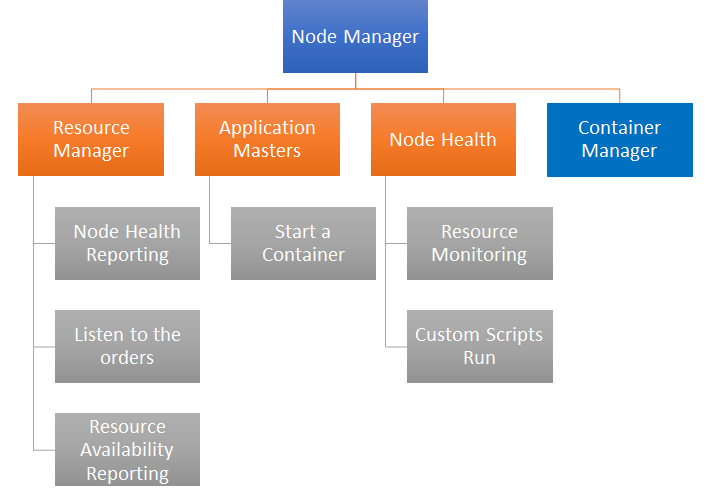
The Apache Hadoop framework works on a cluster of nodes. These nodes can be either virtual machines or physical servers. The Hadoop framework is designed to work seamlessly on all types of these systems. The core of Apache Hadoop is based on Java. Each of the components in the Apache Hadoop framework performs different operations. Apache Hadoop is comprised of the following key modules, which work across HDFS, MapReduce, and YARN to provide a truly distributed experience to the applications. The following diagram shows the overall big picture of the Apache Hadoop cluster with key components:

Let's go over the following key components and understand what role they play in the overall architecture:
- Resource Manager
- Node Manager
- YARN Timeline Service
- NameNode
- DataNode