






















































In the previous section, we were processing on raw text and looked at concepts at the sentence level. In this section, we are going to look at the concepts of tokenization, lemmatization, and so on at the word level.
Handling corpus-raw sentences
Word tokenization
Word tokenization is defined as the process of chopping a stream of text up into words, phrases, and meaningful strings. This process is called word tokenization. The output of the process are words that we will get as an output after tokenization. This is called a token.
Let's see the code snippet given in Figure 4.11 of tokenized words:
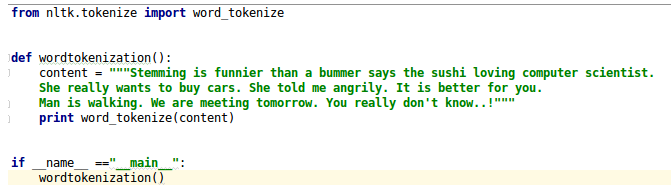
Figure 4.11: Word tokenized code snippet
The output of the code given in Figure 4.11 is as follows:
The input for word tokenization...























