






















































Our First Analysis - The Boston Housing Dataset
So far, this chapter has focused on the features and basic usage of Jupyter. Now, we'll put this into practice and do some data exploration and analysis.
The dataset we'll look at in this section is the so-called Boston housing dataset. It contains US census data concerning houses in various areas around the city of Boston. Each sample corresponds to a unique area and has about a dozen measures. We should think of samples as rows and measures as columns. The data was first published in 1978 and is quite small, containing only about 500 samples.
Now that we know something about the context of the dataset, let's decide on a rough plan for the exploration and analysis. If applicable, this plan would accommodate the relevant question(s) under study. In this case, the goal is not to answer a question but to instead show Jupyter in action and illustrate some basic data analysis methods.
Our general approach to this analysis will be to do the following:
- Load the data into Jupyter using a Pandas DataFrame
- Quantitatively understand the features
- Look for patterns and generate questions
- Answer the questions to the problems
Loading the Data into Jupyter Using a Pandas DataFrame
Oftentimes, data is stored in tables, which means it can be saved as a comma-separated variable (CSV) file. This format, and many others, can be read into Python as a DataFrame object, using the Pandas library. Other common formats include tab-separated variable (TSV), SQL tables, and JSON data structures. Indeed, Pandas has support for all of these. In this example, however, we are not going to load the data this way because the dataset is available directly through scikit-learn.
Note
An important part after loading data for analysis is ensuring that it's clean. For example, we would generally need to deal with missing data and ensure that all columns have the correct datatypes. The dataset we use in this section has already been cleaned, so we will not need to worry about this. However, we'll see messier data in the second chapter and explore techniques for dealing with it.
Exercise 4: Loading the Boston Housing Dataset
- Scroll to
Subtopic AofTopic B: Our first Analysis: the Boston Housing Datasetin chapter 1 of the Jupyter Notebook.The Boston housing dataset can be accessed from the
sklearn.datasetsmodule using theload_bostonmethod. - Run the first two cells in this section to load the Boston dataset and see the
datastructurestype:
Figure 1.23: Loading the Boston dataset
The output of the second cell tells us that it's a scikit-learn
Bunchobject. Let's get some more information about that to understand what we are dealing with. - Run the next cell to import the base object from scikit-learn
utilsand print the docstring in our Notebook:
Figure 1.24: Importing base objects and printing the docstring
- Print the field names (that is, the keys to the dictionary) by running the next cell. We find these fields to be self-explanatory:
['DESCR', 'target', 'data', 'feature_names']. - Run the next cell to print the dataset description contained in
boston['DESCR'].Note that in this call, we explicitly want to print the field value so that the Notebook renders the content in a more readable format than the string representation (that is, if we just type
boston['DESCR']without wrapping it in aprintstatement). We then see the dataset information as we've previously summarized:Boston House Prices dataset =========================== Notes ------ Data Set Characteristics: :Number of Instances: 506 :Number of Attributes: 13 numeric/categorical predictive :Median Value (attribute 14) is usually the target :Attribute Information (in order): - CRIM per capita crime rate by town … … - MEDV Median value of owner-occupied homes in $1000's :Missing Attribute Values: None
Note
Briefly read through the feature descriptions and/or describe them yourself. For the purposes of this tutorial, the most important fields to understand are RM, AGE, LSTAT, and MEDV. Note down the important variables that we will use in the dataset, such as RM, AGE, LSTAT, and MEDV.
Of particular importance here are the feature descriptions (under
AttributeInformation). We will use this as reference during our analysis.Note
For the complete code, refer to the following: https://bit.ly/2EL11cW
Now, we are going to create a Pandas DataFrame that contains the data. This is beneficial for a few reasons: all of our data will be contained in one object, there are useful and computationally efficient DataFrame methods we can use, and other libraries such as Seaborn have tools that integrate nicely with DataFrames.
In this case, we will create our DataFrame with the standard constructor method.
- Run the cell where Pandas is imported and the docstring is retrieved for
pd.DataFrame:
Figure 1.25: Retrieving the docstring for pd.DataFrame
The docstring reveals the DataFrame input parameters. We want to feed in
boston['data']for the data and useboston['feature_names']for the headers. - Run the next few cells to print the data, its shape, and the feature names:

Figure 1.26: Printing data, shape, and feature names
Looking at the output, we see that our data is in a 2D NumPy array. Running the command
boston['data'].shapereturns the length (number of samples) and the number of features as the first and second outputs, respectively. - Load the data into a Pandas DataFrame
dfby running the following:df = pd.DataFrame(data=boston['data'], columns=boston['feature_names'])
In machine learning, the variable that is being modeled is called the target variable; it's what you are trying to predict given the features. For this dataset, the suggested target is MEDV, the median house value in 1,000s of dollars.
- Run the next cell to see the shape of the target:

Figure 1.27: Code for viewing the shape of the target
We see that it has the same length as the features, which is what we expect. It can therefore be added as a new column to the DataFrame.
- Add the target variable to df by running the cell with the following:
df['MEDV'] = boston['target']
- Move the target variable to the front of
dfby running the cell with the following code:y = df['MEDV'].copy() del df['MEDV'] df = pd.concat((y, df), axis=1)
This is done to distinguish the target from our features by storing it to the front of our DataFrame.
Here, we introduce a dummy variable
yto hold a copy of the target column before removing it from the DataFrame. We then use the Pandas concatenation function to combine it with the remaining DataFrame along the 1st axis (as opposed to the 0th axis, which combines rows).Note
You will often see dot notation used to reference DataFrame columns. For example, previously we could have done
y = df.MEDV.copy(). This does not work for deleting columns, however;del df.MEDVwould raise an error. - Implement
df.head()ordf.tail()to glimpse the data andlen(df)to verify that number of samples is what we expect. Run the next few cells to see the head, tail, and length ofdf:
Figure 1.28: Printing the head of the data frame df

Figure 1.29: Printing the tail of data frame df
Each row is labeled with an index value, as seen in bold on the left side of the table. By default, these are a set of integers starting at 0 and incrementing by one for each row.
- Printing
df.dtypeswill show the datatype contained within each column. Run the next cell to see the datatypes of each column. For this dataset, we see that every field is a float and therefore most likely a continuous variable, including the target. This means that predicting the target variable is a regression problem. - Run
df.isnull()to clean the dataset as Pandas automatically sets missing data asNaNvalues. To get the number ofNaNvalues per column, we can dodf.isnull().sum():
Figure 1.30: Cleaning the dataset by identifying NaN values
df.isnull()returns a Boolean frame of the same length asdf.For this dataset, we see there are no
NaNvalues, which means we have no immediate work to do in cleaning the data and can move on. - Remove some columns by running the cell that contains the following code:
for col in ['ZN', 'NOX', 'RAD', 'PTRATIO', 'B']: del df[col]
This is done to simplify the analysis. We will focus on the remaining columns in more detail.
Data Exploration
Since this is an entirely new dataset that we've never seen before, the first goal here is to understand the data. We've already seen the textual description of the data, which is important for qualitative understanding. We'll now compute a quantitative description.
Exercise 5: Analyzing the Boston Housing Dataset
- Navigate to
Subtopic B: Data explorationin the Jupyter Notebook and run the cell containingdf.describe():
Figure 1.31: Computation and output of statistical properties
This computes various properties including the mean, standard deviation, minimum, and maximum for each column. This table gives a high-level idea of how everything is distributed. Note that we have taken the transform of the result by adding a
.Tto the output; this swaps the rows and columns.Going forward with the analysis, we will specify a set of columns to focus on.
- Run the cell where these "focus columns" are defined:
cols = ['RM', 'AGE', 'TAX', 'LSTAT', 'MEDV']
- Display the aforementioned subset of columns of the DataFrame by running
df[cols].head():
Figure 1.32: Displaying focus columns
As a reminder, let's recall what each of these columns is. From the dataset documentation, we have the following:
- RM average number of rooms per dwelling - AGE proportion of owner-occupied units built prior to 1940 - TAX full-value property-tax rate per $10,000 - LSTAT % lower status of the population - MEDV Median value of owner-occupied homes in $1000's
To look for patterns in this data, we can start by calculating the pairwise correlations using
pd.DataFrame.corr. - Calculate the pairwise correlations for our selected columns by running the cell containing the following code:
df[cols].corr()

Figure 1.33: Pairwise calculation of correlation
This resulting table shows the correlation score between each set of values. Large positive scores indicate a strong positive (that is, in the same direction) correlation. As expected, we see maximum values of 1 on the diagonal.
By default, Pandas calculates the standard correlation coefficient for each pair, which is also called the Pearson coefficient. This is defined as the covariance between two variables, divided by the product of their standard deviations:

The covariance, in turn, is defned as follows:

Here, n is the number of samples, xi and yi are the individual samples being summed over, and X and Y are the means of each set.
Instead of straining our eyes to look at the preceding table, it's nicer to visualize it with a heatmap. This can be done easily with Seaborn.
- Run the next cell to initialize the plotting environment, as discussed earlier in the chapter. Then, to create the heatmap, run the cell containing the following code:
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline ax = sns.heatmap(df[cols].corr(), cmap=sns.cubehelix_palette(20, light=0.95, dark=0.15)) ax.xaxis.tick_top() # move labels to the top plt.savefig('../figures/lesson-1-boston-housing-corr.png', bbox_inches='tight', dpi=300)
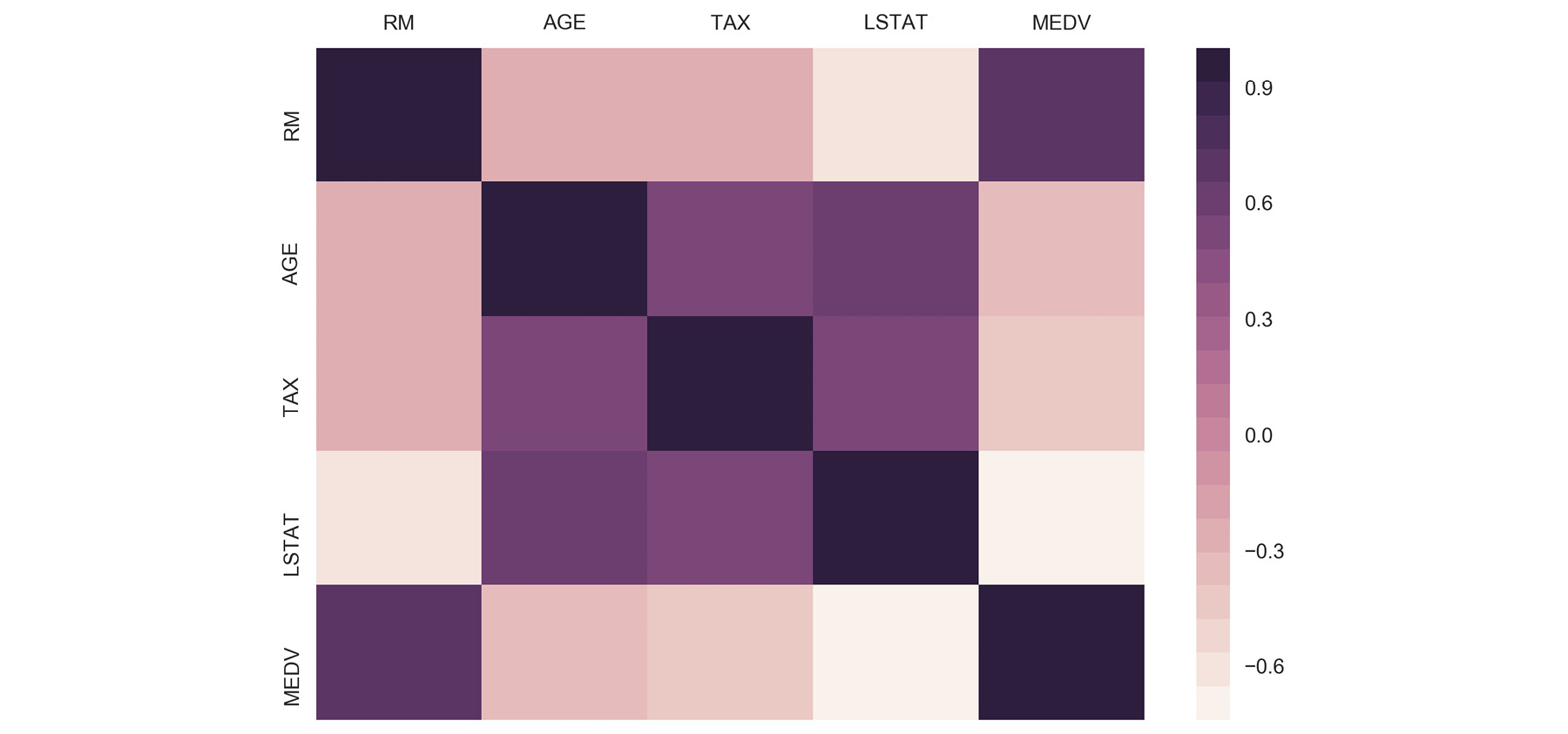
Figure 1.34: Plot of the heat map for all variables
We call sns.heatmap and pass the pairwise correlation matrix as input. We use a custom color palette here to override the Seaborn default. The function returns a matplotlib.axes object which is referenced by the variable ax.
The final figure is then saved as a high resolution PNG to the figures folder.
For the final step in our dataset exploration exercise, we'll visualize our data using Seaborn's pairplot function.
Visualize the DataFrame using Seaborn's pairplot function. Run the cell containing the following code:
sns.pairplot(df[cols],
plot_kws={'alpha': 0.6},
diag_kws={'bins': 30})
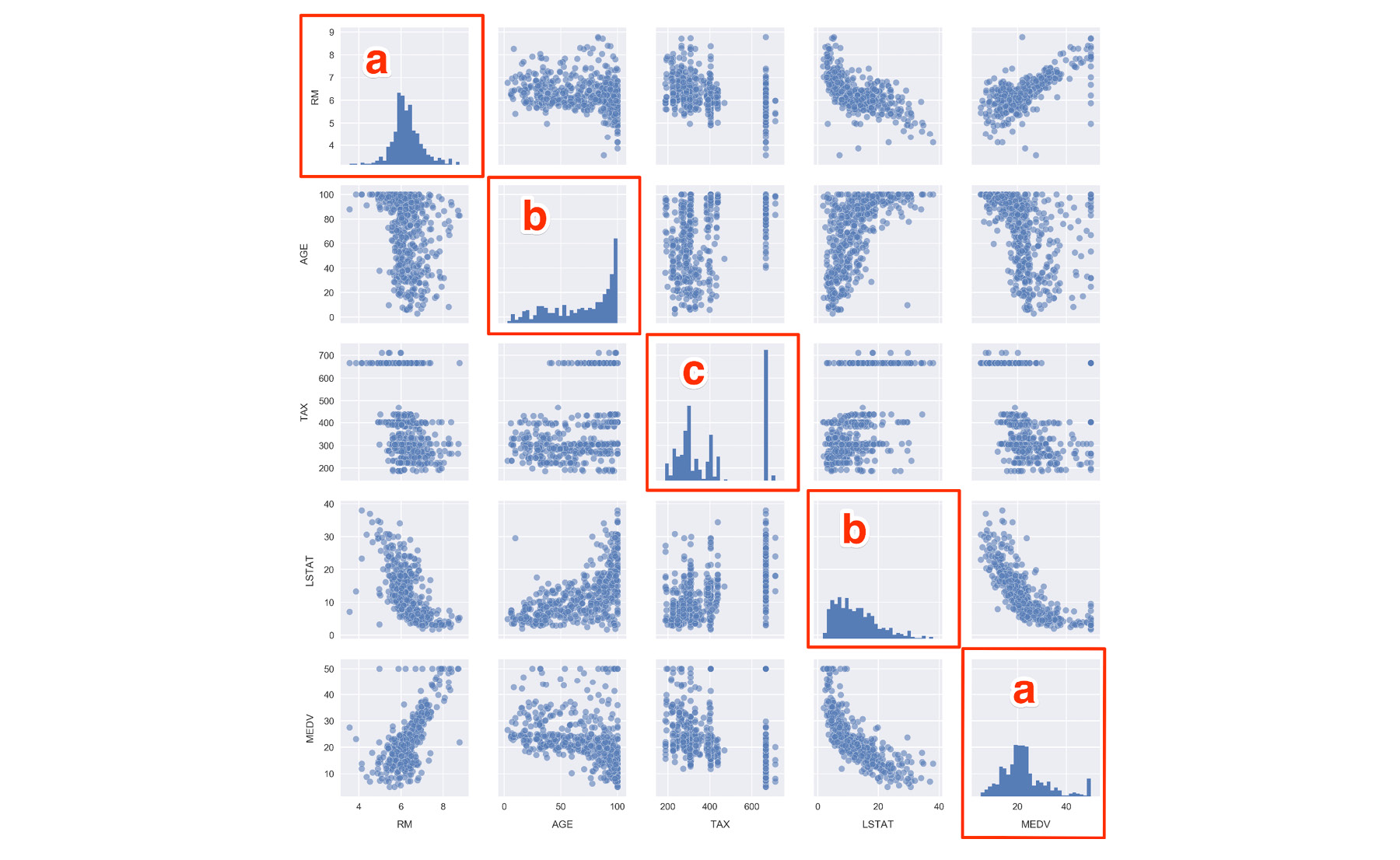
Figure 1.35: Data visualization using Seaborn
Note
Note that unsupervised learning techniques are outside the scope of this book.
Looking at the histograms on the diagonal, we see the following:
a: RM and MEDV have the closest shape to normal distributions.
b: AGE is skewed to the left and LSTAT is skewed to the right (this mayseem counterintuitive but skew is defined in terms of where the mean is positioned in relation to the max).
c: For TAX, we find a large amount of the distribution is around 700. This is also evident from the scatter plots.
Taking a closer look at the MEDV histogram in the bottom right, we actually see something similar to TAX where there is a large upper-limit bin around $50,000. Recall when we did df.describe(), the min and max of MDEV was 5k and 50k, respectively. This suggests that median house values in the dataset were capped at 50k.
Introduction to Predictive Analytics with Jupyter Notebooks
Continuing our analysis of the Boston housing dataset, we can see that it presents us with a regression problem where we predict a continuous target variable given a set of features. In particular, we'll be predicting the median house value (MEDV).
We'll train models that take only one feature as input to make this prediction. This way, the models will be conceptually simple to understand and we can focus more on the technical details of the scikit-learn API. Then, in the next chapter, you'll be more comfortable dealing with the relatively complicated models.
Exercise 6: Applying Linear Models With Seaborn and Scikit-learn
- Scroll to
Subtopic C: Introduction to predictive analyticsin the Jupyter Notebook and look just above at the pairplot we created in the previous section. In particular, look at the scatter plots in the bottom-left corner:
Figure 1.36: Scatter plots for MEDV and LSTAT
Note how the number of rooms per house (RM) and the % of the population that is lower class (LSTAT) are highly correlated with the median house value (MDEV). Let's pose the following question: how well can we predict MDEV given these variables?
To help answer this, let's first visualize the relationships using Seaborn. We will draw the scatter plots along with the line of best fit linear models.
- Draw scatter plots along with the linear models by running the cell that contains the following:
fig, ax = plt.subplots(1, 2) sns.regplot('RM', 'MEDV', df, ax=ax[0], scatter_kws={'alpha': 0.4})) sns.regplot('LSTAT', 'MEDV', df, ax=ax[1], scatter_kws={'alpha': 0.4}))
Figure 1.37: Drawing scatter plots using linear models
The line of best fit is calculated by minimizing the ordinary least squares error function, something Seaborn does automatically when we call the
regplotfunction. Also note the shaded areas around the lines, which represent 95% confidence intervals.Note
These 95% confidence intervals are calculated by taking the standard deviation of data in bins perpendicular to the line of best fit, effectively determining the confidence intervals at each point along the line of best fit. In practice, this involves Seaborn bootstrapping the data, a process where new data is created through random sampling with replacement. The number of bootstrapped samples is automatically determined based on the size of the dataset, but can be manually set as well by passing the
n_bootargument. - Plot the residuals using Seaborn by running the cell containing the following:
fig, ax = plt.subplots(1, 2) ax[0] = sns.residplot('RM', 'MEDV', df, ax=ax[0], scatter_kws={'alpha': 0.4}) ax[0].set_ylabel('MDEV residuals $(y-\hat{y})$') ax[1] = sns.residplot('LSTAT', 'MEDV', df, ax=ax[1], scatter_kws={'alpha': 0.4}) ax[1].set_ylabel('')
Figure 1.38: Plotting residuals using Seaborn
Each point on these residual plots is the difference between that sample (
y) and the linear model prediction (ŷ). Residuals greater than zero are data points that would be underestimated by the model. Likewise, residuals less than zero are data points that would be overestimated by the model.Patterns in these plots can indicate suboptimal modeling. In each preceding case, we see diagonally arranged scatter points in the positive region. These are caused by the $50,000 cap on MEDV. The RM data is clustered nicely around 0, which indicates a good fit. On the other hand, LSTAT appears to be clustered lower than 0.
- Define a function using sci-kit learn that calculates the line of best fit and mean squared error, by running the cell that contains the following:
def get_mse(df, feature, target='MEDV'): # Get x, y to model y = df[target].values x = df[feature].values.reshape(-1,1) ... ... error = mean_squared_error(y, y_pred) print('mse = {:.2f}'.format(error)) print()Note
For complete code, refer to the following: https://bit.ly/2JgPZdU
In the
get_msefunction, we first assign the variablesyandxto the target MDEV and the dependent feature, respectively. These are cast as NumPy arrays by calling thevaluesattribute. The dependent features array is reshaped to the format expected by scikit-learn; this is only necessary when modeling a one-dimensional feature space. The model is then instantiated and fitted on the data. For linear regression, the fitting consists of computing the model parameters using the ordinary least squares method (minimizing the sum of squared errors for each sample). Finally, after determining the parameters, we predict the target variable and use the results to calculate the MSE. - Call the
get_msefunction for both RM and LSTAT, by running the cell containing the following:get_mse(df, 'RM') get_mse(df, 'LSTAT')
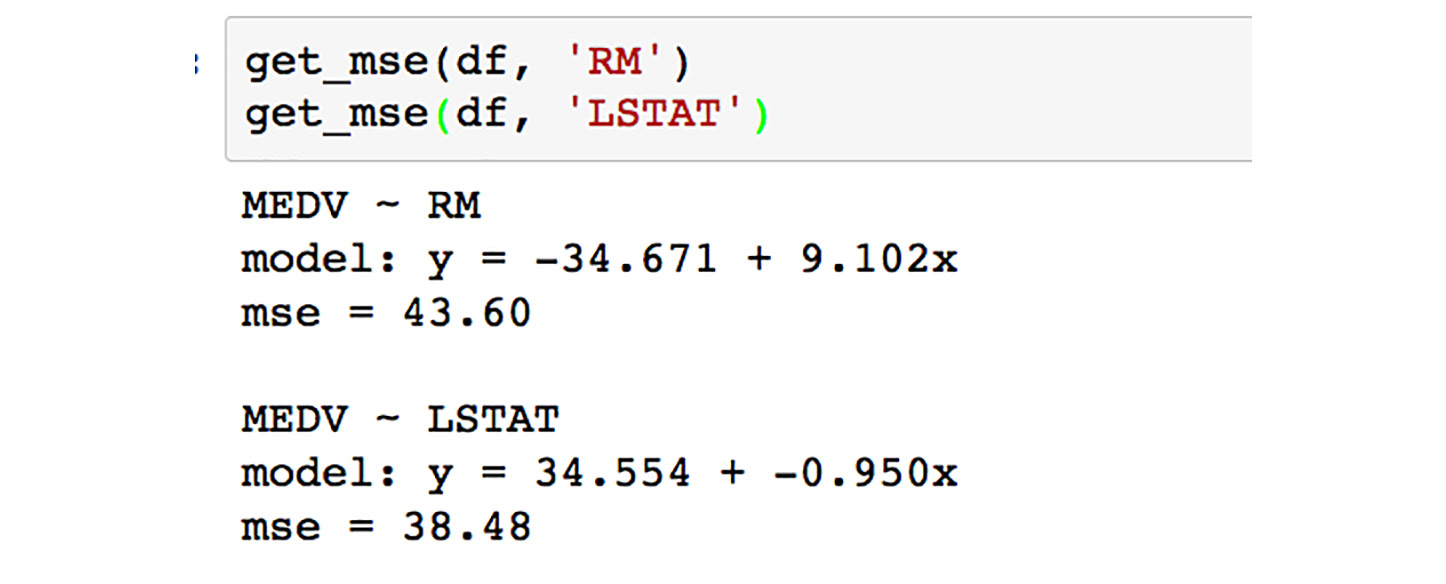
Figure 1.39: Calling the get_mse function for RM and LSTAT
Comparing the MSE, it turns out the error is slightly lower for LSTAT. Looking back to the scatter plots, however, it appears that we might have even better success using a polynomial model for LSTAT. In the next activity, we will test this by computing a third-order polynomial model with scikit-learn.
Forgetting about our Boston housing dataset for a minute, consider another real-world situation where you might employ polynomial regression. The following example is modeling weather data. In the following plot, we see temperatures (lines) and precipitations (bars) for Vancouver, BC, Canada:
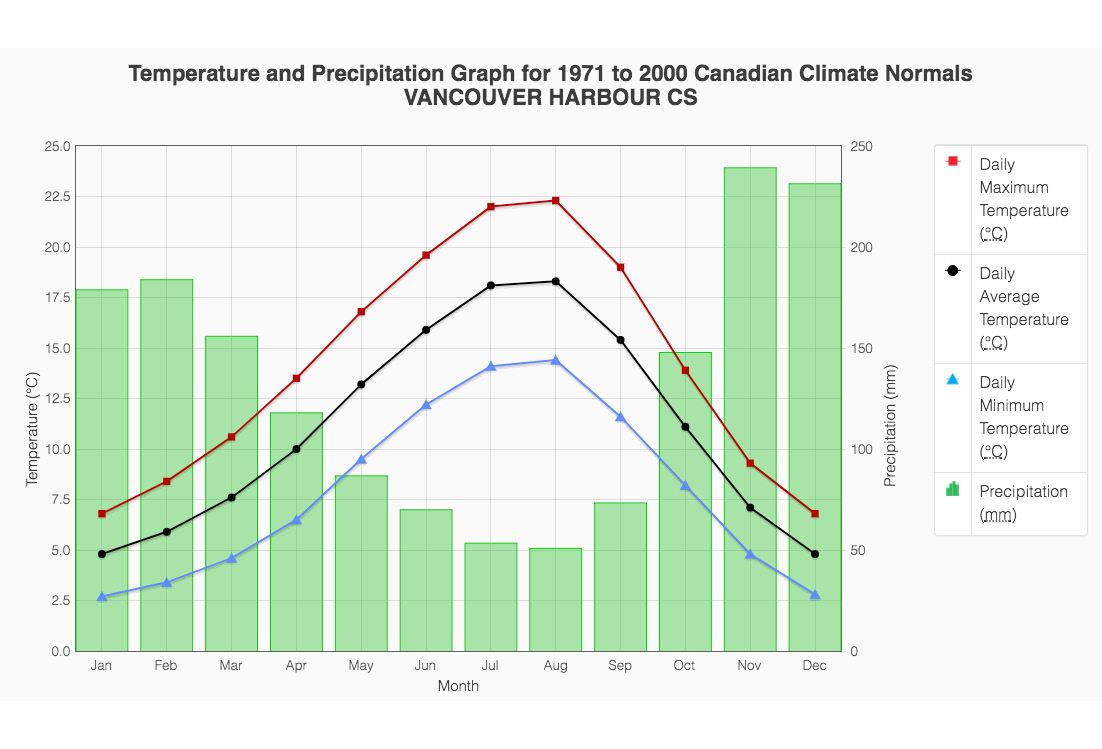
Figure 1.40: Visualizing weather data for Vancouver, Canada
Any of these fields are likely to be fit quite well by a fourth-order polynomial. This would be a very valuable model to have, for example, if you were interested in predicting the temperature or precipitation for a continuous range of dates.
Note
You can find the data source for this here: http://climate.weather.gc.ca/climate_normals/results_e.html?stnID=888.
Activity 1: Building a Third-Order Polynomial Model
Shifting our attention back to the Boston housing dataset, we would like to build a third-order polynomial model to compare against the linear one. Recall the actual problem we are trying to solve: predicting the median house value, given the lower class population percentage. This model could benefit a prospective Boston house purchaser who cares about how much of their community would be lower class.
Our aim is to use scikit-learn to fit a polynomial regression model to predict the median house value (MEDV), given the LSTAT values. We are hoping to build a model that has a lower mean-squared error (MSE). In order to achieve this, the following steps have to be executed:
- Scroll to the empty cells at the bottom of
Subtopic Cin your Jupyter Notebook. These will be found beneath the linear-model MSE calculation cell under theActivityheading.Note
You should fill these empty cells in with code as we complete the activity. You may need to insert new cells as these become filled up; please do so as needed.
- Pull out our dependent feature from and target variable from
df. - Verify what
xlooks like by printing the first three samples. - Transform
xinto "polynomial features" by importing the appropriate transformation tool from scikit- - Transform the LSTAT feature (as stored in the variable
x) by running thefit_transformmethod and build the polynomial feature set. - Verify what
x_polylooks like by printing the first few samples. - Import the
LinearRegressionclass and build our linear classification model the same way as done while calculating the MSE. - Extract the coefficients and print the polynomial model.
- Determine the predicted values for each sample and calculate the residuals.
- Print some of the residual values.
- Print the MSE for the third-order polynomial model.
- Plot the polynomial model along with the samples.
- Plot the residuals.
Note
The detailed steps along with the solutions are presented in the Appendix A (pg. no. 144).
Having successfully modeled the data using a polynomial model, let's finish up this chapter by looking at categorical features. In particular, we are going to build a set of categorical features and use them to explore the dataset in more detail.
Using Categorical Features for Segmentation Analysis
Often, we find datasets where there are a mix of continuous and categorical fields. In such cases, we can learn about our data and find patterns by segmenting the continuous variables with the categorical fields.
As a specific example, imagine you are evaluating the return on investment from an ad campaign. The data you have access to contain measures of some calculated return on investment (ROI) metric. These values were calculated and recorded daily and you are analyzing data from the previous year. You have been tasked with finding data-driven insights on ways to improve the ad campaign. Looking at the ROI daily time series, you see a weekly oscillation in the data. Segmenting by day of the week, you find the following ROI distributions (where 0 represents the first day of the week and 6 represents the last).
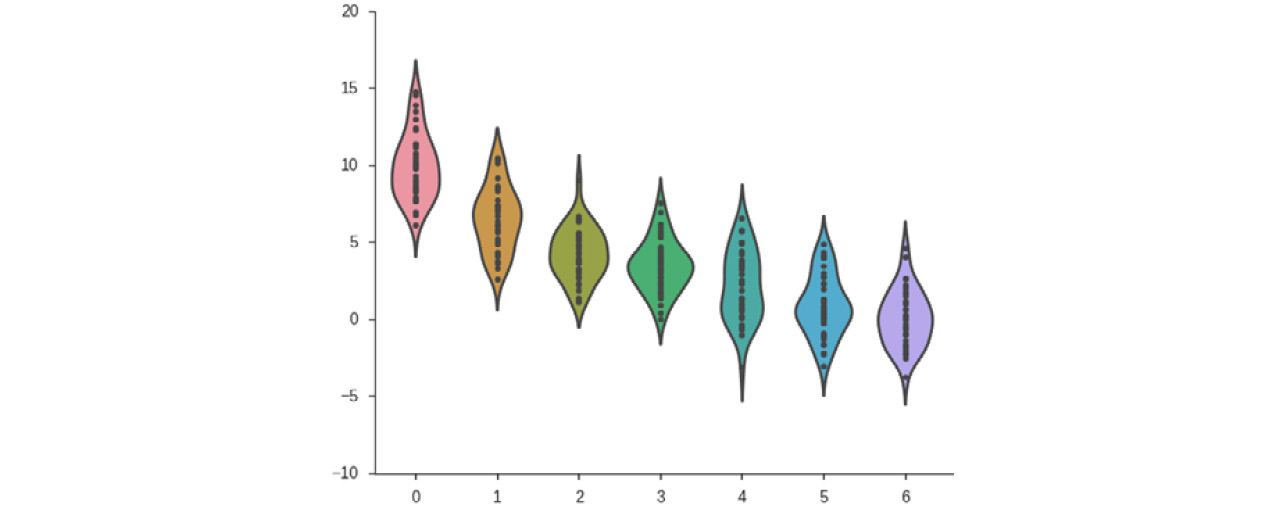
Figure 1.41: A sample violin plot for return on investment
Since we don't have any categorical fields in the Boston housing dataset we are working with, we'll create one by effectively discretizing a continuous field. In our case, this will involve binning the data into "low", "medium", and "high" categories. It's important to note that we are not simply creating a categorical data field to illustrate the data analysis concepts in this section. As will be seen, doing this can reveal insights from the data that would otherwise be difficult to notice or altogether unavailable.
Exercise 7: Creating Categorical Fields From Continuous Variables and Make Segmented Visualizations
- Scroll up to the pairplot in the Jupyter Notebook where we compared MEDV, LSTAT, TAX, AGE, and RM:

Figure 1.42: A comparison of plots for MEDV, LSTAT, TAX, AGE, and RM
Take a look at the panels containing AGE. As a reminder, this feature is defined as the proportion of owner-occupied units built prior to 1940. We are going to convert this feature to a categorical variable. Once it's been converted, we'll be able to replot this figure with each panel segmented by color according to the age category.
- Scroll down to
Subtopic D: Building and exploring categorical featuresand click into the first cell. Type and execute the following to plot the AGE cumulative distribution:sns.distplot(df.AGE.values, bins=100, hist_kws={'cumulative': True}, kde_kws={'lw': 0}) plt.xlabel('AGE') plt.ylabel('CDF') plt.axhline(0.33, color='red') plt.axhline(0.66, color='red') plt.xlim(0, df.AGE.max());
Figure 1.43: Plot for cumulative distribution of AGE
Note that we set
kde_kws={'lw': 0}in order to bypass plotting the kernel density estimate in the preceding figure.Looking at the plot, there are very few samples with low AGE, whereas there are far more with a very large AGE. This is indicated by the steepness of the distribution on the far right-hand side.
The red lines indicate 1/3 and 2/3 points in the distribution. Looking at the places where our distribution intercepts these horizontal lines, we can see that only about 33% of the samples have AGE less than 55 and 33% of the samples have AGE greater than 90! In other words, a third of the housing communities have less than 55% of homes built prior to 1940. These would be considered relatively new communities. On the other end of the spectrum, another third of the housing communities have over 90% of homes built prior to 1940. These would be considered very old. We'll use the places where the red horizontal lines intercept the distribution as a guide to split the feature into categories: Relatively New, Relatively Old, and Very Old.
- Create a new categorical feature and set the segmentation points by running the following code:
def get_age_category(x): if x < 50: return 'Relatively New' elif 50 <= x < 85: return 'Relatively Old' else: return 'Very Old' df['AGE_category'] = df.AGE.apply(get_age_category)
Here, we are using the very handy Pandas method apply, which applies a function to a given column or set of columns. The function being applied, in this case
get_age_category, should take one argument representing a row of data and return one value for the new column. In this case, the row of data being passed is just a single value, the AGE of the sample.Note
The apply method is great because it can solve a variety of problems and allows for easily readable code. Often though, vectorized methods such as
pd.Series.strcan accomplish the same thing much faster. Therefore, it's advised to avoid using it if possible, especially when working with large datasets. We'll see some examples of vectorized methods in the upcoming chapter. - Verify the number of samples we've grouped into each age category by typing
df.groupby('AGE_category').size()into a new cell and running it:
Figure 1.44: Verifying the grouping of variables
Looking at the result, it can be seen that two class sizes are fairly equal, and the Very Old group is about 40% larger. We are interested in keeping the classes comparable in size, so that each is well-represented and it's straightforward to make inferences from the analysis.
Note
It may not always be possible to assign samples into classes evenly, and in real-world situations, it's very common to find highly imbalanced classes. In such cases, it's important to keep in mind that it will be difficult to make statistically significant claims with respect to the under-represented class. Predictive analytics with imbalanced classes can be particularly difficult. The following blog post offers an excellent summary on methods for handling imbalanced classes when doing machine learning: https://svds.com/learning- imbalanced-classes/.
Let's see how the target variable is distributed when segmented by our new feature
AGE_category. - Construct a violin plot by running the following code:
sns.violinplot(x='MEDV', y='AGE_category', data=df, order=['Relatively New', 'Relatively Old', 'Very Old']);

Figure 1.45: Violin plot for AGE_category and MEDV
The violin plot shows a kernel density estimate of the median house value distribution for each age category. We see that they all resemble a normal distribution. The Very Old group contains the lowest median house value samples and has a relatively large width, whereas the other groups are more tightly centered around their average. The young group is skewed to the high end, which is evident from the enlarged right half and position of the white dot in the thick black line within the body of the distribution.
This white dot represents the mean and the thick black line spans roughly 50% of the population (it fills to the first quantile on either side of the white dot). The thin black line represents boxplot whiskers and spans 95% of the population. This inner visualization can be modified to show the individual data points instead by passing
inner='point'tosns.violinplot(). Let's do that now. - Re-construct the violin plot adding the
inner='point'argument to thesns.violinplotcall:
Figure 1.46: Violin plot for AGE_category and MEDV with the inner = 'point' argument
It's good to make plots like this for test purposes in order to see how the underlying data connects to the visual. We can see, for example, how there are no median house values lower than roughly $16,000 for the Relatively New segment, and therefore the distribution tail actually contains no data. Due to the small size of our dataset (only about 500 rows), we can see this is the case for each segment.
- Re-construct the pairplot from earlier, but now include color labels for each AGE category. This is done by simply passing the
hueargument, as follows:cols = ['RM', 'AGE', 'TAX', 'LSTAT', 'MEDV', 'AGE_ category'] sns.pairplot(df[cols], hue='AGE_category', hue_order=['Relatively New', 'Relatively Old', 'Very Old'], plot_kws={'alpha': 0.5}, diag_kws={'bins': 30});
Figure 1.47: Re-constructing pairplot for all variables using color labels for AGE
Looking at the histograms, the underlying distributions of each segment appear similar for RM and TAX. The LSTAT distributions, on the other hand, look more distinct. We can focus on them in more detail by again using a violin plot.
- Re-construct a violin plot comparing the LSTAT distributions for each
AGE_categorysegment:
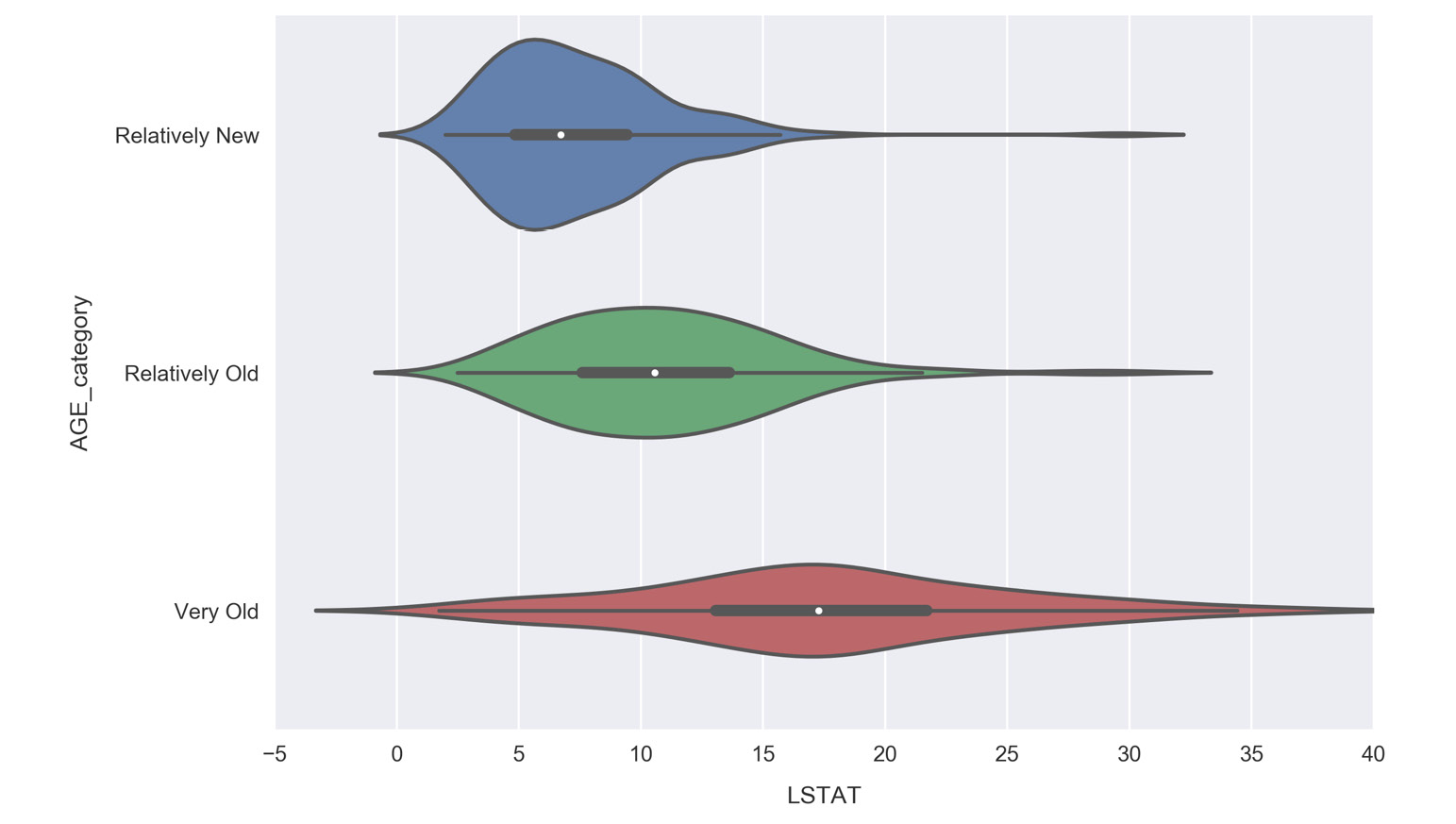
Figure 1.48: Re-constructed violin plots for comparing LSTAT distributions for the AGE_category
Unlike the MEDV violin plot, where each distribution had roughly the same width, here we see the width increasing along with AGE. Communities with primarily old houses (the Very Old segment) contain anywhere from very few to many lower class residents, whereas Relatively New communities are much more likely to be predominantly higher class, with over 95% of samples having less lower class percentages than the Very Old communities. This makes sense, because Relatively New neighborhoods would be more expensive.






















