






















































Chapter 9. Advanced Reactivity
Now our blog is basically complete, as we can create and edit entries. In this chapter, we will make use of Meteor's reactive templates to make our interface timestamps update itself. We will build a reactive object that will rerun the template helper, which displays the time when the blog entries were created. This way, they will always display the correct relative time.
In this chapter, we will cover the following topics:
- Reactive programming
- Rerunning functions manually
- Building a reactive object using the
Trackerpackage - Stopping reactive functions
Note
If you've jumped right into the chapter and want to follow the examples, download the previous chapter's code examples from either the book's web page at https://www.packtpub.com/books/content/support/17713 or from the GitHub repository at https://github.com/frozeman/book-building-single-page-web-apps-with-meteor/tree/chapter8.
These code examples will also contain all the style files, so we don't have to worry about adding CSS code along the way.
Reactive programming
As we already saw throughout the book, Meteor uses something called reactivity.
One problem that a developer has to solve when building a software application is the consistency of the data represented in the interface. Most modern applications use something called Model-View-Controller (MVC), where the controller of a view makes sure that it always represents the current state of the model. The model is mostly a server API or a JSON object in the browser memory.
The most common ways of keeping consistent interfaces are as follows (courtesy: http://manual.meteor.com):
- Poll and diff: Periodically (for example, every second), fetch the current value of the thing, see whether it's changed, and if so, perform the update.
- Events: The thing that can change emits an event when it changes. Another part of the program (often called a controller) arranges to listen for this event, gets the current value, and performs the update when the event fires.
- Bindings: Values are represented by objects that implement some interface, such as
BindableValue. Then, a "bind" method is used to tie twoBindableValuestogether so that when one value changes, the other is updated automatically. Sometimes, as a part of setting up the binding, a transformation function can be specified. For example,Foocan be bound toBarwith thetoUpperCasetransformation function.
These patterns are good, but they still need a lot of code to maintain the consistency of the data represented.
Another pattern, although not yet as commonly used, is reactive programming. This pattern is a declarative way of binding data. It means when we use a reactive data source such as a Session variable or Mongo.Collection, we can be sure that reactive functions or template helpers that use these will rerun as soon as its value changes, always keeping the interface or calculations based on these values updated.
The Meteor manual gives us an example use case where reactive programming comes in handy:
Reactive programming is perfect for building user interfaces, because instead of attempting to model all interactions in a single piece of cohesive code, the programmer can express what should happen upon specific changes. The paradigm of responding to a change is simpler to understand than modeling which changes affect the state of the program explicitly.
For example, suppose that we are writing an HTML5 app with a table of items, and the user can click on an item to select it or ctrl-click to select multiple items. We might have an <h1> tag and want the contents of the tag to be equal to the name of the currently selected item, capitalized, or else "Multiple selection" if multiple items are selected. And we might have a set of <tr> tags and want the CSS class on each <tr> tag to be "selected" if the items corresponding to that row is in the set of selected items, or the empty string otherwise.
To make this example happen in the aforementioned patterns, we can quickly see how complex it gets compared to reactive programming (courtesy: http://manual.meteor.com):
- If we use poll and diff, the UI will be unacceptably laggy. After the user clicks, the screen won't actually update until the next polling cycle. Also, we have to store the old selection set and diff it against the new selection set, which is a bit of a hassle.
- If we use events, we have to write some fairly tangled controller code to manually map changes to the selection or to the name of the selected item, onto updates to the UI. For example, when the selection changes, we have to remember to update both the
<h1>tag and (typically) two affected<tr>tags. What's more, when the selection changes, we have to automatically register an event handler on the newly selected item so that we can remember to update<h1>. It is difficult to structure clean code and maintain it, especially as the UI is extended and redesigned. - If we use bindings, we will have to use a complex domain-specific language (DSL) to express the complex relationships between the variables. The DSL will have to include indirection (bind the contents of
<h1>not to the name of any fixed item, but to the item indicated by the current selection), transformation (capitalize the name), and conditionals (if more than one item is selected, show a placeholder string).
With Meteor's reactive template engine, Blaze, we can simply use the {{#each}} block helper to iterate over a list of elements and add some conditions for each element based on user interaction or on an item's property to add a selected class.
If the user now changes the data or the data coming in from the server changes, the interface will update itself to represent the data accordingly, saving us a lot of time and avoiding unnecessary complex code.
The invalidating cycle
One key part of understanding the reactive dependencies is the invalidate cycle.
When we use a reactive data source inside a reactive function, such as Tracker.autorun(function(){…}), the reactive data source itself sees that it is inside a reactive function and adds the current function as a dependency to its dependency store.
Then, when the value of the data source changes, it invalidates (reruns) all its dependent functions and removes them from its dependency store.
In the rerun of the reactive function, it adds the reactive function back to its dependency store so that they will rerun on its next invalidation (value change) again.
This is the key to understand the reactive concept, as we will see in the following example.
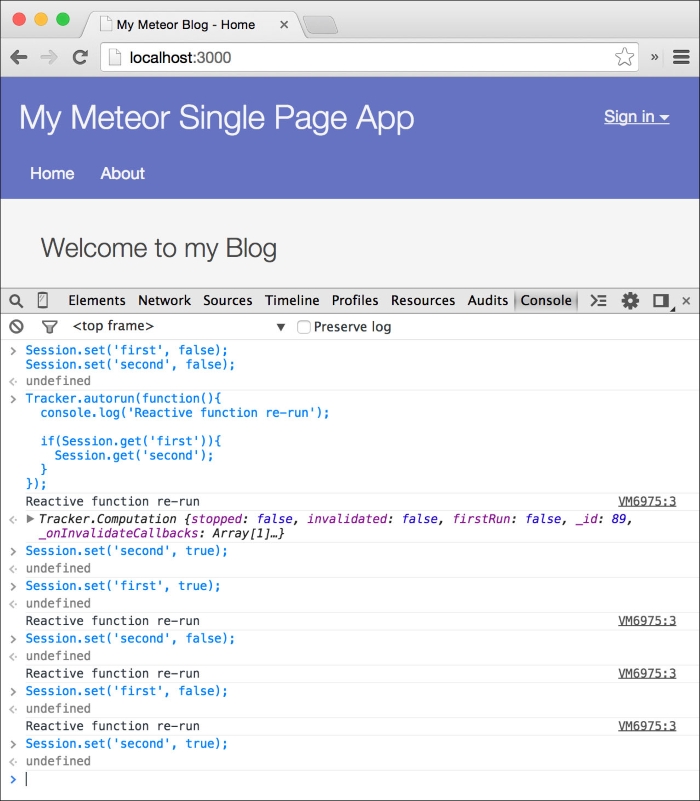
Imagine that we have two Session variables set to false:
Session.set('first', false);
Session.set('second', false);Moreover, We have the Tracker.autorun() function, which uses both these variables:
Tracker.autorun(function(){
console.log('Reactive function re-run');
if(Session.get('first')){
Session.get('second');
}
});We can now call Session.set('second', true), but the reactive function will not rerun, because it was never called in the first run, as the first session variable was set to false.
If we now call Session.set(first, true), the function will rerun.
Additionally, if we now set Session.set('second', false), it will rerun as well, as in the second rerun, Session.get('second') can add this reactive function as a dependency.
Because the reactive data sources source will always remove all dependencies from its store on every invalidation and add them back in the rerun of the reactive function, we can set Session.set(first, false) and try to switch it to Session.set('second', true). The function will not rerun again, as Session.get('second') was never called in this run!
Once we understand this, we can make more fine-grained reactivity, keeping reactive updates to a minimum. The console output of the explanation looks similar to the following screenshot:
Building a simple reactive object
As we saw, a
reactive object is an object that when used inside a reactive function, will rerun the function when its value changes. The Meteor's Session object is one example of a reactive object.
In this chapter, we will build a simple reactive object that will rerun our {{formatTime}} template helper at time intervals so that all the relative times are updated correctly.
Meteor's reactivity is made possible through the Tracker package. This package is the core of all reactivity and allows us to track dependencies and rerun these whenever we want.
Perform the following steps to build a simple reactive object:
- To get started, let's add the following code to the
my-meteor-blog/main.jsfile:if(Meteor.isClient) { ReactiveTimer = new Tracker.Dependency; }This will create a variable named
ReactiveTimeron the client with a new instance ofTracker.Dependency. - Below the
ReactiveTimervariable, but still inside theif(Meteor.isClient)condition, we will add the following code to rerun all dependencies of ourReactiveTimerobject every 10 seconds:Meteor.setInterval(function(){ // re-run dependencies every 10s ReactiveTimer.changed(); }, 10000);The
Meteor.setIntervalwill run the function every 10 seconds.Note
Meteor comes with its own implementation of
setIntervalandsetTimeout. Even though they work exactly as their native JavaScript equivalents, Meteor needs these to reference the right timeout/interval for a specific user on the server side.
Meteor comes with its own implementation of setInterval and setTimeout. Even though they work exactly as their native JavaScript equivalents, Meteor needs these to reference the right timeout/interval for a specific user on the server side.
Inside the interval, we call ReactiveTimer.changed(). This will invalidate every dependent function, causing it to rerun.
Rerunning functions
So far, we have no dependency created, so let's do that. Add the following code below Meteor.setInterval:
Tracker.autorun(function(){
ReactiveTimer.depend();
console.log('Function re-run');
});If we now get back to our browser console, we should see Function re-run every 10 seconds, as our reactive object reruns the function.
We can even call ReactiveTimer.changed() in our browser console and the function will rerun as well.
These are good examples, but don't make our timestamps update automatically.
To do this, we need to open up my-meteor-blog/client/template-helpers.js and add the following line at the top of our formatTime helper function:
ReactiveTimer.depend();
This will make every {{formatTime}} helper in our app rerun every 10 seconds, updating the relative time while it passes. To see this, go to your browser and create a new blog entry. If you save the blog entry now and watch the time created text, you will see that it changes after a while:
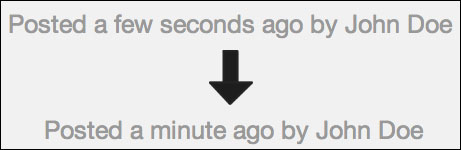
Rerunning functions
So far, we have no dependency created, so let's do that. Add the following code below Meteor.setInterval:
Tracker.autorun(function(){
ReactiveTimer.depend();
console.log('Function re-run');
});If we now get back to our browser console, we should see Function re-run every 10 seconds, as our reactive object reruns the function.
We can even call ReactiveTimer.changed() in our browser console and the function will rerun as well.
These are good examples, but don't make our timestamps update automatically.
To do this, we need to open up my-meteor-blog/client/template-helpers.js and add the following line at the top of our formatTime helper function:
ReactiveTimer.depend();
This will make every {{formatTime}} helper in our app rerun every 10 seconds, updating the relative time while it passes. To see this, go to your browser and create a new blog entry. If you save the blog entry now and watch the time created text, you will see that it changes after a while:
Creating an advanced timer object
The previous example was a simple demonstration of a custom reactive object. To make it more useful, it is better to create a separate object that hides the Tracker.Dependency functions and adds additional functionality.
Meteor's reactivity and dependency tracking allows us to create dependencies even when the depend() function is called from inside another function. This dependency chain allows more complex reactive objects.
In the next example, we will take our timer object and add a start and stop function to it. Additionally, we will also make it possible to choose a time interval at which the timer will rerun:
- First, let's remove the previous code examples from the
main.jsandtemplate-helpers.jsfiles, which we added before, and create a new file namedReactiveTimer.jsinsidemy-meteor-blog/clientwith the following content:ReactiveTimer = (function () { // Constructor function ReactiveTimer() { this._dependency = new Tracker.Dependency; this._intervalId = null; }; return ReactiveTimer; })();This creates a classic prototype class in JavaScript, which we can instantiate using
new ReactiveTimer(). In its constructor function, we instantiate anew Tracker.Dependencyand attach it to the function. - Now, we will create a
start()function, which will start a self-chosen interval:ReactiveTimer = (function () { // Constructor function ReactiveTimer() { this._dependency = new Tracker.Dependency; this._intervalId = null; }; ReactiveTimer.prototype.start = function(interval){ var _this = this; this._intervalId = Meteor.setInterval(function(){ // rerun every "interval" _this._dependency.changed(); }, 1000 * interval); }; return ReactiveTimer; })();This is the same code as we used before with the difference that we store the interval ID in
this._intervalIdso that we can stop it later in ourstop()function. The interval passed to thestart()function must be in seconds; - Next, we add the
stop()function to the class, which will simply clear the interval:ReactiveTimer.prototype.stop = function(){ Meteor.clearInterval(this._intervalId); }; - Now we only need a function that creates the dependencies:
ReactiveTimer.prototype.tick = function(){ this._dependency.depend(); };Our reactive timer is ready!
- Now, to instantiate the
timerand start it with whatever interval we like, add the following code after theReactiveTimerclass at the end of the file:timer = new ReactiveTimer(); timer.start(10);
- At last, we need to go back to our
{{formatTime}}helper in thetemplate-helper.jsfile, andaddthetime.tick()function, and every relative time in the interface will update as time goes by. - To see the reactive timer in action, run the following code snippet in our browser's console:
Tracker.autorun(function(){ timer.tick(); console.log('Timer ticked!'); }); - We should now see Timer ticked! logged every 10 seconds. If we now run
time.stop(), the timer will stop running its dependent functions. If we calltime.start(2)again, we will see Timer ticked! now appearing every two seconds, as we set the interval to2: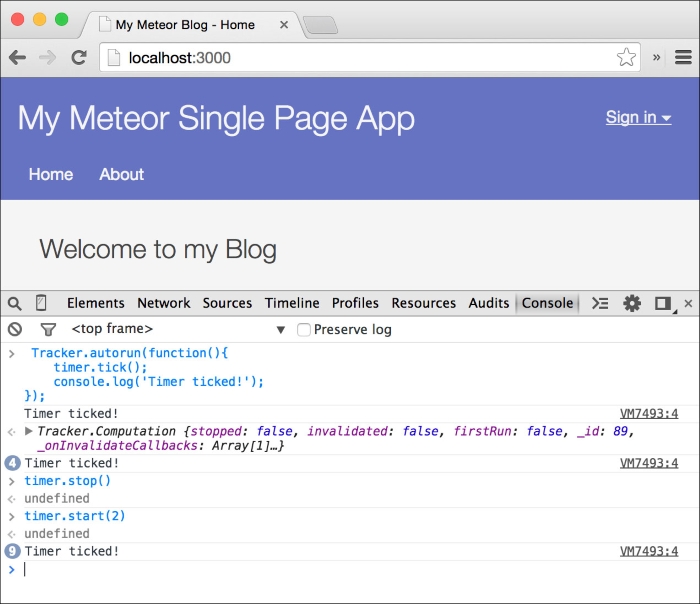
As we can see, our
timer object is now rather flexible, and we can create any number of time intervals to be used throughout the app.
Reactive computations
Meteor's reactivity and the Tracker package is a very powerful feature, as it allows event-like behavior to be attached to every function and every template helper. This reactivity is what keeps our interface consistent.
Although we only touched the Tracker package until now, it has a few more properties that we should take a look at.
We already learned how to instantiate a reactive object. We can call new Tracker.Dependency, which can create and rerun dependencies using depend() and changed().
Stopping reactive functions
When we are inside a reactive function, we also have access to the current computational object, which we can use to stop further reactive behavior.
To see this in action, we can use our already running timer and create the following reactive function using Tracker.autorun() in our browser's console:
var count = 0;
var someInnerFunction = function(count){
console.log('Running for the '+ count +' time');
if(count === 10)
Tracker.currentComputation.stop();
};
Tracker.autorun(function(c){
timer.tick();
someInnerFunction(count);
count++;
});
timer.stop();
timer.start(2);Here, we create someInnerFunction() to show how we can access the current computation as well from nested functions. In this inner function, we get the computation using Tracker.currentComputation, which gives us the current Tracker.Computation object.
We use the count variable, we created before the Tracker.autorun() function, to count up. When we reach 10, we call Tracker.currentComputation.stop(), which will stop the dependency of the inner and the Tracker.autorun() functions, making them nonreactive.
To see the results quicker, we stop and start the timer object with an interval of two seconds at the end of the example.
If we copy and paste the previous code snippet into our browser's console and run it, we should see Running for the xx time appearing 10 times:
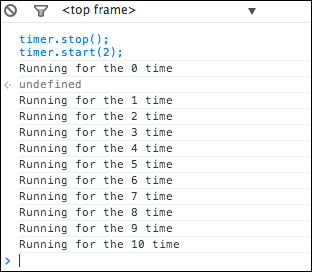
The current computational object is useful to give us control over reactive dependencies from inside the dependent functions.
Preventing run at start
The Tracker .Computation object also comes with the firstRun property, which we have used in an earlier chapter.
Reactive functions, for example, when created using Tracker.autorun() also run when they are parsed by JavaScript for the first time. If we want to prevent this, we can simply stop the function before any code is executed when checking whether firstRun is true:
Tracker.autorun(function(c){
timer.tick();
if(c.firstRun)
return;
// Do some other stuff
});Note
We don't need to get the current computation here using Tracker.currentComputation, as Tracker.autorun() gets it already as its first argument.
Also, when we stop a Tracker.autorun() function, as described in the following code, it will never create the dependency for the session variable, as Session.get() was never called in the first run:
Tracker.autorun(function(c){
if(c.firstRun)
return;
Session.get('myValue');
}):To make sure that we make the function depending on the myValue session variable, we need to put it before the return statement.
Advanced reactive objects
The Tracker package has a few more advanced properties and functions that allow you to control when dependencies are invalidated (Tracker.flush() and Tracker.Computation.invalidate()) and allow you to register additional callbacks on it (Tracker.onInvalidate()).
These properties allow you to build complex reactive objects, which are out of the scope of this book. If you want to get a deeper understanding of the Tracker package, I recommend that you take a look at the Meteor manual at http://manual.meteor.com/#tracker.
Stopping reactive functions
When we are inside a reactive function, we also have access to the current computational object, which we can use to stop further reactive behavior.
To see this in action, we can use our already running timer and create the following reactive function using Tracker.autorun() in our browser's console:
var count = 0;
var someInnerFunction = function(count){
console.log('Running for the '+ count +' time');
if(count === 10)
Tracker.currentComputation.stop();
};
Tracker.autorun(function(c){
timer.tick();
someInnerFunction(count);
count++;
});
timer.stop();
timer.start(2);Here, we create someInnerFunction() to show how we can access the current computation as well from nested functions. In this inner function, we get the computation using Tracker.currentComputation, which gives us the current Tracker.Computation object.
We use the count variable, we created before the Tracker.autorun() function, to count up. When we reach 10, we call Tracker.currentComputation.stop(), which will stop the dependency of the inner and the Tracker.autorun() functions, making them nonreactive.
To see the results quicker, we stop and start the timer object with an interval of two seconds at the end of the example.
If we copy and paste the previous code snippet into our browser's console and run it, we should see Running for the xx time appearing 10 times:
The current computational object is useful to give us control over reactive dependencies from inside the dependent functions.
Preventing run at start
The Tracker .Computation object also comes with the firstRun property, which we have used in an earlier chapter.
Reactive functions, for example, when created using Tracker.autorun() also run when they are parsed by JavaScript for the first time. If we want to prevent this, we can simply stop the function before any code is executed when checking whether firstRun is true:
Tracker.autorun(function(c){
timer.tick();
if(c.firstRun)
return;
// Do some other stuff
});Note
We don't need to get the current computation here using Tracker.currentComputation, as Tracker.autorun() gets it already as its first argument.
Also, when we stop a Tracker.autorun() function, as described in the following code, it will never create the dependency for the session variable, as Session.get() was never called in the first run:
Tracker.autorun(function(c){
if(c.firstRun)
return;
Session.get('myValue');
}):To make sure that we make the function depending on the myValue session variable, we need to put it before the return statement.
Advanced reactive objects
The Tracker package has a few more advanced properties and functions that allow you to control when dependencies are invalidated (Tracker.flush() and Tracker.Computation.invalidate()) and allow you to register additional callbacks on it (Tracker.onInvalidate()).
These properties allow you to build complex reactive objects, which are out of the scope of this book. If you want to get a deeper understanding of the Tracker package, I recommend that you take a look at the Meteor manual at http://manual.meteor.com/#tracker.
Preventing run at start
The Tracker .Computation object also comes with the firstRun property, which we have used in an earlier chapter.
Reactive functions, for example, when created using Tracker.autorun() also run when they are parsed by JavaScript for the first time. If we want to prevent this, we can simply stop the function before any code is executed when checking whether firstRun is true:
Tracker.autorun(function(c){
timer.tick();
if(c.firstRun)
return;
// Do some other stuff
});Note
We don't need to get the current computation here using Tracker.currentComputation, as Tracker.autorun() gets it already as its first argument.
Also, when we stop a Tracker.autorun() function, as described in the following code, it will never create the dependency for the session variable, as Session.get() was never called in the first run:
Tracker.autorun(function(c){
if(c.firstRun)
return;
Session.get('myValue');
}):To make sure that we make the function depending on the myValue session variable, we need to put it before the return statement.
Advanced reactive objects
The Tracker package has a few more advanced properties and functions that allow you to control when dependencies are invalidated (Tracker.flush() and Tracker.Computation.invalidate()) and allow you to register additional callbacks on it (Tracker.onInvalidate()).
These properties allow you to build complex reactive objects, which are out of the scope of this book. If you want to get a deeper understanding of the Tracker package, I recommend that you take a look at the Meteor manual at http://manual.meteor.com/#tracker.
Advanced reactive objects
The Tracker package has a few more advanced properties and functions that allow you to control when dependencies are invalidated (Tracker.flush() and Tracker.Computation.invalidate()) and allow you to register additional callbacks on it (Tracker.onInvalidate()).
These properties allow you to build complex reactive objects, which are out of the scope of this book. If you want to get a deeper understanding of the Tracker package, I recommend that you take a look at the Meteor manual at http://manual.meteor.com/#tracker.
Summary
In this chapter, we learned how to build our own custom reactive object. We learned about Tracker.Dependency.depend() and Tracker.Dependency.changed() and saw how reactive dependencies have their own computational objects, which can be used to stop its reactive behavior and prevent running at start.
To dig deeper, take a look at the documentation for the Tracker package and see detailed property descriptions for the Tracker.Computation object at the following resources:
You can find this chapter's code examples at https://www.packtpub.com/books/content/support/17713 or on GitHub at https://github.com/frozeman/book-building-single-page-web-apps-with-meteor/tree/chapter9.
Now that we have finalized our blog, we will take a look at how to deploy our app on servers in the next chapter.



