






















































Introduction – the OpenStack architecture
OpenStack is a suite of projects that combine into a software-defined environment to be consumed using cloud friendly tools and techniques. The popular open source software allows users to easily consume compute, network, and storage resources that have been traditionally controlled by disparate methods and tools by various teams in IT departments, big and small. While consistency of APIs can be achieved between versions of OpenStack, an administrator is free to choose which features of OpenStack to install, and as such there is no single method or architecture to install the software. This flexibility can lead to confusion when choosing how to deploy OpenStack. That said, it is universally agreed that the services that the end users interact with—the OpenStack services, supporting software (such as the databases), and APIs—must be highly available.
A very popular method for installing OpenStack is the OpenStack-Ansible project (https://github.com/openstack/openstack-ansible). This method of installation allows an administrator to define highly available controllers together with arrays of compute and storage, and through the use of Ansible, deploy OpenStack in a very consistent way with a small amount of dependencies. Ansible is a tool that allows for system configuration and management that operates over standard SSH connections. Ansible itself has very few dependencies, and as it uses SSH to communicate, most Linux distributions and networks are well-catered for when it comes to using this tool. It is also very popular with many system administrators around the globe, so installing OpenStack on top of what they already know lowers the barrier to entry for setting up a cloud environment for their enterprise users.
OpenStack can be architected in any number of ways; OpenStack-Ansible doesn't address the architecture problem directly: users are free to define any number of controller services (such as Horizon, Neutron Server, Nova Server, and MySQL). Through experience at Rackspace and feedback from users, a popular architecture is defined, which is shown here:
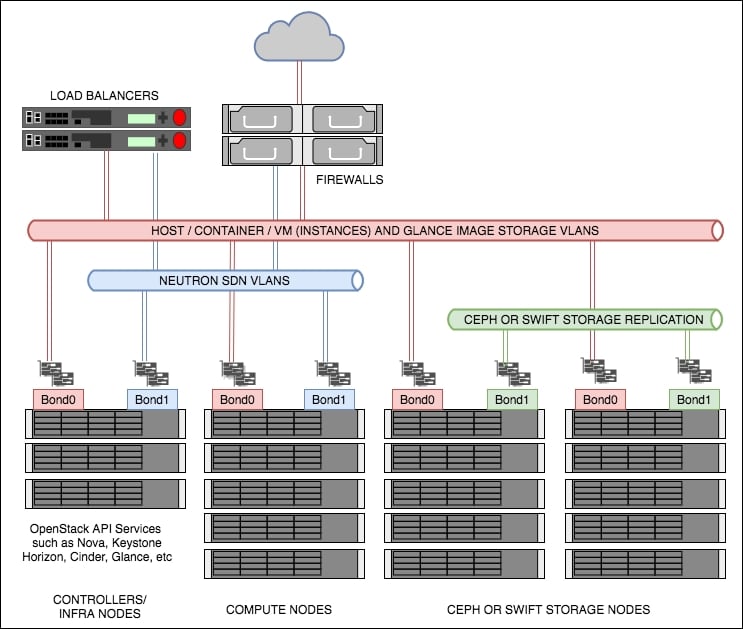
Figure 1: Recommended OpenStack architecture used in this book
As shown in the preceding diagram (Figure 1), there are a few concepts to first understand. These are described as follows.
Controllers
The controllers (also referred to as infrastructure or infra nodes) run the heart of the OpenStack services and are the only servers exposed (via load balanced pools) to your end users. The controllers run the API services, such as Nova API, Keystone API, and Neutron API, as well as the core supporting services such as MariaDB for the database required to run OpenStack, and RabbitMQ for messaging. It is this reason why, in a production setting, these servers are set up as highly available as required. This means that these are deployed as clusters behind (highly available) load balancers, starting with a minimum of 3 in the cluster. Using odd numbers starting from 3 allows clusters to lose a single server without and affecting service and still remain with quorum (minimum numbers of votes needed). This means that when the unhealthy server comes back online, the data can be replicated from the remaining 2 servers (which are, between them, consistent), thus ensuring data consistency.
Networking is recommended to be highly resilient, so ensure that Linux has been configured to bond or aggregate the network interfaces so that in the event of a faulty switch port, or broken cable, your services remain available. An example networking configuration for Ubuntu can be found in Appendix A.
Computes
These are the servers that run the hypervisor or container service that OpenStack schedules workloads to when a user requests a Nova resource (such as a virtual machine). These are not too dissimilar to hosts running a hypervisor, such as ESXi or Hyper-V, and OpenStack Compute servers can be configured in a very similar way, optionally using shared storage. However, most installations of OpenStack forgo the need for the use of shared storage in the architecture. This small detail of not using shared storage, which implies the virtual machines run from the hard disks of the compute host itself, can have a large impact on the users of your OpenStack environment when it comes to discussing the resiliency of the applications in that environment. An environment set up like this pushes most of the responsibility for application uptime to developers, which gives the greatest flexibility of a long-term cloud strategy. When an application relies on the underlying infrastructure to be 100% available, the gravity imposed by the infrastructure ties applications to specific data center technology to keep it running. However, OpenStack can be configured to introduce shared storage such as Ceph (http://ceph.com/) to allow for operational features such as live-migration (the ability to move running instances from one hypervisor to another with no downtime), allowing enterprise users move their applications to a cloud environment in a very safe way. These concepts will be discussed in more detail in later chapters on compute and storage. As such, the reference architecture for a compute node is to expect virtual machines to run locally on the hard drives in the server itself.
With regard to networking, like the controllers, the network must also be configured to be highly available. A compute node that has no network available might be very secure, but it would be equally useless to a cloud environment! Configure bonded interfaces in the same way as the controllers. Further information for configuring bonded interfaces under Ubuntu can be found in Appendix A.
Storage
Storage in OpenStack refers to block storage and object storage. Block storage (providing LUNs or hard drives to virtual machines) is provided by the Cinder service, while object storage (API driven object or blobs of storage) is provided by Swift or Ceph. Swift and Ceph manage each individual drive in a server designated as an object storage node, very much like a RAID card manages individual drives in a typical server. Each drive is an independent entity that Swift or Ceph uses to write data to. For example, if a storage node has 24 x 2.5in SAS disks in, Swift or Ceph will be configured to write to any one of those 24 disks. Cinder, however, can use a multitude of backends to store data. For example, Cinder can be configured to communicate with third-party vendors such as NetApp or Solidfire arrays, or it can be configured to talk to Sheepdog or Ceph, as well as the simplest of services such as LVM. In fact, OpenStack can be configured in such a way that Cinder uses multiple backends so that a user is able to choose the storage applicable to the service they require. This gives great flexibility to both end users and operators as it means workloads can be targeted at specific backends suitable for that workload or storage requirement.
This book briefly covers Ceph as the backend storage engine for Cinder. Ceph is a very popular, highly available open source storage service. Ceph has its own disk requirements to give the best performance. Each of the Ceph storage nodes in the preceding diagram are referred to as Ceph OSDs (Ceph Object Storage Daemons). We recommend starting with 5 of these nodes, although this is not a hard and fast rule. Performance tuning of Ceph is beyond the scope of this book, but at a minimum, we would highly recommend having SSDs for Ceph journaling and either SSD or SAS drives for the OSDs (the physical storage units).
The differences between a Swift node and a Ceph node in this architecture are very minimal. Both require an interface (bonded for resilience) for replication of data in the storage cluster, as well as an interface (bonded for resilience) used for data reads and writes from the client or service consuming the storage.
The primary difference is the recommendation to use SSDs (or NVMe) as the journaling disks.
Load balancing
The end users of the OpenStack environment expect services to be highly available, and OpenStack provides REST API services to all of its features. This makes the REST API services very suitable for placing behind a load balancer. In most deployments, load balancers would usually be highly available hardware appliances such as F5. For the purpose of this book, we will be using HAProxy. The premise behind this is the same though—to ensure that the services are available so your end users can continue working in the event of a failed controller node.
OpenStack-Ansible installation requirements
Operating installing System: Ubuntu 16.04 x86_64
Minimal data center deployment requirements
For a physical installation, the following will be needed:
Controller servers (also known as infrastructure nodes)
At least 64 GB RAM
At least 300 GB disk (RAID)
4 Network Interface Cards (for creating two sets of bonded interfaces; one would be used for infrastructure and all API communication, including client, and the other would be dedicated to OpenStack networking: Neutron)
Shared storage, or object storage service, to provide backend storage for the base OS images used
Compute servers
At least 64 GB RAM
At least 600 GB disk (RAID)
4 Network Interface Cards (for creating two sets of bonded interfaces, used in the same way as the controller servers)
Optional (if using Ceph for Cinder) 5 Ceph Servers (Ceph OSD nodes)
At least 64 GB RAM
2 x SSD (RAID1) 400 GB for journaling
8 x SAS or SSD 300 GB (No RAID) for OSD (size up requirements and adjust accordingly)
4 Network Interface Cards (for creating two sets of bonded interfaces; one for replication and the other for data transfer in and out of Ceph)
Optional (if using Swift) 5 Swift Servers
At least 64 GB RAM
8 x SAS 300 GB (No RAID) (size up requirements and adjust accordingly)
4 Network Interface Cards (for creating two sets of bonded interfaces; one for replication and the other for data transfer in and out of Swift)
Load balancers
2 physical load balancers configured as a pair
Or 2 servers running HAProxy with a Keepalived VIP to provide as the API endpoint IP address:
At least 16 GB RAM
HAProxy + Keepalived
2 Network Interface Cards (bonded)
Note
Tip: Setting up a physical home lab? Ensure you have a managed switch so that interfaces can have VLANs tagged.




