






















































Sentiment analysis
Twitter is one of the most popular social media platforms and an important communication tool for many, individuals and companies alike.
Capturing sentiment in language is particularly important in the latter context: a positive tweet can go viral and spread the word, while a particularly negative one can be harmful. Since human language is complicated, it is important not to just decide on the sentiment, but also to be able to investigate the how: which words actually led to the sentiment description?
We will demonstrate an approach to this problem by using data from the Tweet Sentiment Extraction competition (https://www.kaggle.com/c/tweet-sentiment-extraction). For brevity, we have omitted the imports from the following code, but you can find them in the corresponding Notebook in the GitHub repo for this chapter.
To get a better feel for the problem, let’s start by looking at the data:
df = pd.read_csv('/kaggle/input/tweet-sentiment-extraction/train.csv')
df.head()
Here are the first few rows:
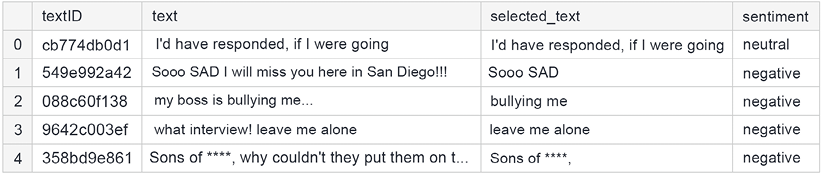
Figure 11.1: Sample rows from the training data
The actual tweets are stored in the text column. Each of them has an associated sentiment, along with the support phrase stored in the selected_text column (the part of the tweet that was the basis for the decision on sentiment assignment).
We start by defining basic cleanup functions. First, we want to get rid of website URLs and non-characters and replace the stars people use in place of swear words with a single token, "swear". We use some regular expressions to help us do this:
def basic_cleaning(text):
text=re.sub(r'https?://www\.\S+\.com','',text)
text=re.sub(r'[^A-Za-z|\s]','',text)
text=re.sub(r'\*+','swear',text) # Capture swear words that are **** out
return text
Next, we remove HTML from the content of the tweets, as well as emojis:
def remove_html(text):
html=re.compile(r'<.*?>')
return html.sub(r'',text)
def remove_emoji(text):
emoji_pattern = re.compile("["
u"\U0001F600-\U0001F64F" #emoticons
u"\U0001F300-\U0001F5FF" #symbols & pictographs
u"\U0001F680-\U0001F6FF" #transport & map symbols
u"\U0001F1E0-\U0001F1FF" #flags (iOS)
u"\U00002702-\U000027B0"
u"\U000024C2-\U0001F251"
"]+", flags=re.UNICODE)
return emoji_pattern.sub(r'', text)
Lastly, we want to be able to remove repeated characters (for example, so we have “way” instead of “waaaayyyyy”):
def remove_multiplechars(text):
text = re.sub(r'(.)\1{3,}',r'\1', text)
return text
For convenience, we combine the four functions into a single cleanup function:
def clean(df):
for col in ['text']:#,'selected_text']:
df[col]=df[col].astype(str).apply(lambda x:basic_cleaning(x))
df[col]=df[col].astype(str).apply(lambda x:remove_emoji(x))
df[col]=df[col].astype(str).apply(lambda x:remove_html(x))
df[col]=df[col].astype(str).apply(lambda x:remove_multiplechars(x))
return df
The last bit of preparation involves writing functions for creating the embeddings based on a pre-trained model (the tokenizer argument):
def fast_encode(texts, tokenizer, chunk_size=256, maxlen=128):
tokenizer.enable_truncation(max_length=maxlen)
tokenizer.enable_padding(max_length=maxlen)
all_ids = []
for i in range(0, len(texts), chunk_size):
text_chunk = texts[i:i+chunk_size].tolist()
encs = tokenizer.encode_batch(text_chunk)
all_ids.extend([enc.ids for enc in encs])
return np.array(all_ids)
Next, we create a pre-processing function enabling us to work with the entire corpus:
def preprocess_news(df,stop=stop,n=1,col='text'):
'''Function to preprocess and create corpus'''
new_corpus=[]
stem=PorterStemmer()
lem=WordNetLemmatizer()
for text in df[col]:
words=[w for w in word_tokenize(text) if (w not in stop)]
words=[lem.lemmatize(w) for w in words if(len(w)>n)]
new_corpus.append(words)
new_corpus=[word for l in new_corpus for word in l]
return new_corpus
Using our previously prepared functions, we can clean and prepare the training data. The sentiment column is our target, and we convert it to dummy variables (one-hot encoding) for performance:
df.dropna(inplace=True)
df_clean = clean(df)
df_clean_selection = df_clean.sample(frac=1)
X = df_clean_selection.text.values
y = pd.get_dummies(df_clean_selection.sentiment)
A necessary next step is tokenization of the input texts, as well as conversion into sequences (along with padding, to ensure equal lengths across the dataset):
tokenizer = text.Tokenizer(num_words=20000)
tokenizer.fit_on_texts(list(X))
list_tokenized_train = tokenizer.texts_to_sequences(X)
X_t = sequence.pad_sequences(list_tokenized_train, maxlen=128)
We will create the embeddings for our model using DistilBERT and use them as-is. DistilBERT is a lightweight version of BERT: the tradeoff is 3% performance loss at 40% fewer parameters. We could train the embedding layer and gain performance – at the cost of massively increased training time.
tokenizer = transformers.AutoTokenizer.from_pretrained("distilbert-base-uncased")
# Save the loaded tokenizer locally
save_path = '/kaggle/working/distilbert_base_uncased/'
if not os.path.exists(save_path):
os.makedirs(save_path)
tokenizer.save_pretrained(save_path)
# Reload it with the huggingface tokenizers library
fast_tokenizer = BertWordPieceTokenizer(
'distilbert_base_uncased/vocab.txt', lowercase=True)
fast_tokenizer
We can use the previously defined fast_encode function, along with the fast_tokenizer defined above, to encode the tweets:
X = fast_encode(df_clean_selection.text.astype(str),
fast_tokenizer,
maxlen=128)
With the data prepared, we can construct the model. For the sake of this demonstration, we will go with a fairly standard architecture for these applications: a combination of LSTM layers, normalized by global pooling and dropout, and a dense layer on top. In order to achieve a truly competitive solution, some tweaking of the architecture would be needed: a “heavier” model, bigger embeddings, more units in the LSTM layers, and so on.
transformer_layer = transformers.TFDistilBertModel.from_pretrained('distilbert-base-uncased')
embedding_size = 128
input_ = Input(shape=(100,))
inp = Input(shape=(128, ))
embedding_matrix=transformer_layer.weights[0].numpy()
x = Embedding(embedding_matrix.shape[0],
embedding_matrix.shape[1],
embeddings_initializer=Constant(embedding_matrix),
trainable=False)(inp)
x = Bidirectional(LSTM(50, return_sequences=True))(x)
x = Bidirectional(LSTM(25, return_sequences=True))(x)
x = GlobalMaxPool1D()(x)
x = Dropout(0.5)(x)
x = Dense(50, activation='relu', kernel_regularizer='L1L2')(x)
x = Dropout(0.5)(x)
x = Dense(3, activation='softmax')(x)
model_DistilBert = Model(inputs=[inp], outputs=x)
model_DistilBert.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
There is no special need to pay attention to a temporal dimension of the data, so we are fine with a random split into training and validation, which can be achieved inside a call to the fit method:
model_DistilBert.fit(X,y,batch_size=32,epochs=10,validation_split=0.1)
Below is some sample output:
Epoch 1/10
27480/27480 [==============================] - 480s 17ms/step - loss: 0.5100 - accuracy: 0.7994
Epoch 2/10
27480/27480 [==============================] - 479s 17ms/step - loss: 0.4956 - accuracy: 0.8100
Epoch 3/10
27480/27480 [==============================] - 475s 17ms/step - loss: 0.4740 - accuracy: 0.8158
Epoch 4/10
27480/27480 [==============================] - 475s 17ms/step - loss: 0.4528 - accuracy: 0.8275
Epoch 5/10
27480/27480 [==============================] - 475s 17ms/step - loss: 0.4318 - accuracy: 0.8364
Epoch 6/10
27480/27480 [==============================] - 475s 17ms/step - loss: 0.4069 - accuracy: 0.8441
Epoch 7/10
27480/27480 [==============================] - 477s 17ms/step - loss: 0.3839 - accuracy: 0.8572
Generating a prediction from the fitted model proceeds in a straightforward manner. In order to utilize all the available data, we begin by re-training our model on all available data (so no validation):
df_clean_final = df_clean.sample(frac=1)
X_train = fast_encode(df_clean_selection.text.astype(str),
fast_tokenizer,
maxlen=128)
y_train = y
We refit the model on the entire dataset before generating the predictions:
Adam_name = adam(lr=0.001)
model_DistilBert.compile(loss='categorical_crossentropy',optimizer=Adam_name,metrics=['accuracy'])
history = model_DistilBert.fit(X_train,y_train,batch_size=32,epochs=10)
Our next step is to process the test data into the same format we are using for training data fed into the model:
df_test = pd.read_csv('/kaggle/input/tweet-sentiment-extraction/test.csv')
df_test.dropna(inplace=True)
df_clean_test = clean(df_test)
X_test = fast_encode(df_clean_test.text.values.astype(str),
fast_tokenizer,
maxlen=128)
y_test = df_clean_test.sentiment
Finally, we generate the predictions:
y_preds = model_DistilBert.predict(X_test)
y_predictions = pd.DataFrame(y_preds,
columns=['negative','neutral','positive'])
y_predictions_final = y_predictions.idxmax(axis=1)
accuracy = accuracy_score(y_test,y_predictions_final)
print(f"The final model shows {accuracy:.2f} accuracy on the test set.")
The final model shows 0.74 accuracy on the test set. Below we show a sample of what the output looks like; as you can see already from these few rows, there are some instances where the sentiment is obvious to a human reader, but the model fails to capture it:
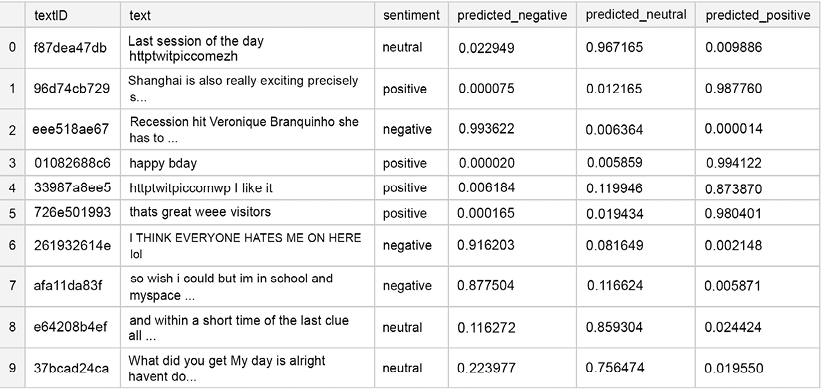
Figure 11.2: Example rows from the predicted results
We have now demonstrated a sample pipeline for solving sentiment attribution problems (identifying parts of the text that lead to annotator decisions on sentiment classification). There are some improvements that can be made if you want to achieve competitive performance, given below in order of likely impact:
- Larger embeddings: This allows us to capture more information already at the (processed) input data level
- Bigger model: More units in the LSTM layers
- Longer training: In other words, more epochs
While the improvements listed above will undoubtedly boost the performance of the model, the core elements of our pipeline are reusable:
- Data cleaning and pre-processing
- Creating text embeddings
- Incorporating recurrent layers and regularization in the target model architecture
We’ll now move on to a discussion of open domain question answering, a frequent problem encountered in NLP competitions.

Abhishek Thakur
https://www.kaggle.com/abhishek
We caught up with Abhishek Thakur, the world’s first quadruple Kaggle Grandmaster. He currently works at Hugging Face, where he is building AutoNLP; he also wrote pretty much the only book on Kaggle in English (aside from this one!), Approaching (Almost) Any Machine Learning Problem.
What’s your specialty on Kaggle?
None. Every competition is different and there is so much to learn from each one of them. If I were to have a specialty, I would win all competitions in that domain.
How do you approach a Kaggle competition? How different is this approach to what you do in your day-to-day work?
The first thing I do is to take a look at the data and try to understand it a bit. If I’m late to the competition, I take the help of public EDA kernels.
The first thing I do when approaching a problem on (or off) Kaggle is to build a benchmark. Building a benchmark is very important as it provides you with a baseline you can compare your future models to. If I’m late to the game, for building the baseline, I try not to take the help of public Notebooks. If we do that, we think only in a single direction. At least, that’s what I feel.
When I am done with a benchmark, I try to squeeze as much as possible without doing anything complicated like stacking or blending. Then I go over the data and models again and try to improve on the baseline, one step at a time.
Day-to-day work sometimes has a lot of similarities. Most of the time there is a benchmark and then you have to come up with techniques, features, models that beat the benchmark.
What was the most interesting competition you entered? Did you have any special insights?
Every competition is interesting.
Has Kaggle helped you in your career?
Sure, it has helped. In the last few years, Kaggle has gained a very good reputation when it comes to hiring data scientists and machine learning engineers. Kaggle rank and experience with many datasets is something that surely helps in the industry in one way or another. The more experienced you are with approaching different types of problems, the faster you will be able to iterate. And that’s something very useful in industries. No one wants to spend several months doing something that doesn’t bring any value to the business.
In your experience, what do inexperienced Kagglers often overlook? What do you know now that you wish you’d known when you first started?
Most beginners give up quite easily. It’s very easy to join a Kaggle competition and get intimidated by top scorers. If beginners want to succeed on Kaggle, they have to have perseverance. In my opinion, perseverance is the key. Many beginners also fail to start on their own and stick to public kernels. This makes them think like the authors of public kernels. My advice would be to start with competitions on your own, look at data, build features, build models, and then dive into kernels and discussions to see what others might be doing differently. Then incorporate what you have learned into your own solution.


