary.
Create a dictionary of fruits (apples, oranges, and bananas) using the following code:
example_dict = {'apples':5, 'oranges':8, 'bananas':13}Convert the dictionary to a list using the list() function, as shown in the following snippet:
dict_to_list = list(example_dict) dict_to_list
Once you run the preceding code, you should obtain the following output:

Figure 1.6: Dictionary keys converted to a list
Notice that when this is done and we examine the contents, only the keys of the dictionary have been captured in the list. If we wanted the values, we would have had to specify that with the .values() method of the list. Also, notice that the list of dictionary keys happens to be in the same order that we wrote them in when creating the dictionary. This is not guaranteed, however, as dictionaries are unordered collection types.
One convenient thing you can do with lists is to append other lists to them with the + operator. As an example, in the next step we will combine the existing list of fruit with a list that contains just one more type of fruit, overwriting the variable containing the original list.
Use the + operator to combine the existing list of fruits with a new list containing only one fruit (pears):
dict_to_list = dict_to_list + ['pears'] dict_to_list

Figure 1.7: Appending to a list
What if we wanted to sort our list of fruit types?
Python provides a built-in sorted() function that can be used for this; it will return a sorted version of the input. In our case, this means the list of fruit types will be sorted alphabetically.
Sort the list of fruits in alphabetical order using the sorted() function, as shown in the following snippet:
sorted(dict_to_list)
Once you run the preceding code, you should see the following output:

Figure 1.8: Sorting a list
That's enough Python for now. We will show you how to execute the code for this book, so your Python knowledge should improve along the way.
Note
As you learn more and inevitably want to try new things, you will want to consult the documentation: https://docs.python.org/3/.






















