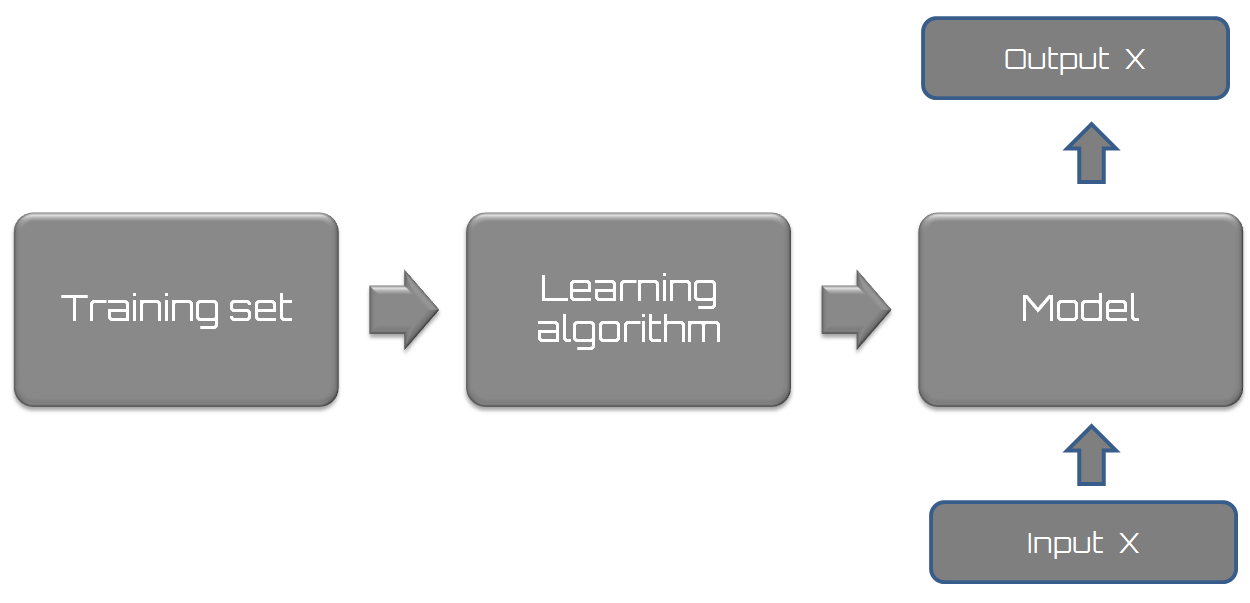
Machine learning is a multidisciplinary field created at the intersection of, and by the synergy between, computer science, statistics, neurobiology, and control theory. Its emergence has played a key role in several fields and has fundamentally changed the vision of software programming. If the question before was, how to program a computer, now the question becomes is how computers will program themselves. Thus, it is clear that machine learning is a basic method that allows a computer to have its own intelligence.
As might be expected, machine learning interconnects and coexists with the study of, and research on, human learning. Like humans, whose brain and neurons are the foundation of insight, Artificial Neural Networks (ANNs) are the basis of any decision-making activity of the computer.
Machine learning refers to the ability to learn from experience without any outside help, which is what we humans do, in most cases. Why should it not be the same for machines?
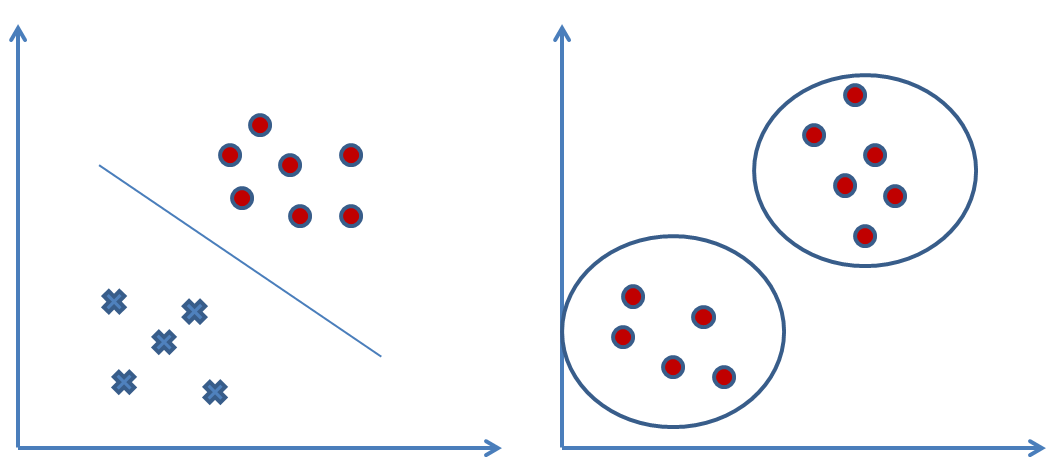
From a set of data, we can find a model that approximates the set by the use of machine learning. For example, we can identify a correspondence between input variables and output variables for a given system. One way to do this is to postulate the existence of some kind of mechanism for the parametric generation of data, which, however, does not know the exact values of the parameters. This process typically makes reference to statistical techniques, such as the following:
- Induction
- Deduction
- Abduction
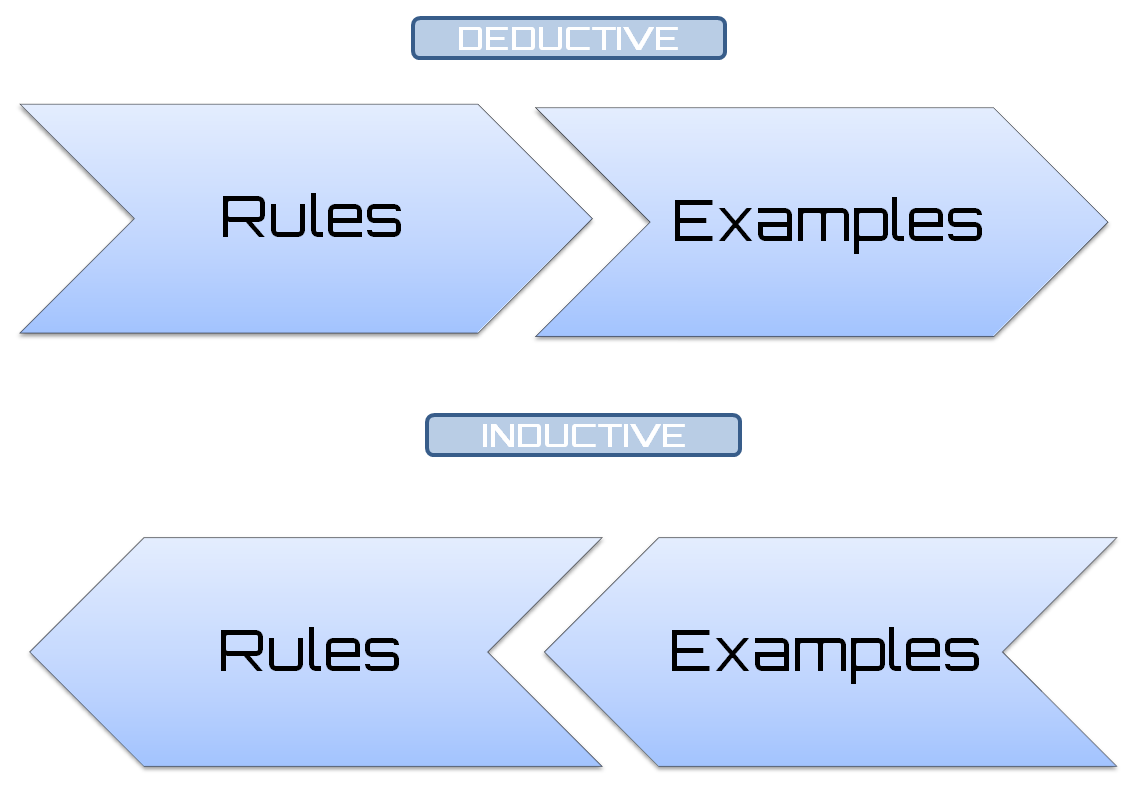
The extraction of general laws from a set of observed data is called induction; it is opposed to deduction, in which, starting from general laws, we want to predict the value of a set of variables. Induction is the fundamental mechanism underlying the scientific method in which we want to derive general laws, typically described in a mathematical language, starting from the observation of phenomena.
This observation includes the measurement of a set of variables and, therefore, the acquisition of data that describes the observed phenomena. Then, the resultant model can be used to make predictions on additional data. The overall process in which, starting from a set of observations, we want to make predictions for new situations, is called inference. Therefore, inductive learning starts from observations arising from the surrounding environment and generalizes obtaining knowledge that will be valid for not-yet-observed cases; at least we hope so.
Inductive learning is based on learning by example: knowledge gained by starting from a set of positive examples that are instances of the concept to be learned, and negative examples that are non-instances of the concept. In this regard, Galileo Galilei's (1564-1642) phrase is particularly clear:
The following diagram consists of a flowchart showing inductive and deductive learning:
A question arises spontaneously: why do machine learning systems work where traditional algorithms fail? The reasons for the failure of traditional algorithms are numerous and typically include the following:
- Difficulty in problem formalization: For example, each of us can recognize our friends from their voices. But probably none can describe a sequence of computational steps enabling them to recognize the speaker from the recorded sound.
- High number of variables at play: When considering the problem of recognizing characters from a document, specifying all parameters that are thought to be involved can be particularly complex. In addition, the same formalization applied in the same context but on a different idiom could prove inadequate.
- Lack of theory: Imagine you have to predict exactly the performance of financial markets in the absence of specific mathematical laws.
- Need for customization: The distinction between interesting and uninteresting features depends significantly on the perception of the individual user.
A quick analysis of these issues highlights the lack of experience in all cases.