























































Data Discretization
So far, we have done the categorical data treatment using encoding and numerical data treatment using scaling.
Data discretization is the process of converting continuous data into discrete buckets by grouping it. Discretization is also known for easy maintainability of the data. Training a model with discrete data becomes faster and more effective than when attempting the same with continuous data. Although continuous-valued data contains more information, huge amounts of data can slow the model down. Here, discretization can help us strike a balance between both. Some famous methods of data discretization are binning and using a histogram. Although data discretization is useful, we need to effectively pick the range of each bucket, which is a challenge.
The main challenge in discretization is to choose the number of intervals or bins and how to decide on their width.
Here we make use of a function called pandas.cut(). This function is useful to achieve the bucketing and sorting of segmented data.
Exercise 11: Discretization of Continuous Data
In this exercise, we will load the Student_bucketing.csv dataset and perform bucketing. The dataset consists of student details such as Student_id, Age, Grade, Employed, and marks. Follow these steps to complete this exercise:
Note
The Student_bucketing.csv dataset can be found here: https://github.com/TrainingByPackt/Data-Science-with-Python/blob/master/Chapter01/Data/Student_bucketing.csv.
- Open a Jupyter notebook and add a new cell. Write the following code to import the required libraries and load the dataset into a pandas dataframe:
import pandas as pd
dataset = "https://github.com/TrainingByPackt/Data-Science-with-Python/blob/master/Chapter01/Data/Student_bucketing.csv"
df = pd.read_csv(dataset, header = 0)
- Once we load the dataframe, display the first five rows of the dataframe. Add the following code to do this:
df.head()
The preceding code generates the following output:
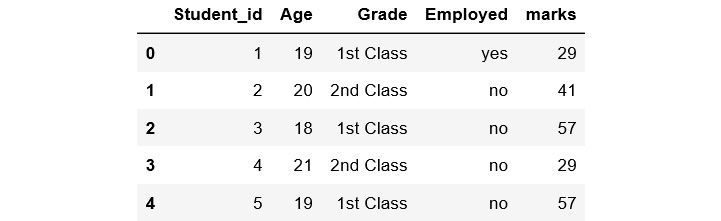
Figure 1.47: First five rows of the dataframe
- Perform bucketing using the pd.cut() function on the marks column and display the top 10 columns. The cut() function takes parameters such as x, bins, and labels. Here, we have used only three parameters. Add the following code to implement this:
df['bucket']=pd.cut(df['marks'],5,labels=['Poor','Below_average','Average','Above_Average','Excellent'])
df.head(10)
The preceding code generates the following output:
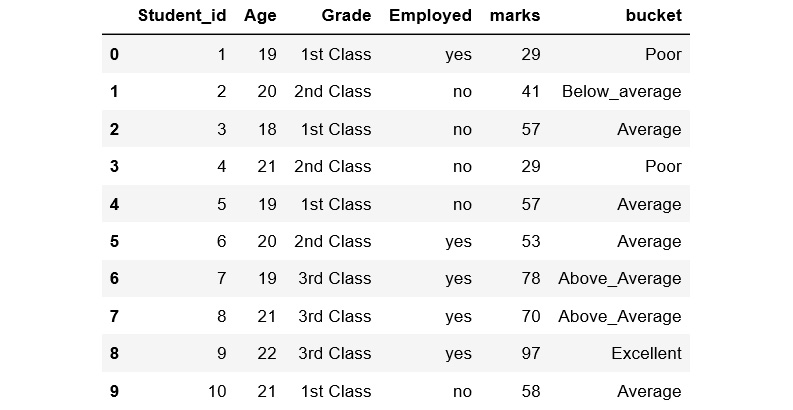
Figure 1.48: Marks column with five discrete buckets
In the preceding code, the first parameter represents an array. Here, we have selected the marks column as an array from the dataframe. 5 represents the number of bins to be used. As we have set bins to 5, the labels need to be populated accordingly with five values: Poor, Below_average, Average, Above_average, and Excellent. In the preceding figure, we can see the whole of the continuous marks column is put into five discrete buckets. We have learned how to perform bucketing.
We have now covered all the major tasks involved in pre-processing. In the next section, we'll look in detail at how to train and test your data.






















