






















































Introduction to Spring Cloud
So far, we have seen how we can use Spring Boot to build microservices with well-documented APIs, along with Spring WebFlux and springdoc-openapi; persist data in MongoDB and SQL databases using Spring Data for MongoDB and JPA; build reactive microservices either as non-blocking APIs using Project Reactor or as event-driven asynchronous services using Spring Cloud Stream with RabbitMQ or Kafka, together with Docker; and manage and test a system landscape consisting of microservices, databases, and messaging systems.
Now, it's time to see how we can use Spring Cloud to make our services production-ready; that is scalable, robust, configurable, secure, and resilient.
In this chapter, we will introduce you to how Spring Cloud can be used to implement the following design patterns from Chapter 1, Introduction to Microservices, in the Design patterns for microservices section:
- Service discovery
- Edge server
- Centralized configuration
- Circuit breaker
- Distributed tracing
Technical requirements
This chapter does not contain any source code, and so no tools need to be installed.
The evolution of Spring Cloud
In its initial 1.0 release in March 2015, Spring Cloud was mainly a wrapper around tools from Netflix OSS, which are as follows:
- Netflix Eureka, a discovery server
- Netflix Ribbon, a client-side load balancer
- Netflix Zuul, an edge server
- Netflix Hystrix, a circuit breaker
The initial release of Spring Cloud also contained a configuration server and integration with Spring Security that provided OAuth 2.0 protected APIs. In May 2016, the Brixton release (v1.1) of Spring Cloud was made generally available. With the Brixton release, Spring Cloud got support for distributed tracing based on Spring Cloud Sleuth and Zipkin, which originated from Twitter. These initial Spring Cloud components could be used to implement the preceding design patterns. For more details, see https://spring.io/blog/2015/03/04/spring-cloud-1-0-0-available-now and https://spring.io/blog/2016/05/11/spring-cloud-brixton-release-is-available.
Since its inception, Spring Cloud has grown considerably over the years and has added support for the following, among others:
- Service discovery and centralized configuration based on HashiCorp Consul and Apache Zookeeper
- Event-driven microservices using Spring Cloud Stream
- Cloud providers such as Microsoft Azure, Amazon Web Services, and Google Cloud Platform
See https://spring.io/projects/spring-cloud for a complete list of tools.
Since the release of Spring Cloud Greenwich (v2.1) in January 2019, some of the Netflix tools mentioned previously have been placed in maintenance mode in Spring Cloud.
The reason for this is a mixture of Netflix no longer adding new features to some of the tools and Spring Cloud adding better alternatives. The following replacements are recommended by the Spring Cloud project:
|
Current component |
Replaced by |
|
Netflix Hystrix |
Resilience4j |
|
Netflix Hystrix Dashboard/Netflix Turbine |
Micrometer and monitoring system |
|
Netflix Ribbon |
Spring Cloud LoadBalancer |
|
Netflix Zuul |
Spring Cloud Gateway |
For more details, see:
- https://spring.io/blog/2019/01/23/spring-cloud-greenwich-release-is-now-available
- https://github.com/Netflix/Hystrix#hystrix-status
- https://github.com/Netflix/ribbon#project-status-on-maintenance
With the release of Spring Cloud Ilford (v2020.0.0) in December 2020, the only remaining Netflix component in Spring Cloud is Netflix Eureka.
In this book, we will use the replacement alternatives to implement the design patterns mentioned previously. The following table maps each design pattern to the software components that will be used to implement it:
|
Design pattern |
Software component |
|
Service discovery |
Netflix Eureka and Spring Cloud LoadBalancer |
|
Edge server |
Spring Cloud Gateway and Spring Security OAuth |
|
Centralized configuration |
Spring Cloud Configuration Server |
|
Circuit breaker |
Resilience4j |
|
Distributed tracing |
Spring Cloud Sleuth and Zipkin |
Now, let's go through the design patterns and introduce the software components that will be used to implement them!
Using Netflix Eureka for service discovery
Service discovery is probably the most important support function required to make a landscape of cooperating microservices production ready. As we already described in Chapter 1, Introduction to Microservices, in the Service discovery section, a service discovery service (or a discovery service as an abbreviation) can be used to keep track of existing microservices and their instances.
The first discovery service that Spring Cloud supported was Netflix Eureka.
We will use this in Chapter 9, Adding Service Discovery Using Netflix Eureka, along with a load balancer based on Spring Cloud LoadBalancer.
We will see how easy it is to register microservices with Netflix Eureka when using Spring Cloud. We will also learn how a client can send HTTP requests, such as a call to a RESTful API, to one of the instances registered in Netflix Eureka. In addition, the chapter will cover how to scale up the number of instances of a microservice, and how requests to a microservice will be load-balanced over its available instances (based on, by default, round-robin scheduling).
The following screenshot demonstrates the web UI from Eureka, where we can see what microservices we have registered:
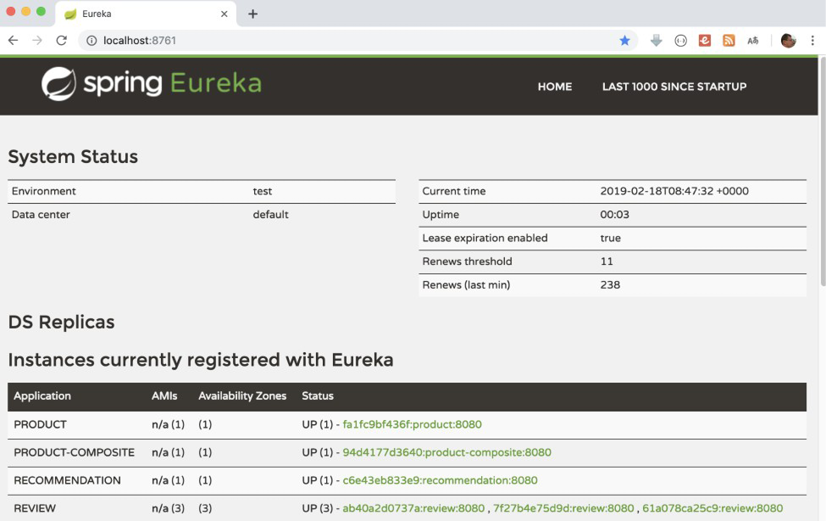
Figure 8.1: Viewing microservices currently registered with Eureka
From the preceding screenshot, we can see that the review service has three instances available, while the other three services only have one instance each.
With Netflix Eureka introduced, let's introduce how Spring Cloud can help to protect a microservices system landscape using an edge server.
Using Spring Cloud Gateway as an edge server
Another very important support function is an edge server. As we already described in Chapter 1, Introduction to Microservices, in the Edge server section, it can be used to secure a microservice landscape, which involves hiding private services from external usage and protecting public services when they're used by external clients.
Initially, Spring Cloud used Netflix Zuul v1 as its edge server. Since the Spring Cloud Greenwich release, it's recommended to use Spring Cloud Gateway instead. Spring Cloud Gateway comes with similar support for critical features, such as URL path-based routing and the protection of endpoints via the use of OAuth 2.0 and OpenID Connect (OIDC).
One important difference between Netflix Zuul v1 and Spring Cloud Gateway is that Spring Cloud Gateway is based on non-blocking APIs that use Spring 5, Project Reactor, and Spring Boot 2, while Netflix Zuul v1 is based on blocking APIs. This means that Spring Cloud Gateway should be able to handle larger numbers of concurrent requests than Netflix Zuul v1, which is important for an edge server that all external traffic goes through.
The following diagram shows how all requests from external clients go through Spring Cloud Gateway as an edge server. Based on URL paths, it routes requests to the intended microservice:
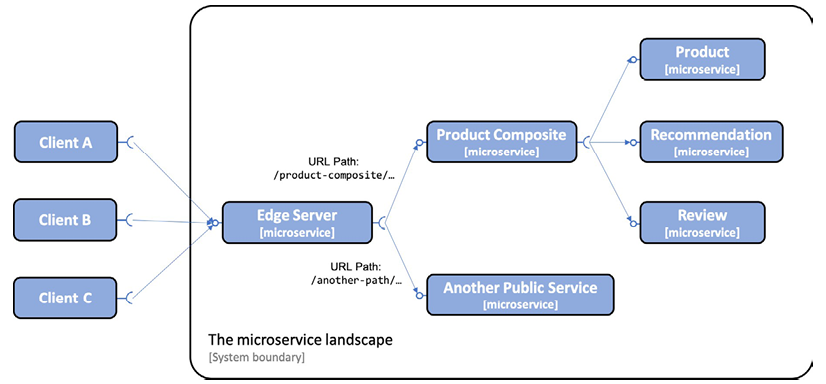
Figure 8.2: Requests being routed through an edge server
In the preceding diagram, we can see how the edge server will send external requests that have a URL path that starts with /product-composite/ to the Product Composite microservice. The core services Product, Recommendation, and Review are not reachable from external clients.
In Chapter 10, Using Spring Cloud Gateway to Hide Microservices Behind an Edge Server, we will look at how to set up Spring Cloud Gateway with our microservices.
In Chapter 11, Securing Access to APIs, we will see how we can use Spring Cloud Gateway together with Spring Security OAuth2 to protect access to the edge server using OAuth 2.0 and OIDC. We will also see how Spring Cloud Gateway can propagate identity information of the caller down to our microservices, for example, the username or email address of the caller.
With Spring Cloud Gateway introduced, let's see how Spring Cloud can help to manage the configuration of a system landscape of microservices.
Using Spring Cloud Config for centralized configuration
To manage the configuration of a system landscape of microservices, Spring Cloud contains Spring Cloud Config, which provides the centralized management of configuration files according to the requirements described in Chapter 1, Introduction to Microservices, in the Central configuration section.
Spring Cloud Config supports storing configuration files in a number of different backends, such as the following:
- A Git repository, for example, on GitHub or Bitbucket
- A local filesystem
- HashiCorp Vault
- A JDBC database
Spring Cloud Config allows us to handle configuration in a hierarchical structure; for example, we can place common parts of the configuration in a common file and microservice-specific settings in separate configuration files.
Spring Cloud Config also supports detecting changes in the configuration and pushing notifications to the affected microservices. It uses Spring Cloud Bus to transport the notifications. Spring Cloud Bus is an abstraction on top of Spring Cloud Stream that we are already familiar with; that is, it supports the use of either RabbitMQ or Kafka as the messaging system for transporting notifications out of the box.
The following diagram illustrates the cooperation between Spring Cloud Config, its clients, a Git repository, and Spring Cloud Bus:
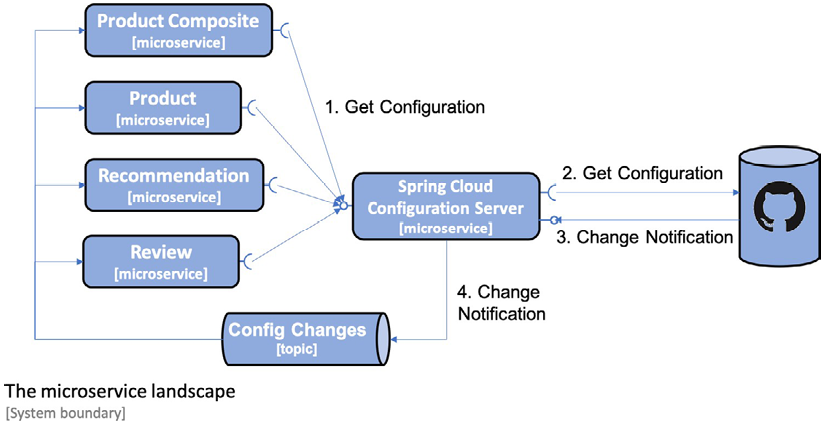
Figure 8.3: How Spring Cloud Config fits into the microservice landscape
The diagram shows the following:
- When the microservices start up, they ask the configuration server for its configuration.
- The configuration server gets the configuration from, in this case, a Git repository.
- Optionally, the Git repository can be configured to send notifications to the configuration server when Git commits are pushed to the Git repository.
- The configuration server will publish change events using Spring Cloud Bus. The microservices that are affected by the change will react and retrieve its updated configuration from the configuration server.
Finally, Spring Cloud Config also supports the encryption of sensitive information in the configuration, such as credentials.
We will learn about Spring Cloud Config in Chapter 12, Centralized Configuration.
With Spring Cloud Config introduced, let's see how Spring Cloud can help make microservices more resilient to failures that happen from time to time in a system landscape.
Using Resilience4j for improved resilience
In a fairly large-scaled system landscape of cooperating microservices, we must assume that there is something going wrong all of the time. Failures must be seen as a normal state, and the system landscape must be designed to handle it!
Initially, Spring Cloud came with Netflix Hystrix, a well-proven circuit breaker. But as already mentioned above, since the Spring Cloud Greenwich release, it is recommended to replace Netflix Hystrix with Resilience4j. Resilience4j is an open source-based fault tolerance library. It comes with a larger range of fault tolerance mechanisms compared to Netflix Hystrix:
- Circuit breaker is used to prevent a chain of failure reaction if a remote service stops responding.
- Rate limiter is used to limit the number of requests to a service during a specified time period.
- Bulkhead is used to limit the number of concurrent requests to a service.
- Retries are used to handle random errors that might happen from time to time.
- Time limiter is used to avoid waiting too long for a response from a slow or not responding service.
You can discover more about Resilience4j at https://github.com/resilience4j/resilience4j.
In Chapter 13, Improving Resilience Using Resilience4j, we will focus on the circuit breaker in Resilience4j. It follows the classic design of a circuit breaker, as illustrated in the following state diagram:
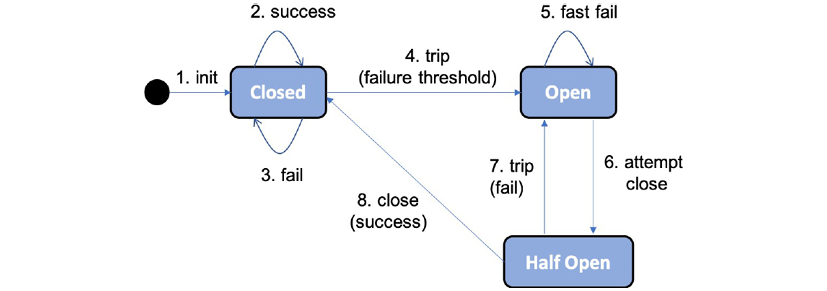
Figure 8.4: Circuit breaker state diagram
Let's take a look at the state diagram in more detail:
- A circuit breaker starts as Closed, allowing requests to be processed.
- As long as the requests are processed successfully, it stays in the Closed state.
- If failures start to happen, a counter starts to count up.
- If a threshold of failures is reached within a specified period of time, the circuit breaker will trip, that is, go to the Open state, not allowing further requests to be processed. Both the threshold of failures and the period of time are configurable.
- Instead, a request will Fast Fail, meaning it will return immediately with an exception.
- After a configurable period of time, the circuit breaker will enter a Half Open state and allow one request to go through, as a probe, to see whether the failure has been resolved.
- If the probe request fails, the circuit breaker goes back to the Open state.
- If the probe request succeeds, the circuit breaker goes to the initial Closed state, allowing new requests to be processed.
Sample usage of the circuit breaker in Resilience4j
Let's assume we have a REST service, called myService, that is protected by a circuit breaker using Resilience4j.
If the service starts to produce internal errors, for example, because it can't reach a service it depends on, we might get a response from the service such as 500 Internal Server Error. After a number of configurable attempts, the circuit will open and we will get a fast failure that returns an error message such as CircuitBreaker 'myService' is open. When the error is resolved and we make a new attempt (after the configurable wait time), the circuit breaker will allow a new attempt as a probe. If the call succeeds, the circuit breaker will be closed again; that is, operating normally.
When using Resilience4j together with Spring Boot, we will be able to monitor the state of the circuit breakers in a microservice using its Spring Boot Actuator health endpoint. We can, for example, use curl to see the state of the circuit breaker, myService:
curl $HOST:$PORT/actuator/health -s | jq .components.circuitBreakers
If it operates normally, that is, the circuit is closed, it will respond with something such as the following:
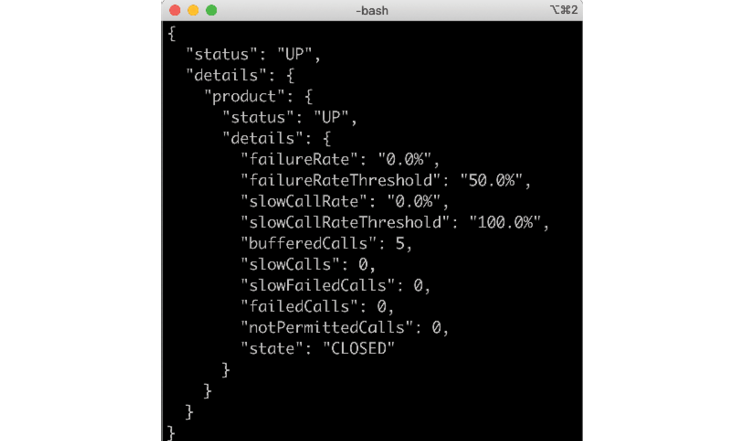
Figure 8.5: Closed circuit response
If something is wrong and the circuit is open, it will respond with something such as the following:
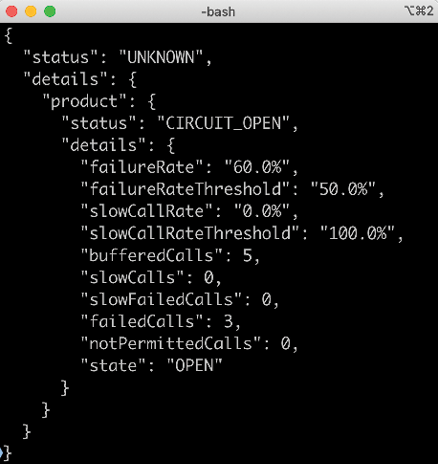
Figure 8.6: Open circuit response
With Resilience4j introduced, we have seen an example of how the circuit breaker can be used to handle errors for a REST client. Let's wrap up this chapter with an introduction to how Spring Cloud can be used for distributed tracing.
Using Spring Cloud Sleuth and Zipkin for distributed tracing
To understand what is going on in a distributed system such as a system landscape of cooperating microservices, it is crucial to be able to track and visualize how requests and messages flow between microservices when processing an external call to the system landscape.
Refer to Chapter 1, Introduction to Microservices, in the Distributed tracing section, for more information on this subject.
Spring Cloud comes with Spring Cloud Sleuth, which can mark requests and messages/events that are part of the same processing flow with a common correlation ID.
Spring Cloud Sleuth can also decorate log records with correlation IDs to make it easier to track log records from different microservices that come from the same processing flow. Zipkin is a distributed tracing system (http://zipkin.io) that Spring Cloud Sleuth can send tracing data to for storage and visualization. Later on, in Chapter 19, Centralized Logging with the EFK Stack, we will learn how to find and visualize log records from one and the same processing flow using the correlation ID.
The infrastructure for handling distributed tracing information in Spring Cloud Sleuth and Zipkin is based on Google Dapper (https://ai.google/research/pubs/pub36356). In Dapper, the tracing information from a complete workflow is called a trace tree, and subparts of the tree, such as the basic units of work, are called spans. Spans can, in turn, consist of sub-spans, which form the trace tree. A correlation ID is called TraceId, and a span is identified by its own unique SpanId, along with the TraceId of the trace tree it belongs to.
A short history lesson regarding the evolution of standards (or at least commons efforts on establishing open de facto standards) for implementing distributed tracing:
Google published the paper on Dapper back in 2010, after using it internally since 2005.
In 2016, the OpenTracing project joined CNCF. OpenTracing is heavily influenced by Dapper and provides vendor-neutral APIs and language-specific libraries for instrumenting distributed tracing.
In 2019, the OpenTracing project merged with the OpenCensus project, forming a new CNCF project, OpenTelemetry. The OpenCensus project delivers a set of libraries for collecting metrics and distributed traces.
Suggested URLs for further reading:
- https://opentracing.io
- https://opentelemetry.io
- https://opencensus.io
- Spring Cloud Sleuth support for OpenTracing: https://docs.spring.io/spring-cloud-sleuth/docs/current/reference/html/project-features.html#features-brave-opentracing
- Spring Cloud Sleuth incubator support for OpenTelemetry: https://github.com/spring-cloud-incubator/spring-cloud-sleuth-otel
For the scope of this book, we will use the direct integration between Spring Cloud Sleuth and Zipkin.
Spring Cloud Sleuth can send requests to Zipkin either synchronously over HTTP or asynchronously using either RabbitMQ or Kafka. To avoid creating runtime dependencies on the Zipkin server from our microservices, we prefer sending trace information to Zipkin asynchronously using either RabbitMQ or Kafka. This is illustrated by the following diagram:
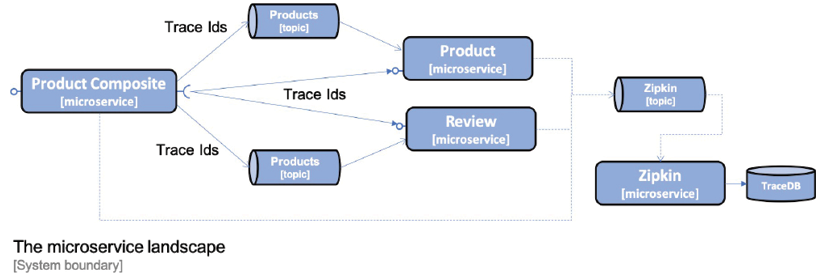
Figure 8.7: Sending trace information to Zipkin asynchronously
In Chapter 14, Understanding Distributed Tracing, we will see how we can use Spring Cloud Sleuth and Zipkin to trace the processing that goes on in our microservice landscape. The following is a screenshot from the Zipkin UI, which visualizes the trace tree that was created as a result of processing the creation of an aggregated product:
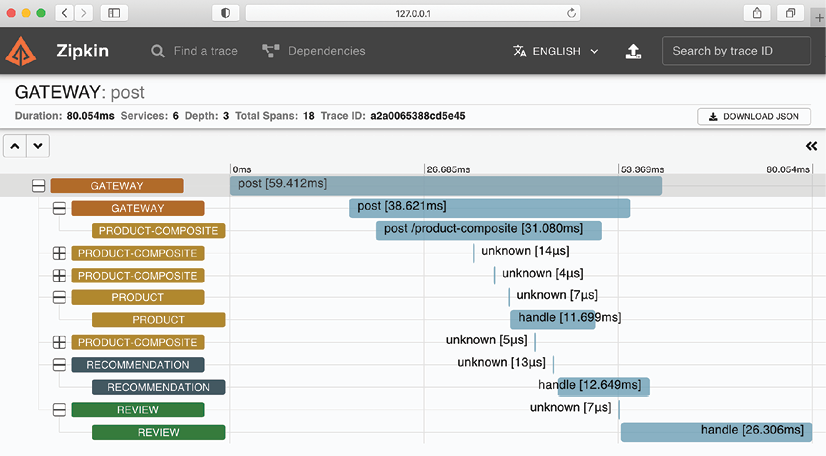
Figure 8.8: Trace tree in Zipkin
From the preceding screenshot, we can see that an HTTP POST request is sent to the product-composite service through the gateway (our edge server) and it responds by publishing create events to the topics for products, recommendations, and reviews. These events are consumed by the three core microservices in parallel and asynchronously, meaning that the product-composite service does not wait for the core microservices to complete their work. The data in the create events are stored in each microservice's database. A number of very short-lived spans named unknown are also shown in the preceding screenshot. They represent the interaction with the message broker, either publishing or consuming an event.
With Spring Cloud Sleuth and Zipkin for distributed tracing being introduced, we have seen an example of distributed tracing of the processing of an external synchronous HTTP request that includes asynchronous passing of events between the involved microservices.
Summary
In this chapter, we have seen how Spring Cloud has evolved from being rather Netflix OSS-centric to having a much larger scope as of today. We also introduced how components from the latest release of Spring Cloud Greenwich can be used to implement some of the design patterns we described in Chapter 1, Introduction to Microservices, in the Design patterns for microservices section. These design patterns are required to make a landscape of cooperating microservices production ready.
Head over to the next chapter to see how we can implement service discovery using Netflix Eureka and Spring Cloud LoadBalancer!
Questions
- What is the purpose of Netflix Eureka?
- What are the main features of Spring Cloud Gateway?
- What backends are supported by Spring Cloud Config?
- What are the capabilities that Resilience4j provides?
- What are the concepts of trace tree and span used for in distributed tracing, and what is the paper called that defined them?




