






















































Catalyst Optimizer refresh
As noted in Chapter 1, Understanding Spark, one of the primary reasons the Spark SQL engine is so fast is because of the Catalyst Optimizer. For readers with a database background, this diagram looks similar to the logical/physical planner and cost model/cost-based optimization of a relational database management system (RDBMS):
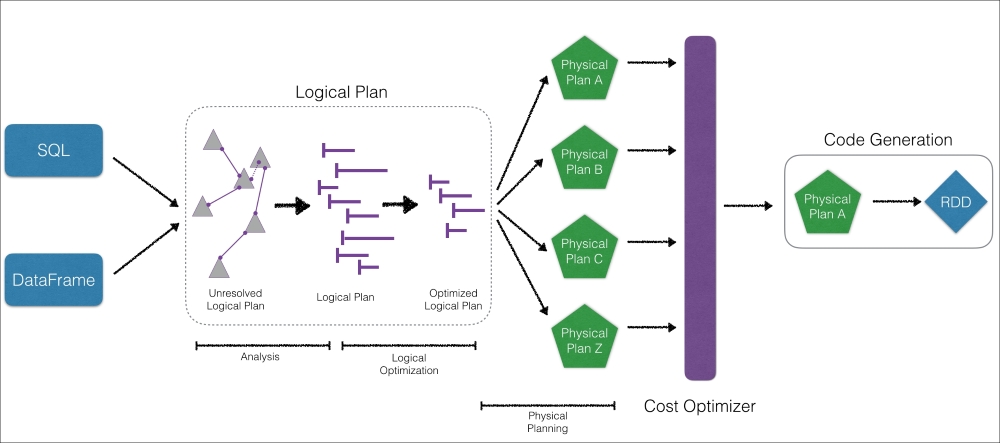
The significance of this is that, as opposed to immediately processing the query, the Spark engine's Catalyst Optimizer compiles and optimizes a logical plan and has a cost optimizer that determines the most efficient physical plan generated.
Note
As noted in earlier chapters, while the Spark SQL Engine has both rules-based and cost-based optimizations that include (but are not limited to) predicate push down and column pruning. Targeted for the Apache Spark 2.2 release, the jira item [SPARK-16026] Cost-based Optimizer Framework at https://issues.apache.org/jira/browse/SPARK-16026 is an umbrella ticket to implement a cost-based optimizer framework...















