






















































The ecosystem of transformers
Transformer models represent such a paradigm change that they require a new name to describe them: foundation models. Accordingly, Stanford University created the Center for Research on Foundation Models (CRFM). In August 2021, the CRFM published a two-hundred-page paper (see the References section) written by over one hundred scientists and professionals: On the Opportunities and Risks of Foundation Models.
Foundation models were not created by academia but by the big tech industry. For example, Google invented the transformer model, which led to Google BERT. Microsoft entered a partnership with OpenAI to produce GPT-3.
Big tech had to find a better model to face the exponential increase of petabytes of data flowing into their data centers. Transformers were thus born out of necessity.
Let’s first take Industry 4.0 into consideration to understand the need to have industrialized artificial intelligence models.
Industry 4.0
The Agricultural Revolution led to the First Industrial Revolution, which introduced machinery. The Second Industrial Revolution gave birth to electricity, the telephone, and airplanes. The Third Industrial Revolution was digital.
The Fourth Industrial Revolution, or Industry 4.0, has given birth to an unlimited number of machine to machine connections: bots, robots, connected devices, autonomous cars, smartphones, bots that collect data from social media storage, and more.
In turn, these millions of machines and bots generate billions of data records every day: images, sound, words, and events, as shown in Figure 1.1:
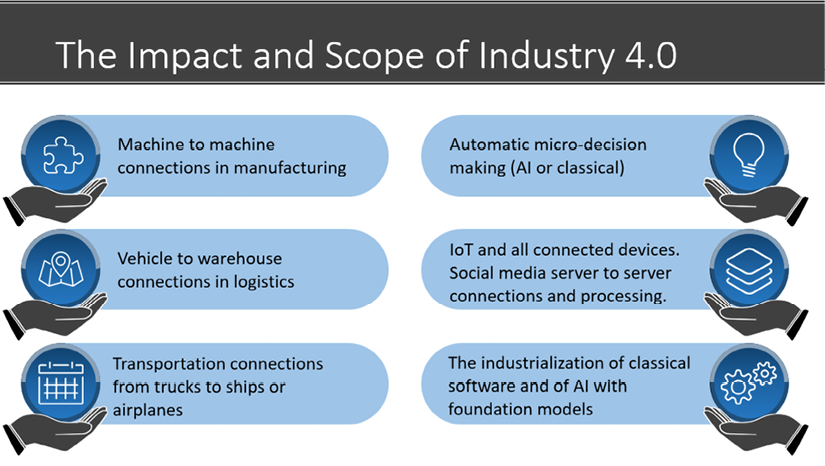
Figure 1.1: The scope of Industry 4.0
Industry 4.0 requires intelligent algorithms that process data and make decisions without human intervention on a large scale to face this unseen amount of data in the history of humanity.
Big tech needed to find a single AI model that could perform a variety of tasks that required several separate algorithms in the past.
Foundation models
Transformers have two distinct features: a high level of homogenization and mind-blowing emergence properties. Homogenization makes it possible to use one model to perform a wide variety of tasks. These abilities emerge through training billion-parameter models on supercomputers.
The paradigm change makes foundation models a post-deep learning ecosystem, as shown in Figure 1.2:
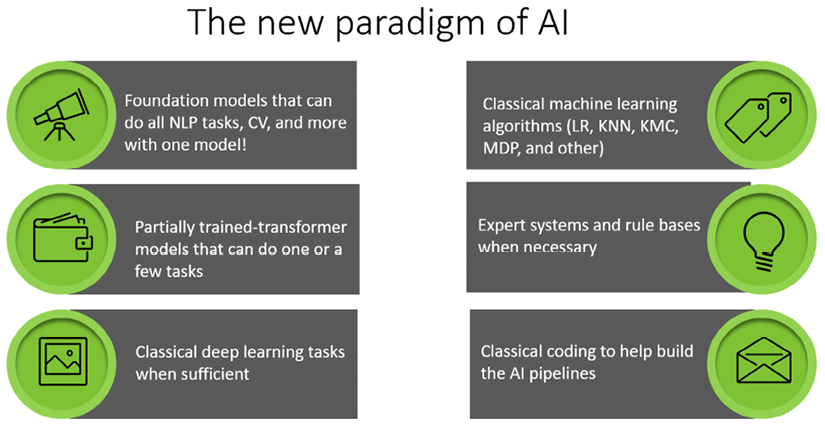
Figure 1.2: The scope of an I4.0 AI specialist
Foundation models, although designed with an innovative architecture, are built on top of the history of AI. As a result, an artificial intelligence specialist’s range of skills is stretching!
The present ecosystem of transformer models is unlike any other evolution in artificial intelligence and can be summed up with four properties:
- Model architecture
The model is industrial. The layers of the model are identical, and they are specifically designed for parallel processing. We will go through the architecture of transformers in Chapter 2, Getting Started with the Architecture of the Transformer Model.
- Data
Big tech possesses the hugest data source in the history of humanity, first generated by the Third Industrial Revolution (digital) and boosted to unfathomable sizes by Industry 4.0.
- Computing power
Big tech possesses computer power never seen before at that scale. For example, GPT-3 was trained at about 50 PetaFLOPS/second, and Google now has domain-specific supercomputers that exceed 80 PetaFLOPS/second.
- Prompt engineering
Highly trained transformers can be triggered to do a task with a prompt. The prompt is entered in natural language. However, the words used require some structure, making prompts a metalanguage.
A foundation model is thus a transformer model that has been trained on supercomputers on billions of records of data and billions of parameters. The model can then perform a wide range of tasks with no further fine-tuning. Thus, the scale of foundation models is unique. These fully trained models are often called engines. Only GPT-3, Google BERT, and a handful of transformer engines can thus qualify as foundation models.
I will only refer to foundation models in this book when mentioning OpenAI’s GPT-3 or Google’s BERT model. This is because GPT-3 and Google BERT were fully trained on supercomputers. Though interesting and effective for limited use, other models do not reach the homogenization level of foundation models due to the lack of resources.
Let’s now explore an example of how foundation models work and have changed the way we develop programs.
Is programming becoming a sub-domain of NLP?
Chen et al. (2021) published a bombshell paper in August 2021 on Codex, a GPT-3 model that can convert natural language into source code. Codex was trained on 54 million public GitHub software repositories.
Is programming now a translation task from natural language to source code languages?
Is programming becoming an NLP task for GPT-3 engines?
Let’s look into an example before answering that question.
Bear in mind that Codex is a stochastic algorithm, so the metalanguage is tricky. You might not generate what you expect if you are not careful to engineer the prompt correctly.
I created some prompts as I was experimenting with Codex. This example is just to give an idea of how Codex works and is purely for educational purposes.
My prompts were:
- “generate a random distribution of 200 integers between 1 and 100” in Python
- “plot the data using matplotlib”
- “create a k-means clustering model with 3 centroids and fit the model”
- “print the cluster labels”
- “plot the clusters”
- “plot the clusters with centroids”
Codex translated my natural metalanguage prompts into Python automatically!
Codex is a stochastic model, so it might not reproduce exactly the same code if you try again. You will have to learn the metalanguage through experimentation until you can drive it like a race car!
The Python program is generated automatically and can be copied and tested:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets.samples_generator import make_blobs
# generate random data
np.random.seed(0)
X, y = make_blobs(n_samples=200, centers=3, n_features=2, cluster_std=2, random_state=0)
# plot the data
plt.scatter(X[:, 0], X[:, 1], s=50)
plt.show()
# create the k-means model
kmeans = KMeans(n_clusters=3, random_state=0)
# fit the model to the data
kmeans.fit(X)
# print the cluster labels
print(kmeans.labels_)
#plot the clusters
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_, cmap='rainbow')
plt.show()
# plot the clusters with centroids
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_, cmap='rainbow')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], c='black', s=100, alpha=0.5)
plt.show()
You can copy and paste this program. It works. You can also try JavaScript, among other experiments.
GitHub Copilot is now available with some Microsoft developing tools, as we will see in Chapter 16, The Emergence of Transformer-Driven Copilots. If you learn the prompt engineering metalanguage, you will reduce your development time in years to come.
End users can create prototypes and or small tasks if they master the metalanguage. In the future, coding copilots will expand.
At this point, let’s take a glimpse into the bright future of artificial intelligence specialists.
The future of artificial intelligence specialists
The societal impact of foundation models should not be underestimated. Prompt engineering has become a skill required for artificial intelligence specialists. However, the future of AI specialists cannot be limited to transformers. AI and data science overlap in I4.0.
An AI specialist will be involved in machine to machine algorithms using classical AI, IoT, edge computing, and more. An AI specialist will also design and develop fascinating connections between bots, robots, servers, and all types of connected devices using classical algorithms.
This book is thus not limited to prompt engineering but to a wide range of design skills required to be an “Industry 4.0 artificial intelligence specialist” or “I4.0 AI specialist.”
Prompt engineering is a subset of the design skills an AI specialist will have to develop. In this book, I will thus refer to the future AI specialist as an “Industry 4.0 artificial intelligence specialist.”
Let’s now get a general view of how transformers optimize NLP models.

