






















































Exploring a Dataset – Wholesale Customers Dataset
As part of the process of learning the behavior and applications of clustering algorithms, the following sections of this chapter will focus on solving a real-life data problem using the Wholesale Customers dataset, which is available at the UC Irvine Machine Learning Repository.
Note
Datasets in repositories may contain raw, partially pre-processed, or pre-processed data. To use any of these datasets, ensure that you read the specifications of the data that's available to understand the process that needs to be followed to model the data effectively, or whether it is the right dataset for your purpose.
For instance, the current dataset is an extract from a larger dataset, as per the following citation:
The dataset originates from a larger database referred on: Abreu, N. (2011). Analise do perfil do cliente Recheio e desenvolvimento de um sistema promocional. Mestrado em Marketing, ISCTE-IUL, Lisbon.
In the following section, we will analyze the contents of the dataset, which will then be used in Activity 2.01, Using Data Visualization to Aid the Pre-processing Process. To download a dataset from the UC Irvine Machine Learning Repository, perform the following steps:
- Access the following link: http://archive.ics.uci.edu/ml/datasets/Wholesale+customers.
- Below the dataset's title, find the download section and click on
Data Folder. - Click on the
Wholesale Customers data.csvfile to trigger the download and save the file in the same path as that of your current Jupyter Notebook.Note
You can also access it by going to this book's GitHub repository: https://packt.live/3c3hfKp
Understanding the Dataset
Each step will be explained generically and will then be followed by an explanation of its application in the current case study (the Wholesale Customers dataset):
- First of all, it is crucial to understand the way in which data is presented by the person who's responsible for gathering and maintaining it.
Considering that the dataset of the case study was obtained from an online repository, the format in which it is presented must be understood. The Wholesale Customers dataset consists of a snippet of historical data of clients from a wholesale distributor. It contains a total of 440 instances (each row) and eight features (each column).
- Next, it is important to determine the purpose of the study, which is dependent on the data that's available. Even though this might seem like a redundant statement, many data problems become problematic because the researcher does not have a clear view of the purpose of the study, and hence the pre-processing methodology, the model, and the performance metrics are chosen incorrectly.
The purpose of using clustering algorithms on the Wholesale Customers dataset is to understand the behavior of each customer. This will allow you to group customers with similar behaviors into one cluster. The behavior of a customer will be defined by how much they spent on each category of product, as well as the channel and the region where they bought products.
- Subsequently explore all the features that are available. This is mainly done for two reasons: first, to rule out features that are considered to be of low relevance based on the purpose of the study or that are considered to be redundant, and second, to understand the way the values are presented to determine some of the pre-processing techniques that may be needed.
The current case study has eight features, each one of which is considered to be relevant to the purpose of the study. Each feature is explained in the following table:
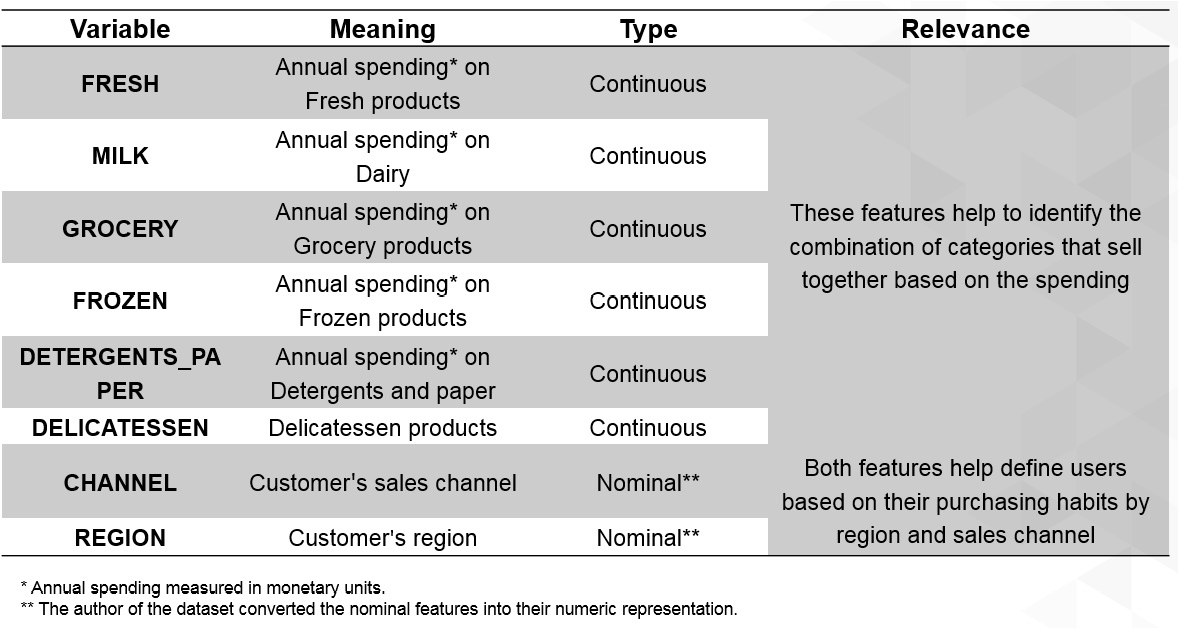
Figure 2.1: A table explaining the features in the case study
In the preceding table, no features are to be dismissed, and nominal (categorical) features have already been handled by the author of the dataset.
As a summary, the first thing to do when choosing a dataset or being handed one is to understand the characteristics that are visible at first glance, which involves recognizing the information available, then determining the purpose of the project, and finally revising the features to select those that will be part of the study. After this, the data can be visualized so that it can be understood before it's pre-processed.




