






















































Working through a RAG example with LangChain
LangChain provides functionality to carry out all of the steps we’ve outlined. So, let’s look at a RAG example while looking at how we achieve the steps with LangChain in more detail.
For our use case, we’re going to look at using unstructured website data as the basis for our RAG system. This is a common example of a RAG application as most organizations have websites and unstructured data that they want to use. Imagine that your organization has asked you to create an LLM-powered chatbot that can answer questions about the content on your organization’s website.
In our scenario, we’ll explore leveraging unstructured website data as the foundation for our RAG system. Utilizing unstructured data from websites is a prevalent approach for RAG applications given that most organizations possess websites filled with data they wish to use. Imagine being tasked by your organization to develop a chatbot capable of answering queries related to the content on your company’s website.
For our example, we’re going to create a chatbot that can provide up-to-date information about New York’s economy. For our data source, we’ll use Wikipedia. You’re welcome to follow your own subject matter for this and even use your own website pages.
The first step is to load our dataset with a document loader. So, let’s dive in.
Integrating data – choosing your document loader
LangChain document loaders are designed to easily fetch documents from different sources, serving as the initial step in the data retrieval process. LangChain provides access to over 100 different document loaders that cater to a diverse range of data sources, such as private cloud storage, public websites, or even specific document formats such as HTML, CSV, PDF, JSON, and code files.
The document loader you need will depend on your use case and requirements. With the options available, you can integrate data from practically any source into your ChatGPT application, whether that be unstructured public or private data from websites or cloud storage such as Google Drive. You can also load more structured information from many different database types or data storage providers.
In addition to their versatility, document loaders in LangChain are designed to be easy to use. They offer straightforward interfaces that allow developers to quickly set up and start fetching documents with minimal configuration. This simplicity accelerates the development process, particularly when you’re creating proofs of concept to try out different data sources. Hopefully, this will give you more time to focus on more complex aspects of your application.
Let’s look at a simple example of a document loader. Remember that we want to answer questions about New York, so our dataset needs to match the requirements. Wikipedia is a great source for up-to-date information, so this will suffice for this example. Let’s look at using WebBaseLoader, an HTML document loader, to pull some information from Wikipedia as the basis for our dataset:
from langchain_community.document_loaders import WebBaseLoader loader = WebBaseLoader( ["https://en.wikipedia.org/wiki/New_York_City#Economy"]) docs = loader.load() print(len(docs)) print(docs)
Printing out the docs variable should result in something similar to the following, where page_content is the text data we’re going to use:
[Document(page_content='\n\n\n\nNew York City – Wikipedia
...
metadata={'source': 'https://en.wikipedia.org/wiki/New_York_City#Economy', 'title': 'New York City - Wikipedia', 'language': 'en'})] Considering the unstructured HTML data we have, it may also be worth considering using documentTransformer to clean up our HTML into plain text, such as AsyncHtmlLoader.
Many other LangChain document loader options are purpose-built for specific use cases, so it’s always worth checking what’s available in Python or TypeScript.
For our example, we’ll use WikipediaLoader, which we used earlier in this chapter. Note that I’m keeping load_max_docs low for the interests of this example:
docs = WikipediaLoader(query="New York economy", load_max_docs=5).load()
The benefit of using this is that we now have data from multiple Wikipedia pages. The results from WikipediaLoader should look pretty good, with a list of documents similar in structure to the WebBaseLoader results.
Now that we have our dataset, the next step is to index it.
Creating manageable chunks with text splitting
As we discussed in the section on Chunking for Effective LLM Interactions, the process of text splitting can be quite complicated, requiring careful decisions about chunk size and the appropriate method to use. Fortunately, LangChain provides easy-to-use interfaces and integrations for several modules that can be used to “chunk” or split our document dataset so that it’s ready for further processing.
LangChain’s text-splitting algorithms are designed to be versatile and efficient, ensuring that the integrity and context of the original document are maintained while optimizing it for retrieval. This involves considering factors such as the nature and format of the text, the logical divisions within the document, and the specific requirements of the retrieval task at hand.
Implementing text splitting in LangChain can be done by using one of the out-of-the-box splitters, which provide different ways to split depending on the dataset itself.
Tip
One fantastic tool for understanding different chunking strategies and evaluating the results of chunking your text is https://chunkviz.up.railway.app. It’s a brilliant way to see how your text is split based on the LangChain utility and different parameters such as chunk size and overlap.
For this use case, we’re going to use RecursiveCharacterTextSplitter to chunk our text. The RecursiveCharacterTextSplitter utility is designed to efficiently segment text into manageable pieces. It looks for predefined separator characters such as newlines, spaces, and empty strings. The result should be chunked text broken down into paragraphs, sentences, and words, where the text segments preserve the meaning of related text segments. The utility dynamically divides text into chunks, targeting a specific size in terms of character count. Once a chunk reaches this predetermined size, it’s earmarked as an output segment. To ensure continuity and context are maintained across these segments, adjacent chunks feature a configurable degree of overlap.
Its parameters are fully customizable, offering flexibility to accommodate various text types and application requirements.
It’s a good solution for breaking down large volumes of text into smaller, semantically meaningful units.
Here is our example code, which uses RecursiveCharacterTextSplitter. This is recommended for generic text:
from langchain.text_splitter import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=500, chunk_overlap=100) split_documents = text_splitter.split_documents(docs) print(len(split_documents))
We can create our RecursiveCharacterTextSplitter class with attributes that we wish to control, including chunk_size, which ensures manageable sizes for processing, and chunk_overlap, which allows for character overlap between chunks, maintaining context continuity. If you change the chunk size, you’ll be able to create a document list with more entries. You can look at one of the split documents by running the following command:
print(documents[5])
With RecursiveCharacterTextSplitter, we’ve broken down our large text content into smaller, meaningful units. This prepares our data for further processing and analysis. Now that we’ve explored text splitting, let’s delve into how we can use our chunks to create embeddings:
Creating and storing text embeddings
Now that we have chunks of manageable data, it’s time to create embeddings from these chunks and store them in our vector database. For this example, we’re going to use ChromaDB as our vector store.
Here, we’re going to create our embeddings from the langchain_openai and langchain.vectorstores libraries, which allow us to call the OpenAI embeddings service and store them in ChromaDB. Follow these steps:
- First, we must initialize an instance of the
OpenAIEmbeddingsclass with our specific model,text-embedding-3-small:from langchain_openai import OpenAIEmbeddings from langchain.vectorstores.chroma import Chroma embeddings_model = OpenAIEmbeddings( model=" text-embedding-3-small")
- The
docs_vectorstore = Chroma(...)line creates an instance of the Chroma class, which is used to store document vectors. The following parameters are provided to Chroma:collection_name="chapter7db_documents_store": This specifies the name of the collection within Chroma where the document vectors will be stored. Think of it as naming a table in a database where your data will be kept.embedding_function=embeddings_model: Here, the previously createdembeddings_modelis passed as the embedding function. This tells Chroma to use theOpenAIEmbeddingsinstance to generate embeddings for documents before storing them. Essentially, whenever a document is added to Chroma, it will be passed through this embedding model to convert the text into a vector.persist_directory="chapter7db": This parameter specifies the directory where Chroma will persistently store its data. This allows the vector store to maintain its state between program runs. In our case, it will be a folder where we’re running our Jupyter Notebook:documents_vectorstore = Chroma( collection_name="docs_store", embedding_function=embeddings_model, persist_directory="chapter7db", )
- We can then pass in our previously split documents by calling
add_documents(). After, we can persist everything by callingpersist()on our Chroma instance:chroma_document_store.add_documents(split_documents) chroma_document_store.persist()
- Now, we can conduct a search to see if we get any results back. We’ll do this by carrying out a similarity search on the Chroma instance by calling
similarity_searchwith our text query. Try a question related to New York’s economy:similar_documents = chroma_document_store.similarity_search( query="what was the gross state product in 2022") print(similar_documents)
You should be able to print out search results for your query. Now, let’s look at bringing our RAG system together with LangChain.
Bringing everything together with LangChain
Now that we have our Chroma document store returning results, let’s learn how to bring all our RAG elements together using LangChain so that we can create a system that’s capable of answering questions based on information in our documents:
- We’ll begin by importing the necessary classes from the
langchain_openaiandlangchain_corelibraries, as well as the variables we need to log in to LangSmith. Then, we need to create an instance of theChatOpenAIclass so that we can leverage GPT-4 to generate our answers:from langchain_openai import ChatOpenAI from langchain_core.prompts import ChatPromptTemplate from langchain_core.runnables import ( RunnableParallel, RunnablePassthrough) os.environ['LANGCHAIN_API_KEY'] = '' os.environ['LANGCHAIN_PROJECT'] = "book-chapter-7" os.environ['LANGCHAIN_TRACING_V2'] = "true" os.environ['LANGCHAIN_ENDPOINT'] = "https://api.smith.langchain.com" from langchain_core.output_parsers import StrOutputParser llm = ChatOpenAI(model="gpt-4", temperature=0.0)
Setting the temperature to
0.0makes the model’s responses deterministic, which is often desirable for consistent QA performance. - Now that our Chroma document store has been set up, we can initialize a retriever to fetch relevant documents based on our query:
retriever = chroma_document_store.as_retriever( search_kwargs={"k": 5})The retriever is configured to return the top
5documents that match a query. - Next, we need to create a prompt template that tells the language model how to utilize the retrieved documents to answer questions:
template = """ You are an assistant specializing in question-answering tasks based on provided document excerpts. Your task is to analyze the given excerpts and formulate a final answer, citing the excerpts as "SOURCES" for reference. If the answer is not available in the excerpts, clearly state "I don't know." Ensure every response includes a "SOURCES" section, even if no direct answer can be provided. QUESTION: {question} ========================== EXCERPTS: {chroma_documents} ========================== FINAL ANSWER(with SOURCES if available): """ prompt = ChatPromptTemplate.from_template(template)This template helps the model provide sourced answers from our data or instructs us to indicate when information is unavailable:

Figure 7.4 – Prompt passed to the LLM
- Next, implement a function to format the retrieved documents so that they can be included in the prompt:
def format_chroma_docs(chroma_docs) -> str: return "\n".join( f"Content: {doc.page_content}\nSource: {doc.metadata['source']}" for doc in chroma_docs )We’ll use this function to organize document content and sources into a readable format when they’re included in our prompt.
- Now, we must use LCEL to create our question-answering pipeline. This setup allows us to directly apply formatting to the retrieved documents and streamlines the flow into the prompt generation and answer production stages:
rag_chain_from_docs = ( {"chroma_documents": retriever | format_docs, "question": RunnablePassthrough()} | prompt | llm | StrOutputParser() )Here’s what each part of this pipeline does:
- Processing with
RunnablePassthroughand document retrieval:{"chroma_documents": retriever | format_docs, "question": RunnablePassthrough()}: This dictionary sets up two parallel streams. Forchroma_documents, documents are retrieved viaretrieverand then immediately formatted withformat_docs. Forquestion,RunnablePassthrough()is used to simply pass the question through without any modification. This approach efficiently prepares both the formatted documents and the question for the next step. - Prompt application:
| prompt: The processed information (both question and formatted documents) is then piped into the prompt. This step utilizesChatPromptTemplateto combine the question with the formatted documents according to the predefined template, setting the stage for the LLM to generate an answer. - Language model generation:
llm: Here, the combined input from the previous step is fed into the language model (GPT-4) initialized earlier. The model generates a response based on the prompt, effectively answering the question with the help of information extracted from the retrieved documents. - Output parsing:
| StrOutputParser(): Finally, the output from the language model is parsed into a string format byStrOutputParser(). This step ensures that the final answer is easily readable and formatted correctly.
- Processing with
- Finally, we can invoke the pipeline with a question and print the answer:
question = "what stock exchanges are located in the big apple" rag_chain_from_docs.invoke(question)
This search should return something similar to the following, including an answer and sources:
The stock exchanges located in New York City, often referred to as the "Big Apple", are the New York Stock Exchange and Nasdaq. These are the world\'s two largest stock exchanges by market capitalization of their listed companies. \n\nSOURCES: \n- https://en.wikipedia.org/wiki/New_York_City\n- https://en.wikipedia.org/wiki/Economy_of_New_York_City'
By following these steps, you’ve constructed a RAG system that’s capable of answering questions about New York’s economy with up-to-date information from Wikipedia. Try some other questions and see how the FAQ performs.
Remember that it’s useful to look at the debugging output in LangSmith so that you can see what’s going on in each step of LangChain. In the following screenshot, we’ve drilled down into the LangSmith prompt template output so that we can see the documents we’ve retrieved and passed into the LLM prompt:
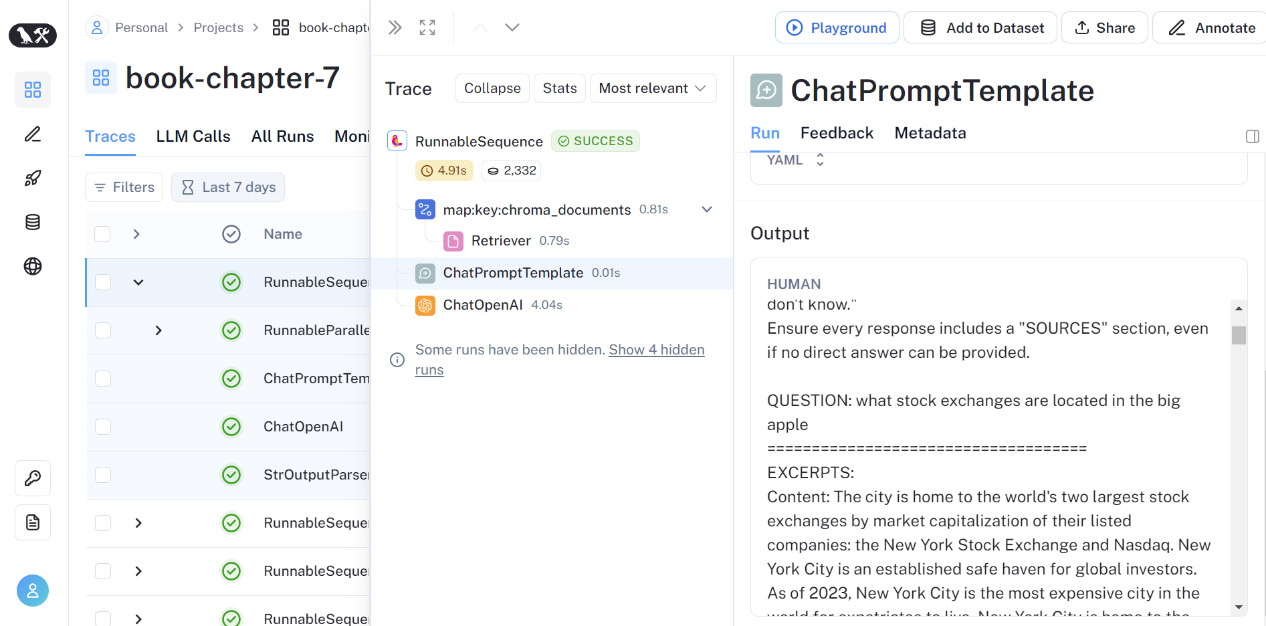
Figure 7.5 – Using LangSmith to see what’s going on under the hood
First, we loaded our documents from Wikipedia based on our subject criteria, chunked this data, and created embeddings that we’ve stored in our vector store. Then, we defined a retriever to query our store, passed the document search results to an LLM prompt, and handed over to our LLM to get an accurate response to our question while listing sources and safeguarding against hallucinations. This was brought together with a LangChain defined in LCEL.


