






















































5. Temporal-difference learning
Q-learning is a special case of a more generalized TD learning,  . More specifically, it is a special case of one-step TD learning, TD(0):
. More specifically, it is a special case of one-step TD learning, TD(0):
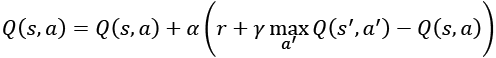 (Equation 9.5.1)
(Equation 9.5.1)Where  is the learning rate. Note that when
is the learning rate. Note that when  , Equation 9.5.1 is similar to the Bellman equation. For simplicity, we also refer to Equation 9.5.1 as Q-learning, or generalized Q-learning.
, Equation 9.5.1 is similar to the Bellman equation. For simplicity, we also refer to Equation 9.5.1 as Q-learning, or generalized Q-learning.
Previously, we referred to Q-learning as an off-policy RL algorithm since it learns the Q value function without directly using the policy that it is trying to optimize. An example of an on-policy one-step TD-learning algorithm is SARSA, which is similar to Equation 9.5.1:
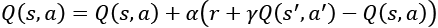 (Equation 9.5.2)
(Equation 9.5.2)The main difference is the use of the policy that is being optimized to determine  . The terms
. The terms  ,
,  ,
,  ,
,  , and
, and  (thus the name SARSA) must be known to update the Q value function every iteration. Both Q-learning and SARSA use existing estimates in the Q value iteration, a process known as bootstrapping...
(thus the name SARSA) must be known to update the Q value function every iteration. Both Q-learning and SARSA use existing estimates in the Q value iteration, a process known as bootstrapping...






















