





















































The ARMA model blends autoregression and moving averages. The ARMA model is commonly referred to as ARMA(p,q), where p is the order of the autoregressive part, and q is the order of the moving average:
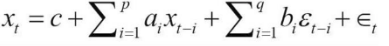
In the preceding formula, just like in the autoregressive model formula, we have a constant and a white noise component; however, we try to fit the lagged noise components as well:
- Import the libraries and read the dataset:
# import needful libraries
import statsmodels.api as sm
from statsmodels.tsa.arima_model import ARMA
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
from math import sqrt
# Read the dataset
data = sm.datasets.sunspots.load_pandas().data
data.drop('YEAR',axis=1,inplace=True)
- Split the Sunspot data into train and test sets:
# Split data into train and test set
train_ratio=0.8
train=data[:int(train_ratio*len(data))]
test=data[int(train_ratio...



















