






















































Optimizing NLP models with transformers
Recurrent Neural Networks (RNNs), including LSTMs, have applied neural networks to NLP sequence models for decades. However, using recurrent functionality reaches its limit when faced with long sequences and large numbers of parameters. Thus, state-of-the-art transformer models now prevail.
This section goes through a brief background of NLP that led to transformers, which we’ll describe in more detail in Chapter 2, Getting Started with the Architecture of the Transformer Model. First, however, let’s have an intuitive look at the attention head of a transformer that has replaced the RNN layers of an NLP neural network.
The core concept of a transformer can be summed up loosely as “mixing tokens.” NLP models first convert word sequences into tokens. RNNs analyze tokens in recurrent functions. Transformers do not analyze tokens in sequences but relate every token to the other tokens in a sequence, as shown in Figure 1.3:
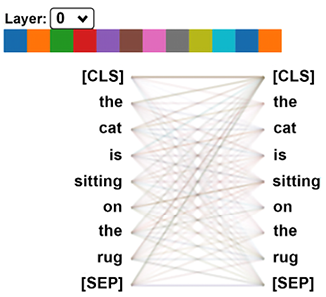
Figure 1.3: An attention head of a layer of a transformer
We will go through the details of an attention head in Chapter 2. For the moment, the takeaway of Figure 1.3 is that each word (token) of a sequence is related to all the other words of a sequence. This model opens the door to Industry 4.0 NLP.
Let’s briefly go through the background of transformers.
The background of transformers
Over the past 100+ years, many great minds have worked on sequence patterns and language modeling. As a result, machines progressively learned how to predict probable sequences of words. It would take a whole book to cite all the giants that made this happen.
In this section, I will share some of my favorite researchers with you to lay the grounds for the arrival of the Transformer.
In the early 20th century, Andrey Markov introduced the concept of random values and created a theory of stochastic processes. We know them in AI as the Markov Decision Process (MDP), Markov Chains, and Markov Processes. In the early 20th century, Markov showed that we could predict the next element of a chain, a sequence, using only the last past elements of that chain. He applied his method to a dataset containing thousands of letters using past sequences to predict the following letters of a sentence. Bear in mind that he had no computer but proved a theory still in use today in artificial intelligence.
In 1948, Claude Shannon’s The Mathematical Theory of Communication was published. Claude Shannon laid the grounds for a communication model based on a source encoder, transmitter, and a receiver or semantic decoder. He created information theory as we know it today.
In 1950, Alan Turing published his seminal article: Computing Machinery and Intelligence. Alan Turing based this article on machine intelligence on the successful Turing machine, which decrypted German messages during World War II. The messages consisted of sequences of words and numbers.
In 1954, the Georgetown-IBM experiment used computers to translate Russian sentences into English using a rule system. A rule system is a program that runs a list of rules that will analyze language structures. Rule systems still exist and are everywhere. However, in some cases, machine intelligence can replace rule lists for the billions of language combinations by automatically learning the patterns.
The expression “Artificial Intelligence” was first used by John McCarthy in 1956 when it was established that machines could learn.
In 1982, John Hopfield introduced an RNN, known as Hopfield networks or “associative” neural networks. John Hopfield was inspired by W.A. Little, who wrote The existence of persistent states in the brain in 1974, which laid the theoretical grounds of learning processes for decades. RNNs evolved, and LSTMs emerged as we know them today.
An RNN memorizes the persistent states of a sequence efficiently, as shown in Figure 1.4:
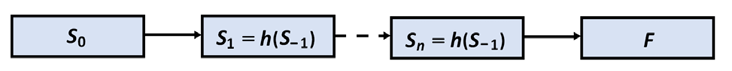
Figure 1.4: The RNN process
Each state Sn captures the information of Sn-1. When the network’s end is reached, a function F will perform an action: transduction, modeling, or any other type of sequence-based task.
In the 1980s, Yann LeCun designed the multipurpose Convolutional Neural Network (CNN). He applied CNNs to text sequences, and they also apply to sequence transduction and modeling. They are also based on W.A. Little’s persistent states that process information layer by layer. In the 1990s, summing up several years of work, Yann LeCun produced LeNet-5, which led to the many CNN models we know today. However, a CNN’s otherwise efficient architecture faces problems when dealing with long-term dependencies in lengthy and complex sequences.
We could mention many other great names, papers, and models that would humble any AI specialist. It seemed that everybody in AI was on the right track for all these years. Markov Fields, RNNs, and CNNs evolved into multiple other models. The notion of attention appeared: peeking at other tokens in a sequence, not just the last one. It was added to the RNN and CNN models.
After that, if AI models needed to analyze longer sequences requiring increasing computer power, AI developers used more powerful machines and found ways to optimize gradients.
Some research was done on sequence-to-sequence models, but they did not meet expectations.
It seemed that nothing else could be done to make more progress. Thirty years passed this way. And then, starting late 2017, the industrialized state-of-the-art Transformer came with its attention head sublayers and more. RNNs did not appear as a pre-requisite for sequence modeling anymore.
Before diving into the original Transformer’s architecture, which we will do in Chapter 2, Getting Started with the Architecture of the Transformer Model, let’s start at a high level by examining the paradigm change in software resources we should use to learn and implement transformer models.

