






















































What Is Amazon S3?
S3 is an online cloud object storage and retrieval service. Instead of data being associated with a server, S3 storage is server-independent and can be accessed over the internet. Data stored in S3 is managed as objects using an Application Programming Interface (API) that is accessible via the internet (HTTPS).
The benefits of using S3 are as follows:
- Amazon S3 runs on the largest global cloud infrastructure to deliver 99.99% durability.
- It provides the widest range of options to transfer data.
- It allows you to run big data analytics without moving data into a separate analytics system.
- It supports security standards and compliance certificates.
- It offers a flexible set of storage management and administration capabilities.
Note
For more information, visit https://aws.amazon.com/s3/.
Why Use S3?
S3 is a place to store and retrieve your files. It is recommended for storing static content such as text files, images, audio files, and video files. For example, S3 can be used as a static web server if the website consists exclusively of HTML and images. The website can be connected to an FTP client to serve the static files. In addition, S3 can be used to store user-generated images and text files.
However, the two most important applications of S3 are as follows:
- To store static data from web pages or mobile apps
- To implement big data analytics
It can easily be used in conjunction with additional AWS ML and infrastructure services. For example, text documents imported to Amazon S3 can be summarized by code running in an AWS Lambda function that is analyzed using AWS Comprehend. We will cover AWS Lambda and AWS Comprehend in Chapter 2, Analyzing Documents and Text with Natural Language Processing, and Chapter 3, Topic Modeling and Theme Extraction.
The Basics of Working on AWS with S3
The first step to accessing S3 is to create an AWS free-tier account, which provides access to the AWS Management Console. The AWS Management Console is a web application that provides one method to access all AWS's powerful storage and ML/AI services.
The second step is to understand the access level. AWS defines identity and access management (IAM). The same email/password is used to access IAM.
AWS Free-Tier Account
AWS provides a free-tier (within their individual free usage stipulations) account, and one of the included storage services is S3. Thus, you can maximize cost savings and reduce errors before making a large investment by testing services to optimize your ML and AI workflows.
AWS Account Setup and Navigation
Generally, you need an AWS account with Amazon. A good description of the steps is available at https://support.sou.edu/kb/articles/amazon-web-services-account-creation. The steps might vary a little bit, as Amazon might make changes to its processes.
The general steps are:
- Create a personal account (if needed; many of you might already be Amazon customers), which might also need a security check.
- Create an AWS account. AWS account creation also requires credit card information. But you can also use credit codes.
- The AWS free tier offers limited capability for 1 year. The details are at https://aws.amazon.com/free/?all-free-tier.sort-by=item.additionalFields.SortRank&all-free-tier.sort-order=asc.
Downloading the Support Materials for This Book
In this book, you will be programming AWS APIs using Jupyter notebooks, uploading images for AI services and text files to S3, and even writing short code for Lambda functions. These files and programs are located in a GitHub repository, https://packt.live/2O67hxH. You can download the files using the Download ZIP button and then unzip the file:
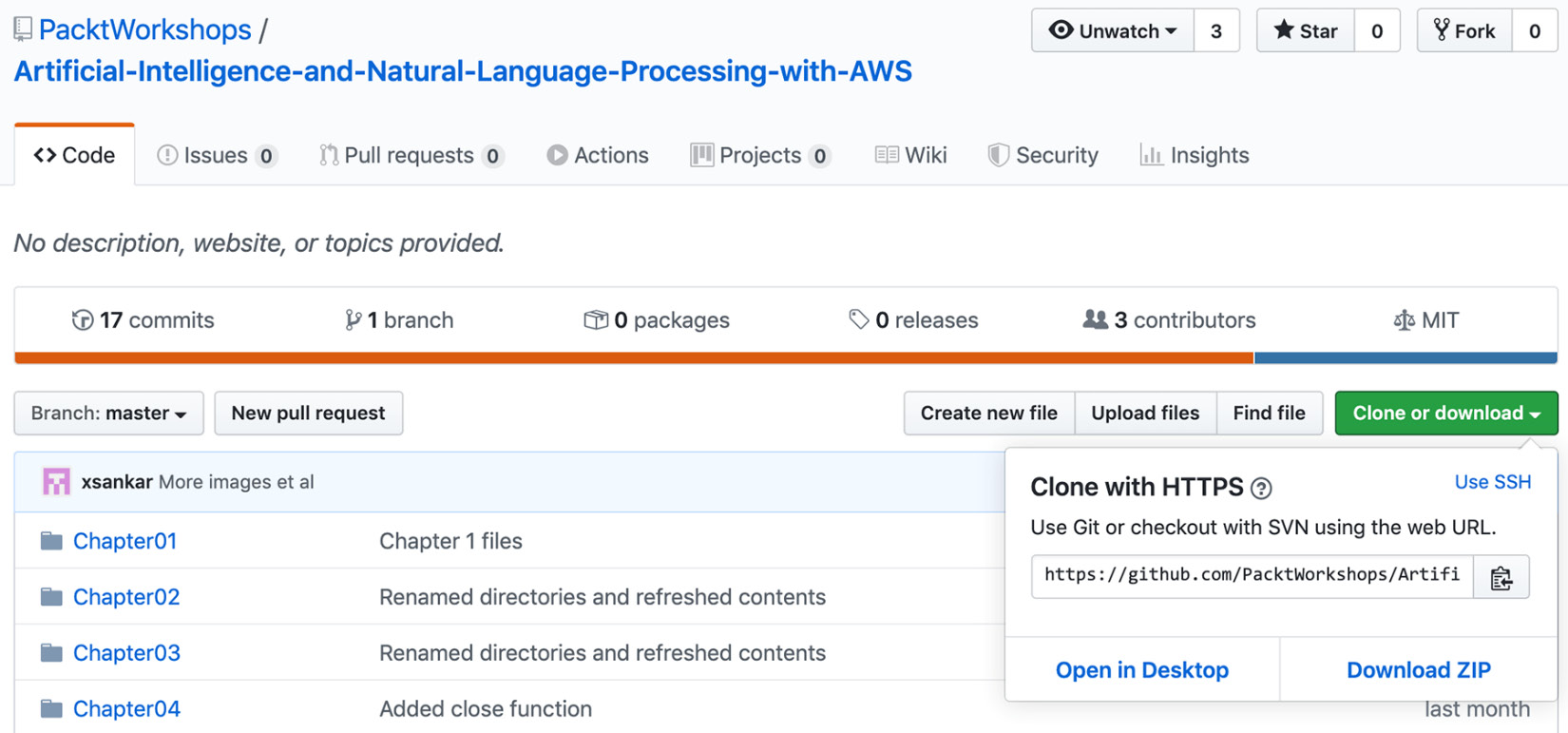
Figure 1.1: Download support files from GitHub
As an example, we have downloaded the files into the Documents/aws-book/The-Applied-AI-and-Natural-Language-Processing-with-AWS directory:
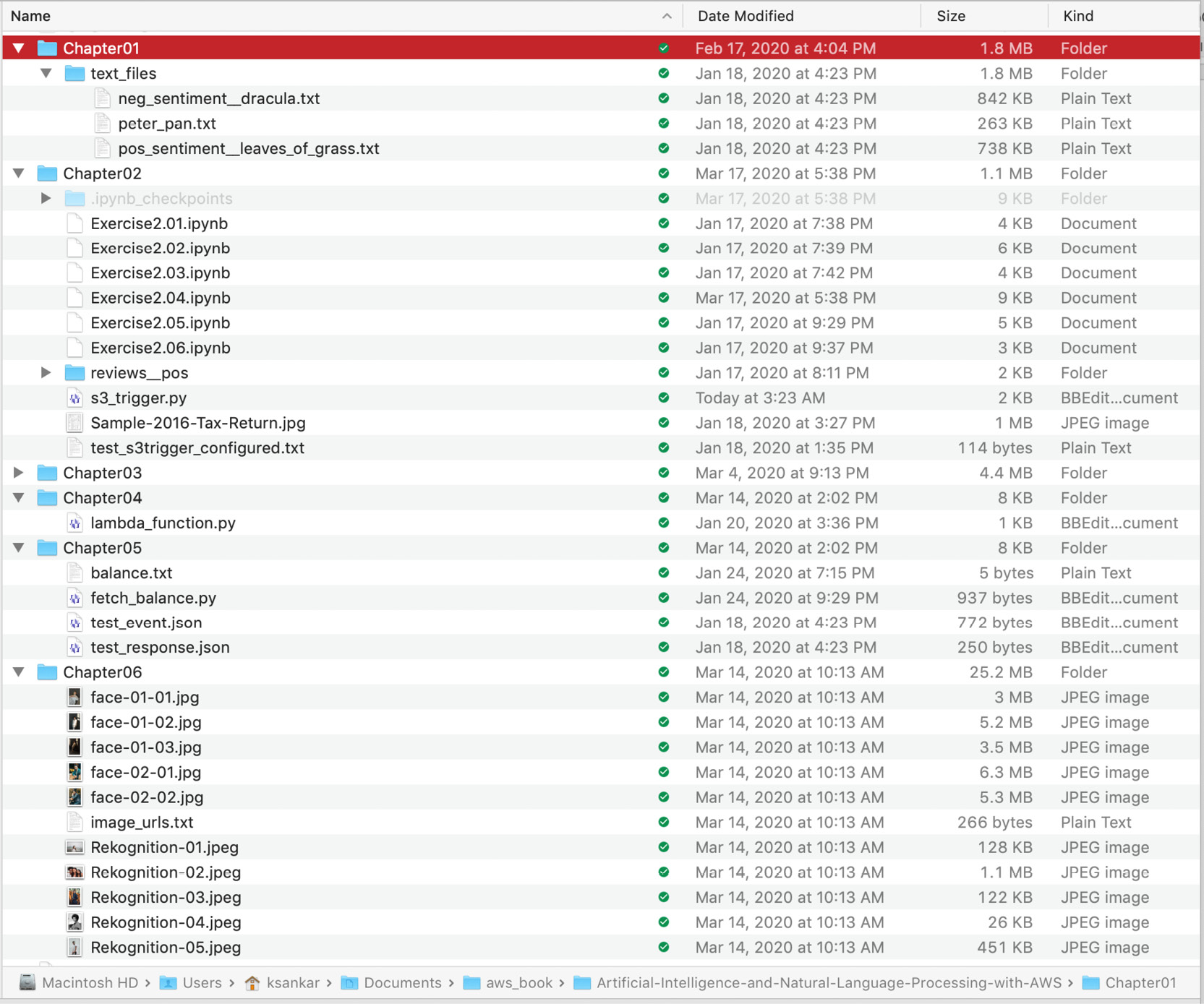
Figure 1.2: Support files from GitHub in a local directory
A Word about Jupyter Notebooks
Some of the programs in this book use Jupyter notebooks to run. You will recognize them by the .ipynb file extensions. If you haven't already used Jupyter notebooks, please follow the Installation and setup in the Preface.
Importing and Exporting Data into S3
The way AWS handles big data is by providing the AWS Import/Export service, which allows you to transfer large amounts of data to AWS.
How it works is you mail your storage device to AWS, and AWS will transfer that data using Amazon's high-speed network. Your big data will be loaded into AWS the next business day after it arrives. Once data has been loaded, the storage device is returned to the owner. This is a more cost-efficient way of transferring huge amounts of data and is much faster than transferring it via the internet.
If the amount of data that you need to put into S3 is relatively small, you can simply upload it from your computer. Today, with the increasing capacity of broadband networks, "small" becomes bigger and bigger. Our guideline is 1 TB. Once you have more than this, you may need to think of faster ways to put the data in S3. One of them is the AWS Import/Export Disk Service (https://aws.amazon.com/snowball/disk/details/), where you package your data on a device provided by AWS and ship it to them. Significant amounts of data can then be loaded within a day or a few days.
How S3 Differs from a Filesystem
S3 is used to store almost any type of file, thus, it can get confused with a traditional filesystem because of this similarity. However, S3 differs in a few ways from a traditional filesystem. The folders in a traditional filesystem are buckets in S3; a file in a traditional filesystem is an object in S3. S3 uses objects since you can store any data type (that is, more than files) in buckets.
Another difference is how objects can be accessed. Objects stored in buckets can be accessed from a web service endpoint (such as a web browser, for example, Chrome or Firefox), so each object requires a globally unique name. The name restrictions for objects are similar to the restrictions in selecting a URL when creating a new website. You need to select a unique URL, according to the same logic that your house has a unique address.
For example, if you created a bucket (with public permission settings) named myBucket and then uploaded a text file named pos_sentiment__leaves_of_grass.txt to the bucket, the object would be accessible from a web browser via the corresponding subdomain.




