






















































38. Explain and exemplifying UTF-8, UTF-16, and UTF-32
Character encoding/decoding is important for browsers, databases, text editors, filesystems, networking, and so on, so it’s a major topic for any programmer. Check out the following figure:

Figure 2.1: Representing text with different char sets
In Figure 2.1, we see several Chinese characters represented in UTF-8, UTF-16, and ANSI on a computer screen. But, what are these? What is ANSI? What is UTF-8 and how did we get to it? Why don’t these characters look normal in ANSI?
Well, the story may begin with computers trying to represent characters (such as letters from the alphabet or digits or punctuation marks). The computers understand/process everything from the real world as a binary representation, so as a sequence of 0 and 1. This means that every character (for instance, A, 5, +, and so on) has to be mapped to a sequence of 0 and 1.
The process of mapping a character to a sequence of 0 and 1 is known as character encoding or simply encoding. The reverse process of un-mapping a sequence of 0 and 1 to a character is known as character decoding or simply decoding. Ideally, an encoding-decoding cycle should return the same character; otherwise, we obtain something that we don’t understand or we cannot use.
For instance, the Chinese character,  , should be encoded in the computer’s memory as a sequence of 0 and 1. Next, when this sequence is decoded, we expect back the same Chinese letter,
, should be encoded in the computer’s memory as a sequence of 0 and 1. Next, when this sequence is decoded, we expect back the same Chinese letter,  . In Figure 2.1, this happens in the left and middle screenshots, while in the right screenshot, the returned character is
. In Figure 2.1, this happens in the left and middle screenshots, while in the right screenshot, the returned character is  …. A Chinese speaker will not understand this (actually, nobody will), so something went wrong!
…. A Chinese speaker will not understand this (actually, nobody will), so something went wrong!
Of course, we don’t have only Chinese characters to represent. We have many other sets of characters grouped in alphabets, emoticons, and so on. A set of characters has well-defined content (for instance, an alphabet has a certain number of well-defined characters) and is known as a character set or, in short, a charset.
Having a charset, the problem is to define a set of rules (a standard) that clearly explains how the characters of this charset should be encoded/decoded in the computer memory. Without having a clear set of rules, the encoding and decoding may lead to errors or indecipherable characters. Such a standard is known as an encoding scheme.
One of the first encoding schemes was ASCII.
Introducing ASCII encoding scheme (or single-byte encoding)
ASCII stands for American Standard Code for Information Interchange. This encoding scheme relies on a 7-bit binary system. In other words, each character that is part of the ASCII charset (http://ee.hawaii.edu/~tep/EE160/Book/chap4/subsection2.1.1.1.html) should be representable (encoded) on 7 bits. A 7-bit number can be a decimal between 0 and 127, as in the next figure:
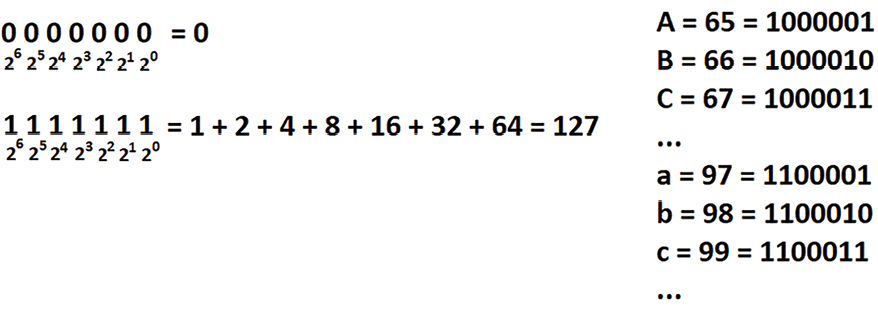
Figure 2.2: ASCII charset encoding
So, ASCII is an encoding scheme based on a 7-bit system that supports 128 different characters. But, we know that computers operate on bytes (octets) and a byte has 8 bits. This means that ASCII is a single-byte encoding scheme that leaves a bit free for each byte. See the following figure:
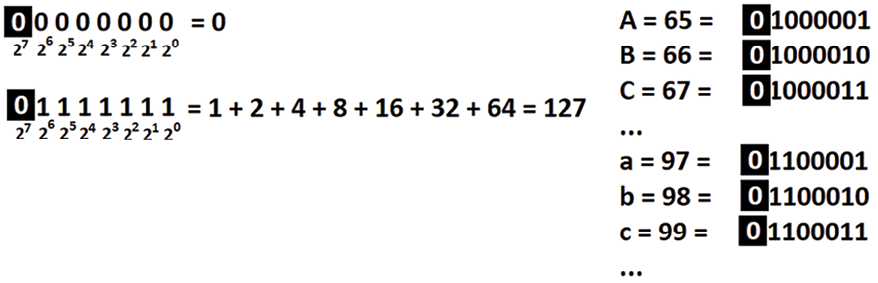
Figure 2.3: The highlighted bit is left free in ASCII encoding
In ASCII encoding, the letter A is 65, the letter B is 66, and so on. In Java, we can easily check this via the existing API, as in the following simple code:
int decimalA = "A".charAt(0); // 65
String binaryA = Integer.toBinaryString(decimalA); // 1000001
Or, let’s see the encoding of the text Hello World. This time, we added the free bit as well, so the result will be 01001000 01100101 01101100 01101100 01101111 0100000 01010111 01101111 01110010 01101100 01100100:
char[] chars = "Hello World".toCharArray();
for(char ch : chars) {
System.out.print("0" + Integer.toBinaryString(ch) + " ");
}
If we perform a match, then we see that 01001000 is H, 01100101 is e, 01101100 is l, 01101111 is o, 0100000 is space, 01010111 is W, 01110010 is r, and 01100100 is d. So, besides letters, the ASCII encoding can represent the English alphabet (upper and lower case), digits, space, punctuation marks, and some special characters.
Besides the core ASCII for English, we also have ASCII extensions, which are basically variations of the original ASCII to support other alphabets. Most probably, you’ve heard about the ISO-8859-1 (known as ISO Latin 1), which is a famous ASCII extension. But, even with ASCII extensions, there are still a lot of characters in the world that cannot be encoded yet. There are countries that have a lot more characters than ASCII can encode, and even countries that don’t use alphabets. So, ASCII has its limitations.
I know what you are thinking … let’s use that free bit (27+127). Yes, but even so, we can go up to 256 characters. Still not enough! It is time to encode characters using more than 1 byte.
Introducing multi-byte encoding
In different parts of the world, people started to create multi-byte encoding schemes (commonly, 2 bytes). For instance, speaker of the Chinese language, which has a lot of characters, created Shift-JIS and Big5, which use 1 or 2 bytes to represent characters.
But, what happens when most of the countries come up with their own multi-byte encoding schemes trying to cover their special characters, symbols, and so on? Obviously, this leads to a huge incompatibility between the encoding schemes used in different countries. Even worse, some countries have multiple encoding schemes that are totally incompatible with each other. For instance, Japan has three different incompatible encoding schemes, which means that encoding a document with one of these encoding schemes and decoding with another will lead to a garbled document.
However, this incompatibility was not such a big issue before the Internet, since which documents have been massively shared all around the globe using computers. At that moment, the incompatibility between the encoding schemes conceived in isolation (for instance, countries and geographical regions) started to be painful.
It was the perfect moment for the Unicode Consortium to be created.
Unicode
In a nutshell, Unicode (https://unicode-table.com/en/) is a universal encoding standard capable of encoding/decoding every possible character in the world (we are talking about hundreds of thousands of characters).
Unicode needs more bytes to represent all these characters. But, Unicode didn’t get involved in this representation. It just assigned a number to each character. This number is named a code point. For instance, the letter A in Unicode is associated with the code point 65 in decimal, and we refer to it as U+0041. This is the constant U+ followed by 65 in hexadecimal. As you can see, in Unicode, A is 65, exactly as in the ASCII encoding. In other words, Unicode is backward compatible with ASCII. As you’ll see soon, this is big, so keep it in mind!
Early versions of Unicode contain characters having code points less than 65,535 (0xFFFF). Java represents these characters via the 16-bit char data type. For instance, the French  (e with circumflex) is associated with the Unicode 234 decimal or U+00EA hexadecimal. In Java, we can use
(e with circumflex) is associated with the Unicode 234 decimal or U+00EA hexadecimal. In Java, we can use charAt() to reveal this for any Unicode character less than 65,535:
int e = "ê".charAt(0); // 234
String hexe = Integer.toHexString(e); // ea
We also may see the binary representation of this character:
String binarye = Integer.toBinaryString(e); // 11101010 = 234
Later, Unicode added more and more characters up to 1,114,112 (0x10FFFF). Obviously, the 16-bit Java char was not enough to represent these characters, and calling charAt() was not useful anymore.
Important note
Java 19+ supports Unicode 14.0. The java.lang.Character API supports Level 14 of the Unicode Character Database (UCD). In numbers, we have 47 new emojis, 838 new characters, and 5 new scripts. Java 20+ supports Unicode 15.0, which means 4,489 new characters for java.lang.Character.
In addition, JDK 21 has added a set of methods especially for working with emojis based on their code point. Among these methods, we have boolean isEmoji(int codePoint), boolean isEmojiPresentation(int codePoint), boolean isEmojiModifier(int codePoint), boolean isEmojiModifierBase(int codePoint), boolean isEmojiComponent(int codePoint), and boolean isExtendedPictographic(int codePoint). In the bundled code, you can find a small application showing you how to fetch all available emojis and check if a given string contains emoji. So, we can easily obtain the code point of a character via Character.codePointAt() and pass it as an argument to these methods to determine whether the character is an emoji or not.
However, Unicode doesn’t get involved in how these code points are encoded into bits. This is the job of special encoding schemes within Unicode, such as the Unicode Transformation Format (UTF) schemes. Most commonly, we use UTF-32, UTF-16, and UTF-8.
UTF-32
UTF-32 is an encoding scheme for Unicode that represents every code point on 4 bytes (32 bits). For instance, the letter A (having code point 65), which can be encoded on a 7-bit system, is encoded in UTF-32 as in the following figure next to the other two characters:

Figure 2.4: Three characters sample encoded in UTF-32
As you can see in Figure 2.4, UTF-32 uses 4 bytes (fixed length) to represent every character. In the case of the letter A, we see that UTF-32 wasted 3 bytes of memory. This means that converting an ASCII file to UTF-32 will increase its size by 4 times (for instance, a 1KB ASCII file is a 4KB UTF-32 file). Because of this shortcoming, UTF-32 is not very popular.
Java doesn’t support UTF-32 as a standard charset but it relies on surrogate pairs (introduced in the next section).
UTF-16
UTF-16 is an encoding scheme for Unicode that represents every code point on 2 or 4 bytes (not on 3 bytes). UTF-16 has a variable length and uses an optional Byte-Order Mark (BOM), but it is recommended to use UTF-16BE (BE stands for Big-Endian byte order), or UTF-16LE (LE stands for Little-Endian byte order). While more details about Big-Endian vs. Little-Endian are available at https://en.wikipedia.org/wiki/Endianness, the following figure reveals how the orders of bytes differ in UTF-16BE (left side) vs. UTF-16LE (right side) for three characters:

Figure 2.5: UTF-16BE (left side) vs. UTF-16LE (right side)
Since the figure is self-explanatory, let’s move forward. Now, we have to tackle a trickier aspect of UTF-16. We know that in UTF-32, we take the code point and transform it into a 32-bit number and that’s it. But, in UTF-16, we can’t do that every time because we have code points that don’t accommodate 16 bits. This being said, UTF-16 uses the so-called 16-bit code units. It can use 1 or 2 code units per code point. There are three types of code units, as follows:
- A code point needs a single code unit: these are 16-bit code units (covering U+0000 to U+D7FF, and U+E000 to U+FFFF)
- A code point needs 2 code units:
- The first code unit is named high surrogate and it covers 1,024 values (U+D800 to U+DBFF)
- The second code unit is named low surrogate and it covers 1,024 values (U+DC00 to U+DFFF)
A high surrogate followed by a low surrogate is named a surrogate pair. Surrogate pairs are needed to represent the so-called supplementary Unicode characters or characters having a code point larger than 65,535 (0xFFFF).
Characters such as the letter A (65) or the Chinese  (26263) have a code point that can be represented via a single code unit. The following figure shows these characters in UTF-16BE:
(26263) have a code point that can be represented via a single code unit. The following figure shows these characters in UTF-16BE:

Figure 2.6: UTF-16 encoding of A and 
This was easy! Now, let’s consider the following figure (encoding of Unicode, Smiling Face with Heart-Shaped Eyes):
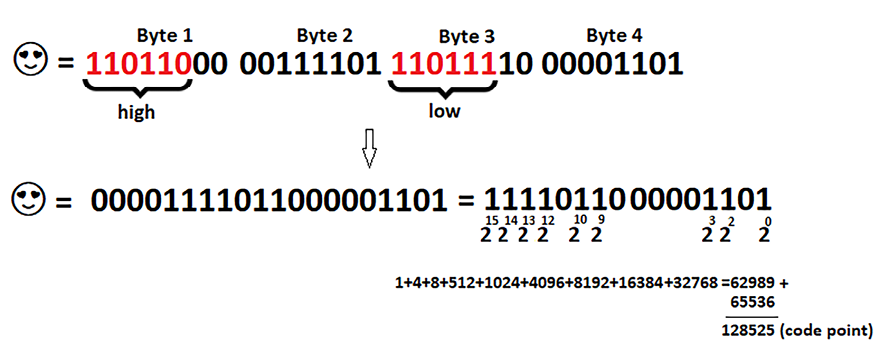
Figure 2.7: UTF-16 encoding using a surrogate pair
The character from this figure has a code point of 128525 (or, 1 F60D) and is represented on 4 bytes.
Check the first byte: the sequence of 6 bits, 110110, identifies a high surrogate.
Check the third byte: the sequence of 6 bits, 110111, identifies a low surrogate.
These 12 bits (identifying the high and low surrogates) can be dropped and we keep the rest of the 20 bits: 00001111011000001101. We can compute this number as 20 + 22 + 23 + 29 + 210 + 212 + 213 + 214 + 215 = 1 + 4 + 8 + 512 + 1024 + 4096 + 8192 + 16384 + 32768 = 62989 (or, the hexadecimal, F60D).
Finally, we have to compute F60D + 0x10000 = 1 F60D, or in decimal 62989 + 65536 = 128525 (the code point of this Unicode character). We have to add 0x10000 because the characters that use 2 code units(a surrogate pair) are always of form 1 F…
Java supports UTF-16, UTF-16BE, and UTF-16LE. Actually, UTF-16 is the native character encoding for Java.
UTF-8
UTF-8 is an encoding scheme for Unicode that represents every code point on 1, 2, 3, or 4 bytes. Having this 1- to 4-byte flexibility, UTF-8 uses space in a very efficient way.
Important note
UTF-8 is the most popular encoding scheme that dominates the Internet and applications.
For instance, we know that the code point of the letter A is 65 and it can be encoded using a 7-bit binary representation. The following figure represents this letter encoded in UTF-8:

Figure 2.8: Letter A encoded in UTF-8
This is very cool! UTF-8 has used a single byte to encode A. The first (leftmost) 0 signals that this is a single-byte encoding. Next, let’s see the Chinese character,  :
:
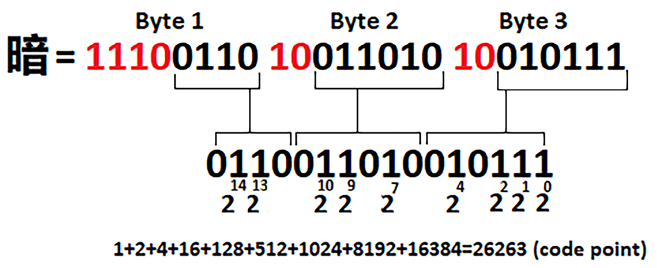
Figure 2.9: Chinese character, , encoded in UTF-8
The code point of is 26263, so UTF-8 uses 3 bytes to represent it. The first byte contains 4 bits (1110) that signal that this is a 3-byte encoding. The next two bytes start with 2 bits of 10. All these 8 bits can be dropped and we keep only the remaining 16 bits, which gives us the expected code point.
Finally, let’s tackle the following figure:

Figure 2.10: UTF-8 encoding with 4 bytes
This time, the first byte signals that this is a 4-byte encoding via 11110. The remaining 3 bytes start with 10. All these 11 bits can be dropped and we keep only the remaining 21 bits, 000011111011000001101, which gives us the expected code point, 128525.
In the following figure you can see the UTF-8 template used for encoding Unicode characters:

Figure 2.11: UTF-8 template used for encoding Unicode characters
Did you know that 8 zeros in a row (00000000 – U+0000) are interpreted as NULL? A NULL represents the end of the string, so sending it “accidentally” will be a problem because the remaining string will not be processed. Fortunately, UTF-8 prevents this issue, and sending a NULL can be done only if we effectively send the U+0000 code point.
Java and Unicode
As long as we use characters with code points less than 65,535 (0xFFFF), we can rely on the charAt() method to obtain the code point. Here are some examples:
int cp1 = "A".charAt(0); // 65
String hcp1 = Integer.toHexString(cp1); // 41
String bcp1 = Integer.toBinaryString(cp1); // 1000001
int cp2 = " ".charAt(0); // 26263
String hcp2 = Integer.toHexString(cp2); // 6697
String bcp2 = Integer.toBinaryString(cp2); // 1101100000111101
".charAt(0); // 26263
String hcp2 = Integer.toHexString(cp2); // 6697
String bcp2 = Integer.toBinaryString(cp2); // 1101100000111101
Based on these examples, we may write a helper method that returns the binary representation of strings having code points less than 65,535 (0xFFFF) as follows (you already saw the imperative version of the following functional code earlier):
public static String strToBinary(String str) {
String binary = str.chars()
.mapToObj(Integer::toBinaryString)
.map(t -> "0" + t)
.collect(Collectors.joining(" "));
return binary;
}
If you run this code against a Unicode character having a code point greater than 65,535 (0xFFFF), then you’ll get the wrong result. You’ll not get an exception or any kind of warning.
So, charAt() covers only a subset of Unicode characters. For covering all Unicode characters, Java provides an API that consists of several methods. For instance, if we replace charAt() with codePointAt(), then we obtain the correct code point in all cases, as you can see in the following figure:

Figure 2.12: charAt() vs. codePointAt()
Check out the last example, c2. Since codePointAt() returns the correct code point (128525), we can obtain the binary representation as follows:
String uc = Integer.toBinaryString(c2); // 11111011000001101
So, if we need a method that returns the binary encoding of any Unicode character, then we can replace the chars() call with the codePoints() call. The codePoints() method returns the code points of the given sequence:
public static String codePointToBinary(String str) {
String binary = str.codePoints()
.mapToObj(Integer::toBinaryString)
.collect(Collectors.joining(" "));
return binary;
}
The codePoints() method is just one of the methods provided by Java to work around code points. The Java API also includes codePointAt(), offsetByCodePoints(), codePointCount(), codePointBefore(), codePointOf(), and so on. You can find several examples of them in the bundled code next to this one for obtaining a String from a given code point:
String str1 = String.valueOf(Character.toChars(65)); // A
String str2 = String.valueOf(Character.toChars(128525));
The toChars() method gets a code point and returns the UTF-16 representation via a char[]. The string returned by the first example (str1) has a length of 1 and is the letter A. The second example returns a string of length 2 since the character having the code point 128525 needs a surrogate pair. The returned char[] contains both the high and low surrogates.
Finally, let’s have a helper method that allows us to obtain the binary representation of a string for a given encoding scheme:
public static String stringToBinaryEncoding(
String str, String encoding) {
final Charset charset = Charset.forName(encoding);
final byte[] strBytes = str.getBytes(charset);
final StringBuilder strBinary = new StringBuilder();
for (byte strByte : strBytes) {
for (int i = 0; i < 8; i++) {
strBinary.append((strByte & 128) == 0 ? 0 : 1);
strByte <<= 1;
}
strBinary.append(" ");
}
return strBinary.toString().trim();
}
Using this method is quite simple, as you can see in the following examples:
// 00000000 00000000 00000000 01000001
String r = Charsets.stringToBinaryEncoding("A", "UTF-32");
// 10010111 01100110
String r = Charsets.stringToBinaryEncoding("",
StandardCharsets.UTF_16LE.name());
You can practice more examples in the bundled code.
JDK 18 defaults the charset to UTF-8
Before JDK 18, the default charset was determined based on the operating system charset and locale (for instance, on a Windows machine, it could be windows-1252). Starting with JDK 18, the default charset is UTF-8 (Charset.defaultCharset() returns the string, UTF-8). Or, having a PrintStream instance, we can find out the used charset via the charset() method (starting with JDK 18).
But, the default charset can be explicitly set via the file.encoding and native.encoding system properties at the command line. For instance, you may need to perform such modification to compile legacy code developed before JDK 18:
// the default charset is computed from native.encoding
java -Dfile-encoding = COMPAT
// the default charset is windows-1252
java -Dfile-encoding = windows-1252
So, since JDK 18, classes that use encoding (for instance, FileReader/FileWriter, InputStreamReader/OutputStreamWriter, PrintStream, Formatter, Scanner, and URLEncoder/URLDecoder) can take advantage of UTF-8 out of the box. For instance, using UTF-8 before JDK 18 for reading a file can be accomplished by explicitly specifying this charset encoding scheme as follows:
try ( BufferedReader br = new BufferedReader(new FileReader(
chineseUtf8File.toFile(), StandardCharsets.UTF_8))) {
...
}
Accomplishing the same thing in JDK 18+ doesn’t require explicitly specifying the charset encoding scheme:
try ( BufferedReader br = new BufferedReader(
new FileReader(chineseUtf8File.toFile()))) {
...
}
However, for System.out and System.err, JDK 18+ still uses the default system charset. So, if you are using System.out/err and you see question marks (?) instead of the expected characters, then most probably you should set UTF-8 via the new properties -Dstdout.encoding and -Dstderr.encoding:
-Dstderr.encoding=utf8 -Dstdout.encoding=utf8
Or, you can set them as environment variables to set them globally:
_JAVA_OPTIONS="-Dstdout.encoding=utf8 -Dstderr.encoding=utf8"
In the bundled code you can see more examples.



