






















































Process basics
When we refer to a “process” in Linux, we’re referring to the operating system’s internal model of what exactly a running program is. Linux needs a general abstraction that works for all programs, which can encapsulate the things the operating system cares about. A process is that abstraction, and it enables the OS to track some of the important context around programs that are executing; namely:
- Memory usage
- Processor time used
- Other system resource usage (disk access, network usage)
- Communication between processes
- Related processes that a program starts, for example, firing off a shell command
You can get a listing of all system processes (at least the ones your user is allowed to see) by running the ps program with the aux flags:
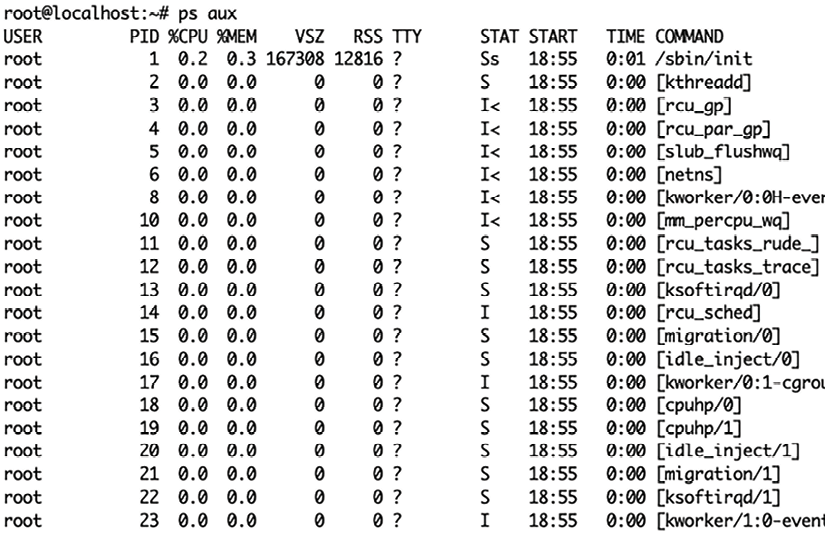
Figure 2.1: List of system processes
We’ll cover the attributes most relevant to your work as a developer in this chapter.
What is a Linux process made of?
From the perspective of the operating system, a “process” is simply a data structure that makes it easy to access information like:
- Process ID (PID in the
psoutput above). PID 1 is the init system – the original parent of all other processes, which bootstraps the system. The kernel starts this as one of the first things it does after starting to execute. When a process is created, it gets the next available process ID, in sequential order. Because it is so important to the normal functioning of the operating system, init cannot be killed, even by the root user. Different Unix operating systems use different init systems – for example, most Linux distributions usesystemd, while macOS useslaunchd, and many other Unixes use SysV. Regardless of the specific implementation, we’ll refer to this process by the name of the role it fills: “init.”Note
In containers, processes are namespaced – in the “real” environment, all container processes might be PID 3210, while that single PID maps to lots of processes (
1..n, wherenis the number of running processes in the container). You can see this from outside but not inside the container.
- Parent Process PID (PPID). Each process is spawned by a parent. If the parent process dies while the child is alive, the child becomes an “orphan.” Orphaned processes are re-parented to init (PID 1).
- Status (STAT in the
psoutput above).man pswill show you an overview:- D – uninterruptible sleep (usually IO)
- I – idle kernel thread
- R – running or runnable (on run queue)
- S – interruptible sleep (waiting for an event to complete)
- T – stopped by job control signal
- t – stopped by debugger during tracing
- X – dead (should never be seen)
- Z – defunct (“zombie”) process, terminated but not reaped by its parent
- Priority status (“niceness” – does this process allow other processes to take priority over it?).
- A process Owner (USER in the
psoutput above); the effective user ID. - Effective Group ID (EGID), which is used.
- An address map of the process’s memory space.
- Resource usage – open files, network ports, and other resources the process is using (VSZ and RSS for memory usage in the
psoutput above).
(Citation: from the Unix and Linux System Administration Handbook, 5th edition, p.91.)
Let’s take a closer look at a few of the process attributes that are most important for developers and occasional troubleshooters to understand.
Process ID (PID)
Each process is uniquely identifiable by its process ID, which is just a unique integer that is assigned to a process when it starts. Much like a relational database with IDs that uniquely identify each row of data, the Linux operating system keeps track of each process by its PID.
A PID is by far the most useful label for you to use when interacting with processes.
Effective User ID (EUID) and Effective Group ID (EGID)
These determine which system user and group your process is running as. Together, user and group permissions determine what a process is allowed to do on the system.
As you’ll see in Chapter 5, Introducing Files, files have user and group ownership set on them, which determines who their permissions apply to. If a file’s ownership and permissions are essentially a lock, then a process with the right user/group permissions is like a key that opens the lock and allows access to the file. We’ll dive deeper into this later, when we talk about permissions.
Environment variables
You’ve probably used environment variables in your applications – they’re a way for the operating system environment that launches your process to pass in data that the process needs. This commonly includes things like configuration directives (LOG_DEBUG=1) and secret keys (AWS_SECRET_KEY), and every programming language has some way to read them out from the context of the program.
For example, this Python script gets the user’s home directory from the HOME environment variable, and then prints it:
import os
home_dir = os.environ['HOME']
print("The home directory for this user is", home_dir)
In my case, running this program in the python3 REPL on a Linux machine results in the following output:
The home directory for this user is /home/dcohen
Working directory
A process has a “current working directory,” just like your shell (which is just a process, anyway). Typing pwd in your shell prints its current working directory, and every process has a working directory. The working directory for a process can change, so don’t rely on it too much.
This concludes our overview of the process attributes that you should know about. In the next section, we’ll step away from theory and look at some commands you can use to start working with processes right away.


