























































Channels
Channels allow goroutines to share memory by communicating, as opposed to communicating by sharing memory. When you are working with channels, you have to keep in mind that channels are two things combined together: they are synchronization tools, and they are conduits for data.
You can declare a channel by specifying its type and its capacity:
ch:=make(chan int,2)
The preceding declaration creates and initializes a channel that can carry integer values with a capacity of 2. A channel is a first-in, first-out (FIFO) conduit. That is, if you send some values to a channel, the receiver will receive those values in the order they were written. Use the following syntax to send to or receive from channels:
ch <- 1 // Send 1 to the channel <- ch // Receive a value from the channel x= <- ch // Receive value from the channel and assign it to x x:= <- ch // Receive value from the channel, declare variable x // using the same type as the value read (which is // int),and assign the value to x.
The len() and cap() functions work as expected for channels. The len() function will return the number of items waiting in the channel, and cap() will return the capacity of the channel buffer. The availability of these functions doesn’t mean the following code is correct, though:
// Don't do this!
if len(ch) > 0 {
x := <-ch
}
This code checks whether the channel has some data in it, and, seeing that it does, reads it. This code has a race condition. Even though the channel may have data in it when its length is checked, another goroutine may receive it by the time this goroutine attempts to do so. In other words, if len(ch) returns a non-zero value, it means that the channel had some values when its length was checked, but it doesn’t mean that it has some values after the len function returns.
Figure 2.3 illustrates a possible sequence of operations with this channel using two goroutines. The first goroutine sends values 1 and 2 to the channel, which are stored in the channel buffer (len(ch)=2, cap(ch)=2). Then the other goroutine receives 1. At this point, a value of 2 is the next one to be read from the channel, and the channel buffer only has one value in it. The first goroutine sends 3. The channel is full, so the operation to send 4 to the channel blocks. When the second goroutine receives the 2 value from the channel, the send by the first goroutine succeeds, and the first goroutine wakes up.
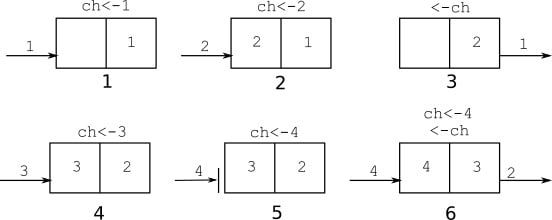
Figure 2.3 – Possible sequence of operations with a buffered channel of capacity 2
This example shows that a send operation to a channel will block until the channel is ready to accept a value. If the channel is not ready to accept the value, the send operation blocks.
Similarly, Figure 2.4 shows a blocking receive operation. The first goroutine sends 1, and the second goroutine receives it. Now len(ch)=0, so the next receive operation by the second goroutine blocks. When the first goroutine sends a value of 2 to the channel, the second goroutine receives that value and wakes up.

Figure 2.4 – Blocking receive operation
So, a receive from a channel will block until the channel is ready to provide a value.
A channel is actually a pointer to a data structure that contains its internal state, so the zero-value of a channel variable is nil. Because of that, channels must be initialized using the make keyword. If you forget to initialize a channel, it will never be ready to accept a value, or provide a value, thus reading from or writing to a nil channel will block indefinitely.
The Go garbage collector will collect channels that are no longer in use. If there are no goroutines that directly or indirectly reference a channel, the channel will be garbage collected even if its buffer has elements in it. You do not need to close channels to make them eligible for garbage collection. In fact, closing a channel has more significance than just cleaning up resources.
You may have noticed sending and receiving data using channels is a one-to-one operation: one goroutine sends, and another receives the data. It is not possible to send data that will be received by many goroutines using one channel. However, closing a channel is a one-time broadcast to all receiving goroutines. In fact, that is the only way to notify multiple goroutines at once. This is a very useful feature, especially when developing servers. For example, the net/http package implements a Server type that handles each request in a separate goroutine. An instance of context.Context is passed to each request handler that contains a Done() channel. If, for example, the client closes the connection before the request handler can prepare the response, the handler can check to see whether the Done() channel is closed and terminate processing prematurely. If the request handler creates goroutines to prepare the response, it should pass the same context to these goroutines, and they will all receive the cancellation notice once the Done() channel closes. We will talk about how to use context.Context later in the book.
Receiving from a closed channel is a valid operation. In fact, a receive from a closed channel will always succeed with the zero value of the channel type. Writing to a closed channel is a bug: writing to a closed channel will always panic.
Figure 2.5 depicts how closing a channel works. This example starts with one goroutine sending 1 and 2 to the channel and then closing it. After the channel is closed, sending more data to it will cause a panic. The channel keeps the information that the channel is closed as one of the values in its buffer, so receive operations can still continue. The goroutine receives the 1 and 2 values, and then every read will return the zero value for the channel type, in this case, the 0 integer.

Figure 2.5 – Closing a channel
For a receiver, it is usually important to know whether the channel was closed when the read happened. Use the following form to test the channel state:
y, ok := <-ch
This form of channel receive operation will return the received value and whether or not the value was a real receive or whether the channel is closed. If ok=true, the value was received. If ok=false, the channel was closed, and the value is simply the zero value. A similar syntax does not exist for sending because sending to a closed channel will panic.
What happens when a channel is created without a buffer? Such a channel is called an unbuffered channel, and behaves in the same way as a buffered channel, but with len(ch)=0 and cap(ch)=0. Thus, a send operation will block until another goroutine receives from it. A receive operation will block until another goroutine sends to it. In other words, an unbuffered channel is a way to transfer data between goroutines atomically. Let’s look at how unbuffered channels are used to send messages and to synchronize goroutines using the following snippet:
1: chn := make(chan bool) // Create an unbuffered channel
2: go func() {
3: chn <- true // Send to channel
4: }()
5: go func() {
6: var y bool
7: y <-chn // Receive from channel
8: fmt.Println(y)
9: }()
Line 1 creates an unbuffered bool channel.
Line 2 creates the G1 goroutine and line 5 creates the G2 goroutine.
There are two possible runs at this point: G1 attempts to send (line 3) before G2 is ready to receive (line 7), or G2 attempts to receive (line 7) before G1 is ready to send (line 3). The first diagram in Figure 2.6 illustrates the case where G1 runs first. At line 3, G1 attempts to send to the channel. However, at this point, G2 is still not ready to receive. Since the channel is unbuffered and there are no receivers available, G1 blocks.
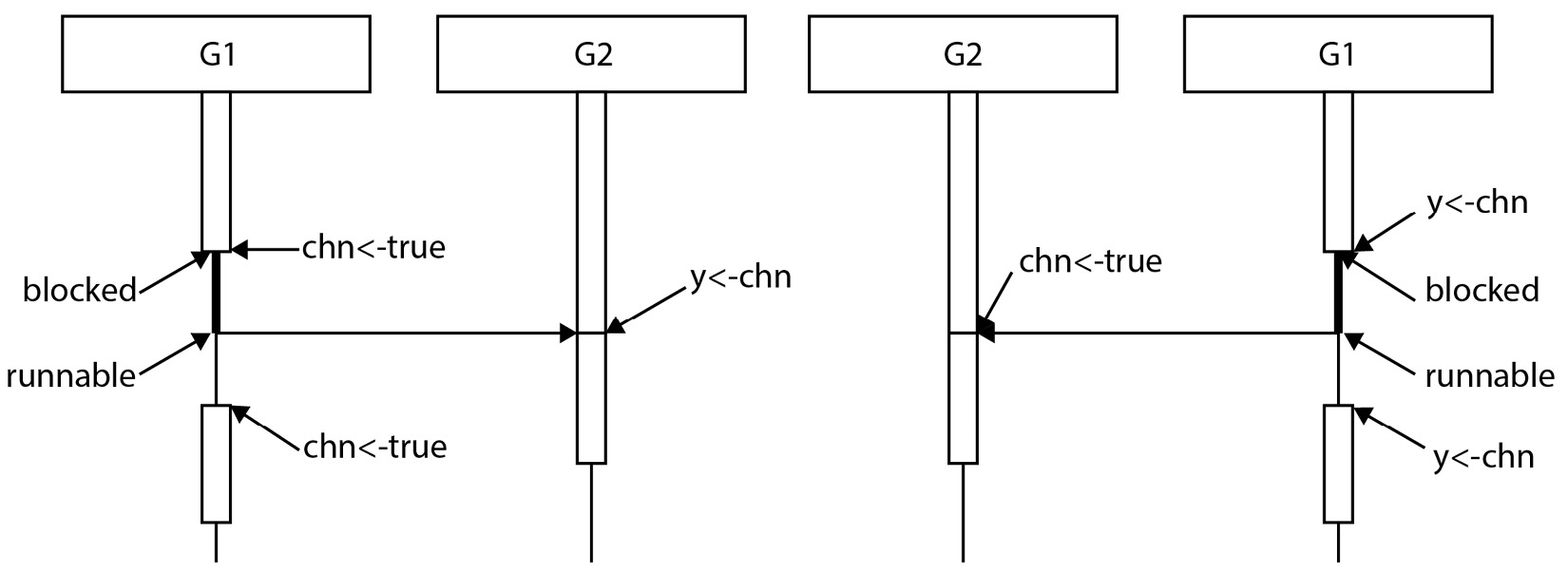
Figure 2.6 – Two possible runs using an unbuffered channel
After a while, G2 executes line 7. This is a channel receive operation, and there is a goroutine (G1) waiting to send to it. Because of this, the first G1 is unblocked and sends the value to the channel, and G2 receives it without blocking. It is now up to the scheduler to decide when G1 can run.
The second possible scenario, where G2 runs first, is shown in Figure 2.6 on the right-hand side. Since G1 is not yet sent to the channel, G2 blocks. When G1 is ready to send, G2 is already waiting to receive, so G1 does not block and sends the value, and, G2 unblocks and receives the value. The scheduler decides when G2 can run again.
Note that an unbuffered channel acts as a synchronization point between two goroutines. Both goroutines must align for the message transfer to happen.
A word of caution is necessary here. Transferring a value from one goroutine to another transfers a copy of the value. So, if a goroutine runs ch<-x and sends the value of x, and another goroutine receives it with y<-ch, then this is equivalent to y=x, with additional synchronization guarantees. The crucial point here is that it does not transfer the ownership of the value. If the transferred value is a pointer, you end up with a shared memory system. Consider the following program:
type Data struct {
Values map[string]interface{}
}
func processData(data Data,pipeline chan Data) {
data.Values = getInitialValues() // Initialize the
// map
pipeline <- data // Send data to another
// goroutine for processing
data.Values["status"] = "sent" // Possible data
// race!
}
The processData function initializes the Values map and then sends the data to another goroutine for processing. But a map is actually a pointer to a complex map structure. When data is sent through the channel, the receiver receives a copy of the pointer to the same map structure. If the receiving goroutine reads from or writes to the Values map, that operation will be concurrent with the write operation shown in the preceding code snippet. That is a data race.
So, as a convention, it is a good practice to assume that if a value is sent via a channel, the ownership of the value is also transferred, and you should not use a variable after sending it via a channel. You can redeclare it or throw it away. If you have to, include an additional mechanism, such as a mutex, so you can coordinate goroutines after the value becomes shared.
A channel can be declared with a direction. Such channels are useful as function arguments, or as function return values:
var receiveOnly <-chan int // Can receive, cannot // write or close var sendOnly chan<- int // Can send, cannot read // or close
The benefit of this declaration is type safety: a function that takes a send-only channel as an argument cannot receive from or close that channel. A function that gets a receive-only channel returned from a function can only receive data from that channel but cannot send data or close it, for example:
func streamResults() <-chan Data {
resultCh := make(chan Data)
go func() {
defer close(resultCh)
results := getResults()
for _, result := range results {
resultCh <- result
}
}()
return resultCh
}
This is a typical way of streaming the results of a query to the caller. The function starts by declaring a bidirectional channel but returns it as a directional one. This tells the caller that it is only supposed to read from that channel. The streaming function will write to it and close it when everything is done.
So far, we have looked at channels in the context of two goroutines. But channels can be used to communicate with many goroutines. When multiple goroutines attempt to send to a channel or when multiple goroutines attempt to read from a channel, they are scheduled randomly. There are many implications of this simple rule.
You can create many worker goroutines, all receiving from a channel. Another goroutine sends work items to the channel, and each work item will be picked up by an available worker goroutine and processed. This is useful for worker pool patterns where many goroutines work on a list of tasks concurrently. Then, you can have one goroutine reading from a channel that is written by many worker goroutines. The reading goroutine will collect the results of computations performed by those goroutines. The following program illustrates this idea:
1: workCh := make(chan Work)
2: resultCh := make(chan Result)
3: done := make(chan bool)
4:
5: // Create 10 worker goroutines
6: for i := 0; i < 10; i++ {
7: go func() {
8: for {
9: // Get work from the work channel
10: work := <- workCh
11: // Compute result
12: // Send the result via the result channel
13: resultCh <- result
14: }
15: }()
16: }
17: results := make([]Result, 0)
18: go func() {
19: // Collect all the results.
20: for _, i := 0; i < len(workQueue); i++ {
21: results = append(results, <-resultCh)
22: }
23: // When all the results are collected, notify the done channel
24: done <- true
25: }()
26: // Send all the work to the workers
27: for _, work := range workQueue {
28: workCh <- work
29: }
30: // Wait until everything is done
31: <- done
This is an artificial example that illustrates how multiple channels can be used to coordinate work. There are two channels used for passing data around, workCh for sending work to goroutines, and resultCh to collect computed results. There is one channel, the done channel, to control program flow. This is required because we would like to wait until all the results are computed and stored in the slice before proceeding. The program starts by creating the worker goroutines and then creating a separate goroutine to collect the results. All these goroutines will be blocked, waiting to receive data (lines 10 and 21). The for loop at the main body will then iterate through the work queue and send the work items to the waiting worker goroutines (line 28). Each worker will receive the work (line 10), compute a result, and send the result to the collector goroutine (line 13), which will place them in a slice. The main goroutine will send all the work items and then block until it receives a value from the done channel (line 31), which will come after all the results are collected (line 24). As you can see, there is an ordering of channel operations in this program: 28 < 10 < 13 < 21 < 24 < 31. These types of orderings will be crucial in analyzing the concurrent execution of programs.
You may have noticed that in this program, all the worker goroutines leak; that is, they were never stopped. A good way to stop them is to close the work channel once we’re done writing to it. Then we can check whether the channel is closed in the worker:
for _, work := range workQueue {
workCh <- work
}
close(workCh)
This will notify the workers that the work queue has been exhausted and the work channel is closed. We change the workers to check for this, as shown in the following code:
work, ok := <- workCh
if !ok { // Is the channel closed?
return // Yes. Terminate
}
There is a more idiomatic way of doing this. You can range over a channel in a for loop, which will exit when the channel is closed:
go func() {
for work := range workCh { // Receive until channel
//closes
// Compute result
// Send the result via the result channel
resultCh <- result
}
}()
With this change, all the running worker goroutines will terminate once the work channel is closed.
We will explore these patterns in greater detail later in the book. However, for now, these patterns bring up another question: how do we work with multiple channels? To answer this, we have to introduce the select statement. The following definition is from the Go language specification:
A select statement chooses which of a set of possible send or receive operations proceed.
The select statement looks like a switch-case statement:
select {
case x := <-ch1:
// Received x from ch1
case y := <-ch2:
// Received y from ch2
case ch3 <- z:
// Sent z to ch3
default:
// Optional default, if none of the other
// operations can proceed
}
At a high level, the select statement chooses one of the send or receive operations that can proceed and then runs the block corresponding to the chosen operation. Note the past tense in the previous comments. The block for the reception of x from ch1 runs only after x is received from ch1. If there are multiple send or receive operations that can proceed, the select statement chooses one randomly. If there are none, the select statement chooses the default option. If a default option does not exist, the select statement blocks until one of the channel operations becomes available.
It follows from the preceding definitions that the following blocks indefinitely:
select {}
Using the default option in a select statement is useful for non-blocking sends and receives. The default option will only be chosen when all other options are not ready. The following is a non-blocking send operation:
select {
case ch<-x:
sent = true
default:
}
The preceding select statement will test whether the ch channel is ready for sending data. If it is ready, the x value will be sent. If it is not, the execution will continue with the default option. Note that this only means that the ch channel was not ready for sending when it was tested. The moment the default option starts running, send to ch may become available.
Similarly, the following is a non-blocking receive:
select {
case x = <- ch:
received = true
default:
}
One of the frequently asked questions about goroutines is how to stop them. As explained before, there is no magic function that will stop a goroutine in the middle of its operation. However, using a non-blocking receive and a channel to signal a stop request, you can terminate a long-running goroutine gracefully:
1: stopCh := make(chan struct{})
2: requestCh := make(chan Request)
3: resultCh := make(chan Result)
4: go func() {
5: for { // Loop indefinitely
6: var req Request
7: select {
8: case req = <-requestCh:
9: // Received a request to process
10: case <-stopCh:
11: // Stop requested, cleanup and return
12: cleanup()
13: return
14: }
15: // Do some processing
16: someLongProcessing(req)
17: // Check if stop requested before another long task
18: select {
19: case <-stopCh:
20: // Stop requested, cleanup and return
21: cleanup()
22: return
23: default:
24: }
25: // Do more processing
26: result := otherLongProcessing(req)
27: select {
28: // Wait until resultCh becomes sendable, or stop requested
29: case resultCh <- result:
30: // Result is sent
31: case <-stopCh:
32: // Stop requested
33: cleanup()
34: return
35: }
36: }
37: }()
The preceding function works with three channels, one to receive requests from requestCh, one to send results to resultCh, and one to notify the goroutine of a request to stop stopCh. To send a stop request, the main goroutine simply closes the stop channel, which broadcasts all worker goroutines a request to stop.
The select statement at line 7 blocks until one of the channels, the request channel or the stop channel, has data to receive. If it receives from the stop channel, the goroutine cleans up and returns. If a request is received, then the goroutine processes it. The select statement at line 18 is a non-blocking read from the stop channel. If during the processing, stop is requested, it is detected here, and the goroutine can clean up and return. Otherwise, the processing continues, and a result is computed. The select statement at line 27 checks whether the listening goroutine is ready to receive the result or whether stop is requested. If the listening goroutine is ready, the result is sent, and the loop restarts. If the listening goroutine is not ready but stop is requested, the goroutine cleans up and returns. This select is a blocking select, so it will wait until it can transmit the result or receive the stop request and return. Note that for the select statement at line 27, if both the result channel and the stop channel are enabled, the choice is random. The goroutine may send the result channel and continue with the loop even if stop is requested. The same situation applies to the select statement in line 7. If both the request channel and the stop channel are enabled, the select statement may choose to read the request instead of stopping.
This example brings up a good point: in a select statement, all enabled channels have the same likelihood of being chosen; that is, there is no channel priority. Under heavy load, the previous goroutine may process many requests even after a stop is requested. One way to deal with such a situation is to double-check the higher-priority channel:
select {
case req = <-requestCh:
// Received a request to process
// Check if also stop requested
select {
case <- stopCh:
cleanup()
return
default:
}
case <-stopCh:
// Stop requested, cleanup and return
cleanup()
return
}
This will re-check the stop request after receiving it from the request channel and return if stop is requested.
Also, note that the preceding implementations will lose the received request if they are stopped. If that is not desired side effect, then the cleanup process should put the request back into a queue.
Channels can be used to gracefully terminate a program based on a signal. This is important in a containerized environment where the orchestration platform may terminate a running container using a signal. The following code snippet illustrates this scenario:
var term chan struct{}
func main() {
term = make(chan struct{})
sig := make(chan os.Signal, 1)
go func() {
<-sig
close(term)
}()
signal.Notify(sig, syscall.SIGINT, syscall.SIGTERM)
go func() {
for {
select {
case term:
return
default:
}
// Do work
}
}()
// ...
}
This program will handle the interrupt and termination signals coming from the operating system by closing a global term channel. All workers check for the term channel and return whether the program is terminating. This gives the application the opportunity to perform cleanup operations before the program terminates. The channel that listens to the signals must be buffered because the runtime uses a non-blocking write to send signal messages.
Finally, let’s take a closer look at some of the interesting properties of select statements that may cause some misunderstandings. For example, the following is a valid select statement. When the channel becomes ready to receive, the select statement will choose one of the cases randomly:
select {
case <-ch:
case <-ch:
}
It is possible that the channel send or receive operation is not the first thing in a case block, for example:
func main() {
var i int
f := func() int {
i++
return i
}
ch1 := make(chan int)
ch2 := make(chan int)
select {
case ch1 <- f():
case ch2 <- f():
default:
}
fmt.Println(i)
}
The preceding program uses a non-blocking send. There are no other goroutines, so the channel send operations cannot be chosen, but the f() function is still called for both cases. This program will print 2.
A more complicated select statement is as follows:
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
ch2 <- 1
}()
go func() {
fmt.Println(<-ch1)
}()
select {
case ch1 <- <-ch2:
time.Sleep(time.Second)
default:
}
}
In this program, there is a goroutine that sends to the ch2 channel, and a goroutine that receives from ch1. Both channels are unbuffered, so both goroutines will block at the channel operation. But the select statement has a case that receives a value from ch2 and sends it to ch1. What exactly is going to happen? Will the select statement make its decision based on the readiness of ch1 or ch2?
The select statement will immediately evaluate the arguments to the channel send operation. That means <-ch2 will run, without looking at whether it is ready to receive or not. If ch2 is not ready to receive, the select statement will block until it becomes ready even though there is a default case. Once the message from ch2 is received, the select statement will make its choice: if ch1 is ready to send the value, it will send it. If not, the default case will be selected.










