























































pandas
The pandas Python library provides data structures and methods for manipulating different types of data, such as numerical and temporal data. These operations are easy to use and highly optimized for performance.
Data formats, such as CSV and JSON, and databases can be used to create DataFrames. DataFrames are the internal representations of data and are very similar to tables but are more powerful since they allow you to efficiently apply operations such as multiplications, aggregations, and even joins. Importing and reading both files and in-memory data is abstracted into a user-friendly interface. When it comes to handling missing data, pandas provide built-in solutions to clean up and augment your data, meaning it fills in missing values with reasonable values.
Integrated indexing and label-based slicing in combination with fancy indexing (what we already saw with NumPy) make handling data simple. More complex techniques, such as reshaping, pivoting, and melting data, together with the possibility of easily joining and merging data, provide powerful tooling so that you can handle your data correctly.
If you're working with time-series data, operations such as date range generation, frequency conversion, and moving window statistics can provide an advanced interface for data wrangling.
Note
The installation instructions for pandas can be found here: https://pandas.pydata.org/. The latest version is v0.25.3 (used in this book); however, every v0.25.x should be suitable.
Advantages of pandas over NumPy
The following are some of the advantages of pandas:
- High level of abstraction: pandas have a higher abstraction level than NumPy, which gives it a simpler interface for users to interact with. It abstracts away some of the more complex concepts, such as high-performance matrix multiplications and joining tables, and makes it easier to use and understand.
- Less intuition: Many methods, such as joining, selecting, and loading files, are used without much intuition and without taking away much of the powerful nature of pandas.
- Faster processing: The internal representation of DataFrames allows faster processing for some operations. Of course, this always depends on the data and its structure.
- Easy DataFrame design: DataFrames are designed for operations with and on large datasets.
Disadvantages of pandas
The following are some of the disadvantages of pandas:
- Less applicable: Due to its higher abstraction, it's generally less applicable than NumPy. Especially when used outside of its scope, operations can get complex.
- More disk space: Due to the internal representation of DataFrames and the way pandas trades disk space for a more performant execution, the memory usage of complex operations can spike.
- Performance problems: Especially when doing heavy joins, which is not recommended, memory usage can get critical and might lead to performance problems.
- Hidden complexity: Less experienced users often tend to overuse methods and execute them several times instead of reusing what they've already calculated. This hidden complexity makes users think that the operations themselves are simple, which is not the case.
Note
Always try to think about how to design your workflows instead of excessively using operations.
Now, we will do an exercise to load a dataset and calculate the mean using pandas.
Exercise 1.04 Loading a Sample Dataset and Calculating the Mean using Pandas
In this exercise, we will be loading the world_population.csv dataset and calculating the mean of some rows and columns. Our dataset holds the yearly population density for every country. Let's use pandas to perform this exercise:
- Create a new Jupyter Notebook and save it as
Exercise1.04.ipynbin theChapter01/Exercise1.04folder. - Import the
pandaslibraries:import pandas as pd
- Use the
read_csvmethod to load the aforementioned dataset. We want to use the first column, containing the country names, as our index. We will use theindex_colparameter for that:dataset = \ pd.read_csv('../../Datasets/world_population.csv', \ index_col=0) - Now, check the data you just imported by simply writing the name of the dataset in the next cell. pandas uses a data structure called DataFrames. Print some of the rows. To avoid filling the screen, use the pandas
head()method:dataset.head()
The output of the preceding code is as follows:
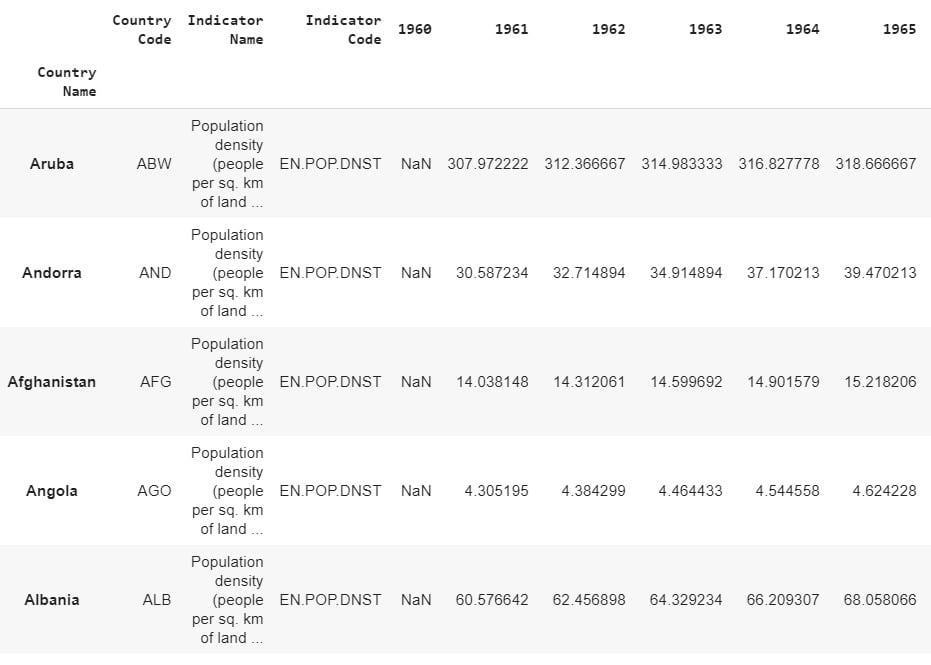
Figure 1.27: The first five rows of our dataset
Both
head()andtail()let you provide a number,n, as a parameter, which describes how many rows should be returned.Note
Simply executing a cell that returns a value such as a DataFrame will use Jupyter formatting, which looks nicer and, in most cases, displays more information than using
print. - Print out the shape of the dataset to get a quick overview using the
dataset.shapecommand. This works the same as it does with NumPy ndarrays. It will give us the output in the form(rows, columns):dataset.shape
The output of the preceding code is as follows:
(264, 60)
- Index the column with the year 1961. pandas DataFrames have built-in functions for calculations, such as the
mean. This means we can simply calldataset.mean()to get the result.The printed output should look as follows:
dataset["1961"].mean()
The output of the preceding code is as follows:
176.91514132840555
- Check the difference in population density over the years by repeating the previous step with the column for the year 2015 (the population more than doubled in the given time range):
# calculating the mean for 2015 column dataset["2015"].mean()
The output of the preceding code is as follows:
368.70660104001837
- To get the mean for every single country (row), we can make use of pandas
axistools. Use themean()method on the dataset onaxis=1, meaning all the rows, and return the first 10 rows using thehead()method:dataset.mean(axis=1).head(10)
The output of the preceding code is as follows:
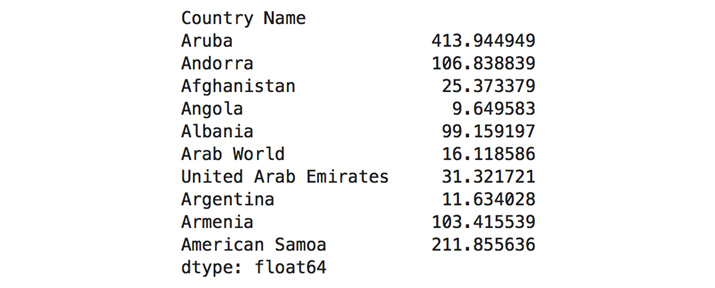
Figure 1.28: Mean of elements in the first 10 countries (rows)
- Get the mean for each column and return the last 10 entries:
dataset.mean(axis=0).tail(10)
The output of the preceding code is as follows:
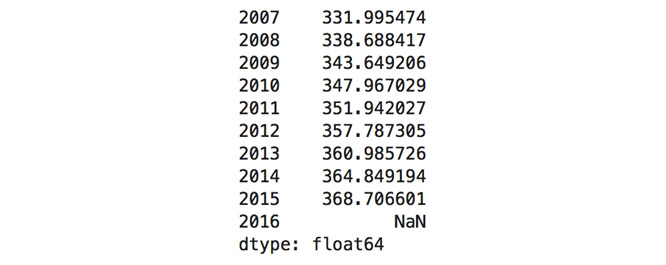
Figure 1.29: Mean of elements for the last 10 years (columns)
- Calculate the mean of the whole DataFrame:
# calculating the mean for the whole matrix dataset.mean()
The output of the preceding code is as follows:

Figure 1.30: Mean of elements for each column
Since pandas DataFrames can have different data types in each column, aggregating this value on the whole dataset out of the box makes no sense. By default, axis=0 will be used, which means that this will give us the same result as the cell prior to this.
Note
To access the source code for this specific section, please refer to https://packt.live/37z3Us1.
You can also run this example online at https://packt.live/2Bb0ks8.
We've now seen that the interface of pandas has some similar methods to NumPy, which makes it really easy to understand. We have now covered the very basics, which will help you solve the first exercise using pandas. In the following exercise, you will consolidate your basic knowledge of pandas and use the methods you just learned to solve several computational tasks.
Exercise 1.05: Using pandas to Compute the Mean, Median, and Variance of a Dataset
In this exercise, we will take the previously learned skills of importing datasets and basic calculations and apply them to solve the tasks of our first exercise using pandas.
Let's use pandas features such as mean, median, and variance to make some calculations on our data:
- Create a new Jupyter Notebook and save it as
Exercise1.05.ipynbin theChapter01/Exercise1.05folder. - Import the necessary libraries:
import pandas as pd
- Use the
read_csvmethod to load the aforementioned dataset and use theindex_colparameter to define the first column as our index:dataset = \ pd.read_csv('../../Datasets/world_population.csv', \ index_col=0) - Print the first two rows of our dataset:
dataset[0:2]
The output of the preceding code is as follows:
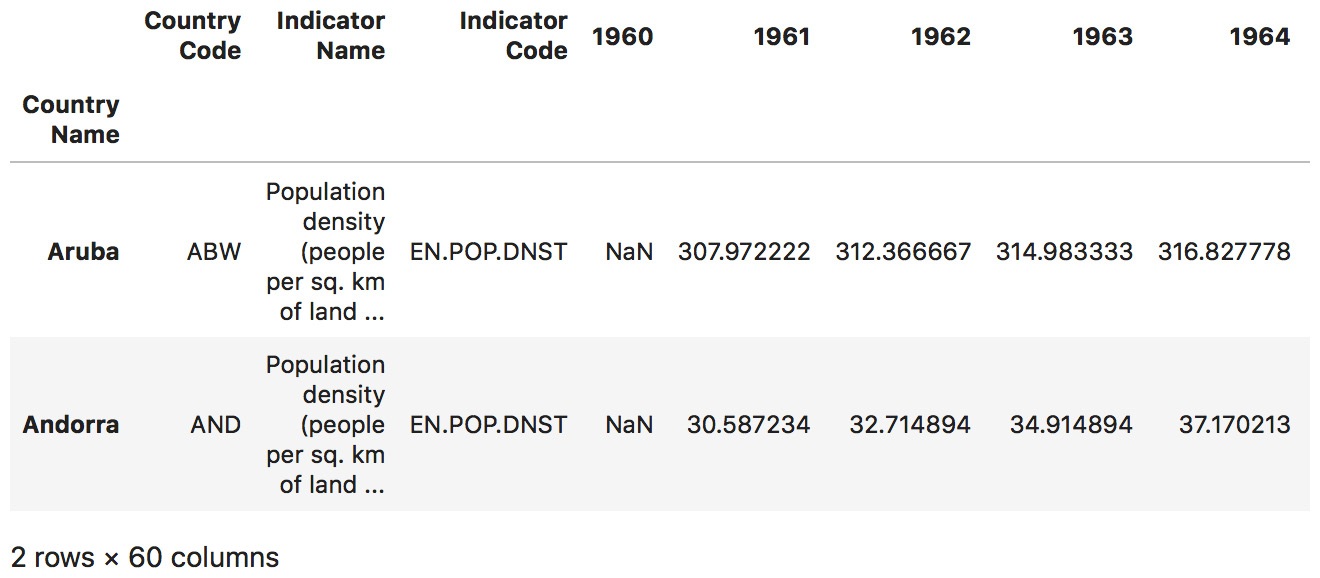
Figure 1.31: The first two rows, printed
- Now, index the third row by using
dataset.iloc[[2]]. Use theaxisparameter to get the mean of the country rather than the yearly column:dataset.iloc[[2]].mean(axis=1)
The output of the preceding code is as follows:

Figure 1.32: Calculating the mean of the third row
- Index the last element of the DataFrame using
-1as the index for theiloc()method:dataset.iloc[[-1]].mean(axis=1)
The output of the preceding code is as follows:

Figure 1.33: Calculating the mean of the last row
- Calculate the mean value of the values labeled as Germany using
loc, which works based on the index column:dataset.loc[["Germany"]].mean(axis=1)
The output of the preceding code is as follows:

Figure 1.34: Indexing a country and calculating the mean of Germany
- Calculate the median value of the last row by using reverse indexing and
axis=1to aggregate the values in the row:dataset.iloc[[-1]].median(axis=1)
The output of the preceding code is as follows:

Figure 1.35: Usage of the median method on the last row
- Use reverse indexing to get the last three columns with
dataset[-3:]and calculate the median for each of them:dataset[-3:].median(axis=1)
The output of the preceding code is as follows:

Figure 1.36: Median of the last three columns
- Calculate the median population density values for the first 10 countries of the list using the
headandmedianmethods:dataset.head(10).median(axis=1)
The output of the preceding code is as follows:
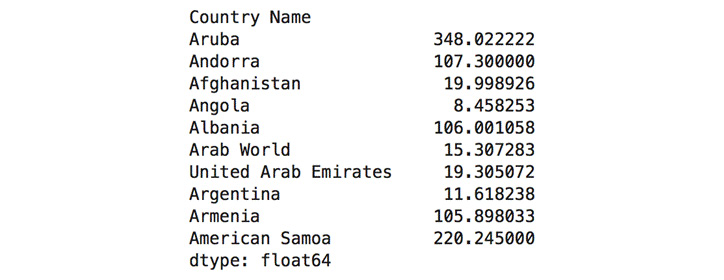
Figure 1.37: Usage of the axis to calculate the median of the first 10 rows
When handling larger datasets, the order in which methods are executed matters. Think about what
head(10)does for a moment. It simply takes your dataset and returns the first 10 rows in it, cutting down your input to themean()method drastically.The last method we'll cover here is the variance. pandas provide a consistent API, which makes it easy to use.
- Calculate the variance of the dataset and return only the last five columns:
dataset.var().tail()
The output of the preceding code is as follows:
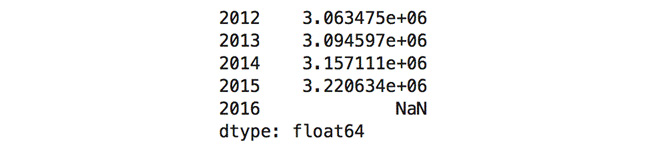
Figure 1.38: Variance of the last five columns
- Calculate the mean for the year 2015 using both NumPy and pandas separately:
# NumPy pandas interoperability import numpy as np print("pandas", dataset["2015"].mean()) print("numpy", np.mean(dataset["2015"]))The output of the preceding code is as follows:

Figure 1.39: Using NumPy's mean method with a pandas DataFrame
Note
To access the source code for this specific section, please refer to https://packt.live/2N7E2Kh.
You can also run this example online at https://packt.live/2Y3B2Fa.
This exercise of how to use NumPy's mean method with a pandas DataFrame shows that, in some cases, NumPy has better functionality. However, the DataFrame format of pandas is more applicable, so we combine both libraries to get the best out of both.
You've completed your first exercise with pandas, which showed you some of the similarities, and also differences when working with NumPy and pandas. In the following exercise, this knowledge will be consolidated. You'll also be introduced to more complex features and methods of pandas.
Basic Operations of pandas
In this section, we will learn about the basic pandas operations, such as indexing, slicing, and iterating, and implement them with an exercise.
Indexing
Indexing with pandas is a bit more complex than with NumPy. We can only access columns with a single bracket. To use the indices of the rows to access them, we need the iloc method. If we want to access them with index_col (which was set in the read_csv call), we need to use the loc method:
# index the 2000 col dataset["2000"] # index the last row dataset.iloc[-1] # index the row with index Germany dataset.loc["Germany"] # index row Germany and column 2015 dataset[["2015"]].loc[["Germany"]]
Slicing
Slicing with pandas is even more powerful. We can use the default slicing syntax we've already seen with NumPy or use multi-selection. If we want to slice different rows or columns by name, we can simply pass a list into the brackets:
# slice of the first 10 rows dataset.iloc[0:10] # slice of rows Germany and India dataset.loc[["Germany", "India"]] # subset of Germany and India with years 1970/90 dataset.loc[["Germany", "India"]][["1970", "1990"]]
Iterating
Iterating DataFrames is also possible. Considering that they can have several dimensions and dtypes, the indexing is very high level and iterating over each row has to be done separately:
# iterating the whole dataset for index, row in dataset.iterrows(): print(index, row)
Series
A pandas Series is a one-dimensional labeled array that is capable of holding any type of data. We can create a Series by loading datasets from a .csv file, Excel spreadsheet, or SQL database. There are many different ways to create them, such as the following:
- NumPy arrays:
# import pandas import pandas as pd # import numpy import numpy as np # creating a numpy array numarr = np.array(['p','y','t','h','o','n']) ser = pd.Series(numarr) print(ser)
- pandas lists:
# import pandas import pandas as pd # creating a pandas list plist = ['p','y','t','h','o','n'] ser = pd.Series(plist) print(ser)
Now, we will use basic pandas operations in an exercise.
Exercise 1.06: Indexing, Slicing, and Iterating Using pandas
In this exercise, we will use the previously discussed pandas features to index, slice, and iterate DataFrames using pandas Series. To derive some insights from our dataset, we need to be able to explicitly index, slice, and iterate our data. For example, we can compare several countries in terms of population density growth.
Let's use the indexing, slicing, and iterating operations to display the population density of Germany, Singapore, United States, and India for years 1970, 1990, and 2010.
Indexing
- Create a new Jupyter Notebook and save it as
Exercise1.06.ipynbin theChapter01/Exercise1.06folder. - Import the necessary libraries:
import pandas as pd
- Use the
read_csvmethod to load theworld_population.csvdataset and use the first column, (containing the country names) as our index using theindex_colparameter:dataset = \ pd.read_csv('../../Datasets/world_population.csv', \ index_col=0) - Index the row with the
index_col"United States"using thelocmethod:dataset.loc[["United States"]].head()
The output of the preceding code is as follows:
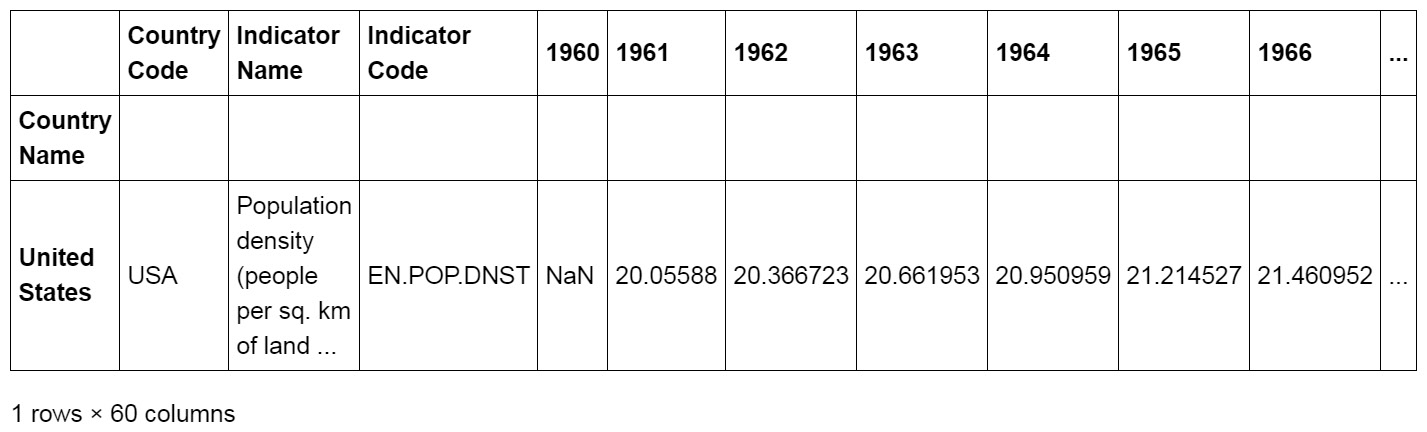
Figure 1.40: A few columns from the output showing indexing United States with the loc method
- Use reverse indexing in pandas to index the second to last row using the
ilocmethod:dataset.iloc[[-2]]
The output of the preceding code is as follows:
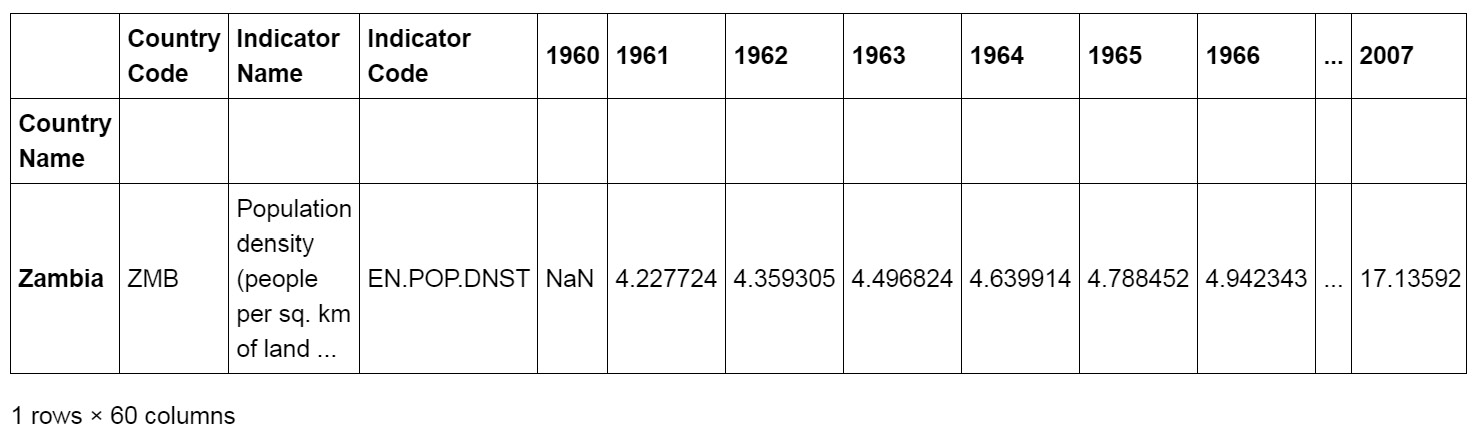
Figure 1.41: Indexing the second to last row
- Columns are indexed using their header. This is the first line of the CSV file. Index the column with the header of
2000as a Series:dataset["2000"].head()
The output of the preceding code is as follows:

Figure 1.42: Indexing all 2000 columns
Remember, the
head()method simply returns the first five rows. - First, get the data for the year 2000 as a DataFrame and then select India using the
loc()method using chaining:dataset[["2000"]].loc[["India"]]
The output of the preceding code is as follows:

Figure 1.43: Getting the population density of India in 2000
Since the double brackets notation returns a DataFrame once again, we can chain method calls to get distinct elements.
- Use the single brackets notation to get the distinct value for the population density of India in 2000:
dataset["2000"].loc["India"]
If we want to only retrieve a Series object, we must replace the double brackets with single ones. The output of the preceding code is as follows:
354.326858357522
Slicing
- Create a slice with the rows 2 to 5 using the
iloc()method again:# slicing countries of rows 2 to 5 dataset.iloc[1:5]
The output of the preceding code is as follows:
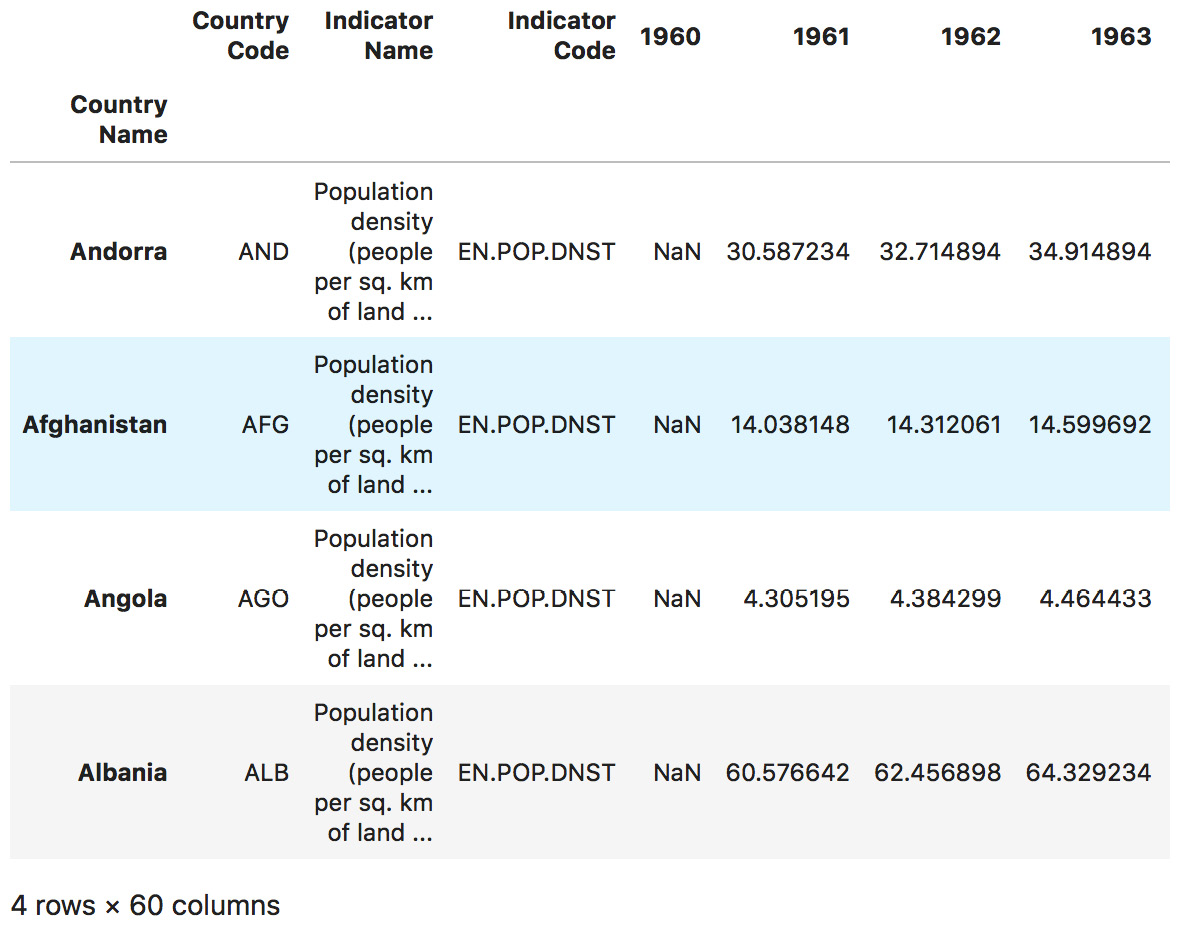
Figure 1.44: The countries in rows 2 to 5
- Use the
loc()method to access several rows in the DataFrame and use the nested brackets to provide a list of elements. Slice the dataset to get the rows for Germany, Singapore, United States, and India:dataset.loc[["Germany", "Singapore", "United States", "India"]]
The output of the preceding code is as follows:
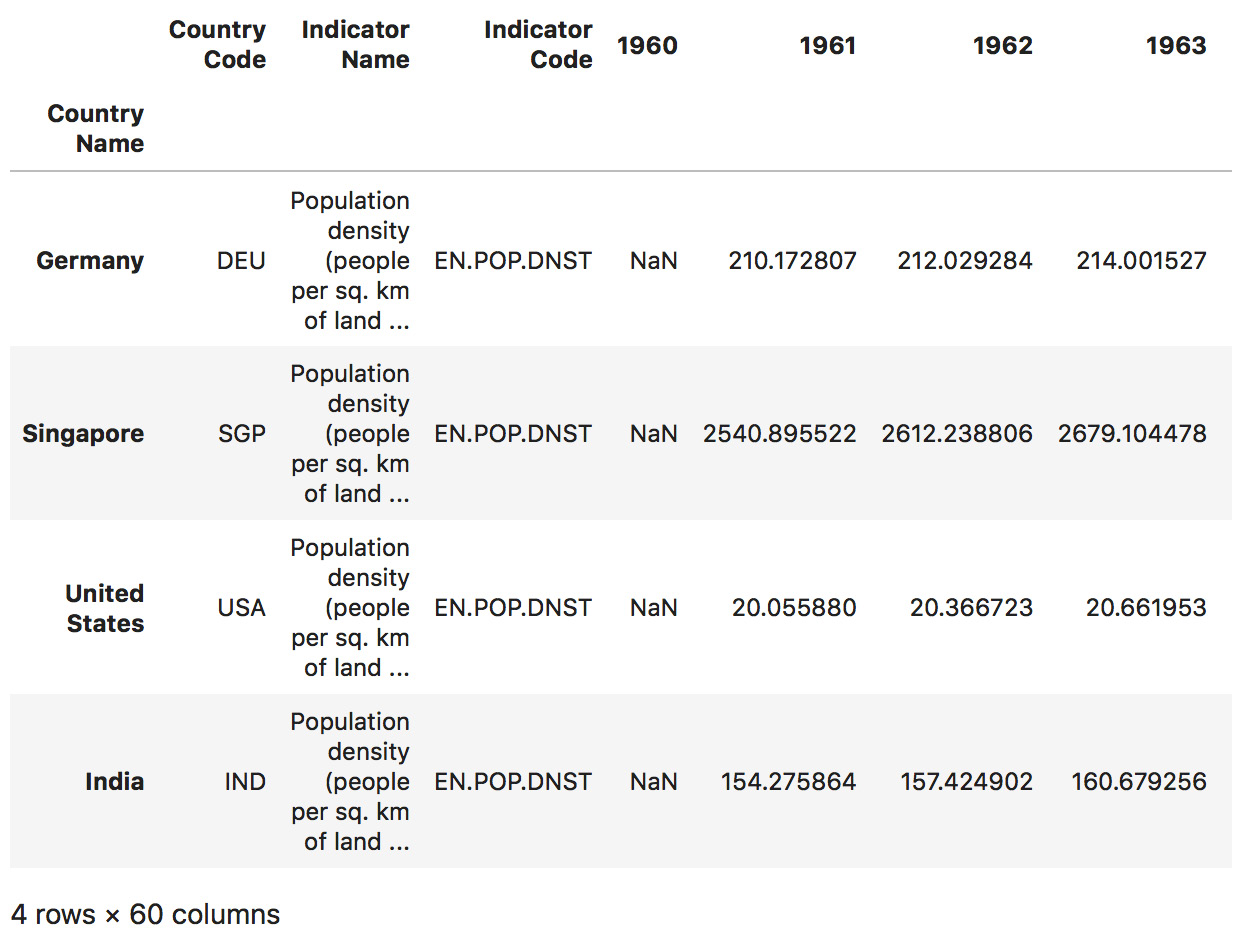
Figure 1.45: Slicing Germany, Singapore, United States, and India
- Use chaining to get the rows for Germany, Singapore, United States, and India and return only the values for the years 1970, 1990, and 2010. Since the double bracket queries return new DataFrames, we can chain methods and therefore access distinct subframes of our data:
country_list = ["Germany", "Singapore", "United States", "India"] dataset.loc[country_list][["1970", "1990", "2010"]]
The output of the preceding code is as follows:
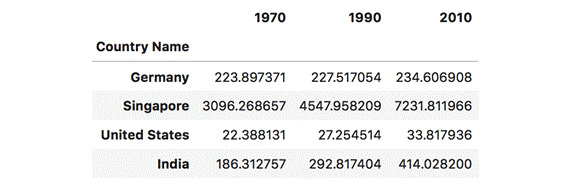
Figure 1.46: Slices some of the countries and their population density for 1970, 1990, and 2010
Iterating
- Iterate our dataset and print out the countries up until
Angolausing theiterrows()method. The index will be the name of our row, and the row will hold all the columns:for index, row in dataset.iterrows(): # only printing the rows until Angola if index == 'Angola': break print(index, '\n', \ row[["Country Code", "1970", "1990", "2010"]], '\n')
The output of the preceding code is as follows:
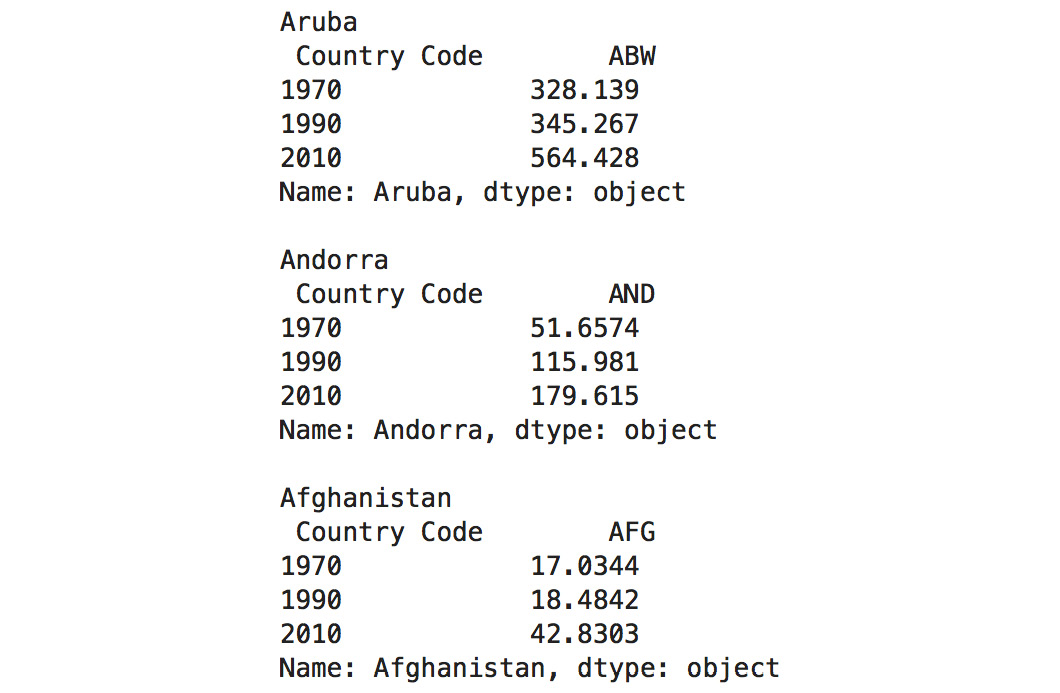
Figure 1.47: Iterating all countries until Angola
Note
To access the source code for this specific section, please refer to https://packt.live/2YKqHNM.
You can also run this example online at https://packt.live/2YD56Xo.
We've already covered most of the underlying data wrangling methods using pandas. In the next exercise, we'll take a look at more advanced features such as filtering, sorting, and reshaping to prepare you for the next chapter.
Advanced pandas Operations
In this section, we will learn about some advanced pandas operations such as filtering, sorting, and reshaping and implement them in an exercise.
Filtering
Filtering in pandas has a higher-level interface than NumPy. You can still use the simple brackets-based conditional filtering. However, you're also able to use more complex queries, for example, filter rows based on labels using likeness, which allows us to search for a substring using the like argument and even full regular expressions using regex:
# only column 1994 dataset.filter(items=["1990"]) # countries population density < 10 in 1999 dataset[(dataset["1990"] < 10)] # years containing an 8 dataset.filter(like="8", axis=1) # countries ending with a dataset.filter(regex="a$", axis=0)
Sorting
Sorting each row or column based on a given row or column will help you analyze your data better and find the ranking of a given dataset. With pandas, we are able to do this pretty easily. Sorting in ascending and descending order can be done using the parameter known as ascending. The default sorting order is ascending. Of course, you can do more complex sorting by providing more than one value in the by = [ ] list. Those will then be used to sort values for which the first value is the same:
# values sorted by 1999 dataset.sort_values(by=["1999"]) # values sorted by 1999 descending dataset.sort_values(by=["1994"], ascending=False)
Reshaping
Reshaping can be crucial for easier visualization and algorithms. However, depending on your data, this can get really complex:
dataset.pivot(index=["1999"] * len(dataset), \ columns="Country Code", values="1999")
Now, we will use advanced pandas operations to perform an exercise.
Exercise 1.07: Filtering, Sorting, and Reshaping
This exercise provides some more complex tasks and also combines most of the methods we learned about previously as a recap. After this exercise, you should be able to read the most basic pandas code and understand its logic.
Let's use pandas to filter, sort, and reshape our data.
Filtering
- Create a new Jupyter Notebook and save it as
Exercise1.07.ipynbin theChapter01/Exercise1.07folder. - Import the necessary libraries:
# importing the necessary dependencies import pandas as pd
- Use the
read_csvmethod to load the dataset, again defining our first column as an index column:# loading the dataset dataset = \ pd.read_csv('../../Datasets/world_population.csv', \ index_col=0) - Use
filterinstead of using the bracket syntax to filter for specific items. Filter the dataset for columns 1961, 2000, and 2015 using the items parameter:# filtering columns 1961, 2000, and 2015 dataset.filter(items=["1961", "2000", "2015"]).head()
The output of the preceding code is as follows:
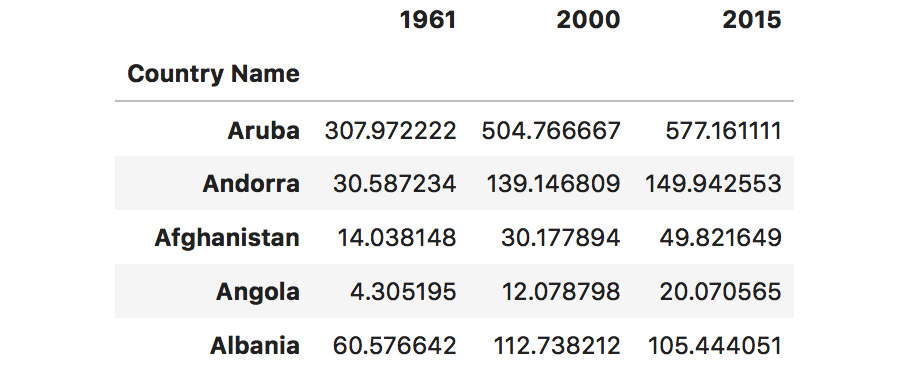
Figure 1.48: Filtering data for 1961, 2000, and 2015
- Use conditions to get all the countries that had a higher population density than
500in2000. Simply pass this condition in brackets:""" filtering countries that had a greater population density than 500 in 2000 """ dataset[(dataset["2000"] > 500)][["2000"]]
The output of the preceding code is as follows:
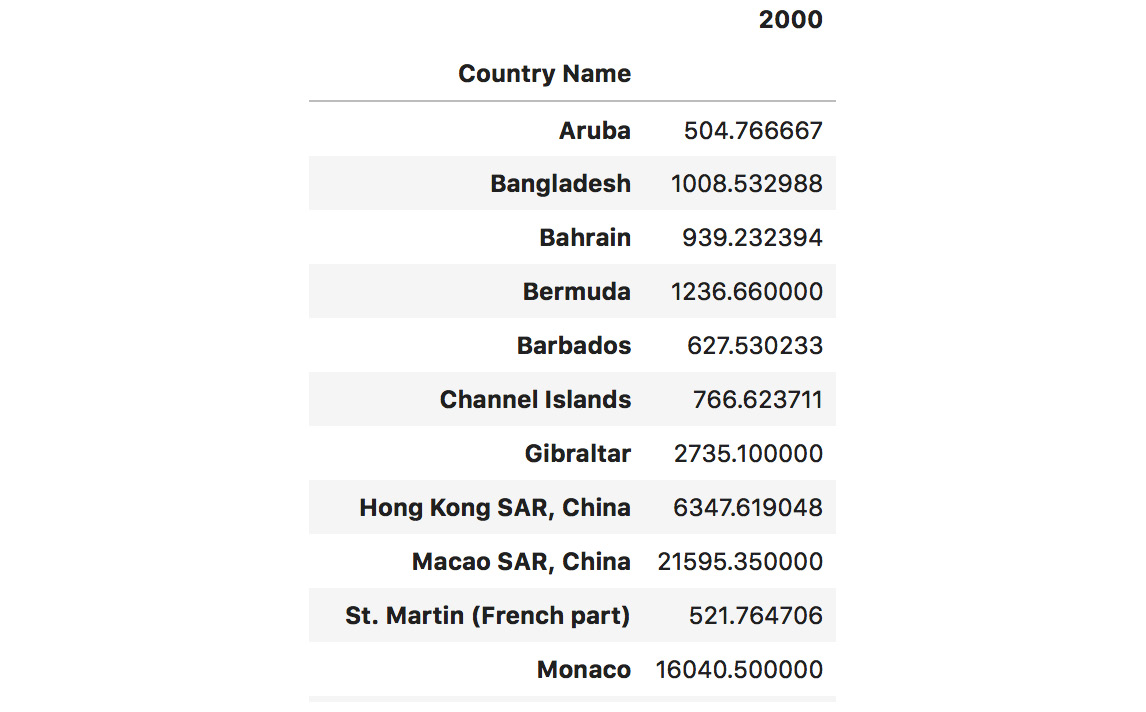
Figure 1.49: Filtering out values that are greater than 500 in the 2000 column
- Search for arbitrary columns or rows (depending on the index given) that match a certain
regex. Get all the columns that start with 2 by passing^2(meaning that it starts at2):dataset.filter(regex="^2", axis=1).head()
The output of the preceding code is as follows:
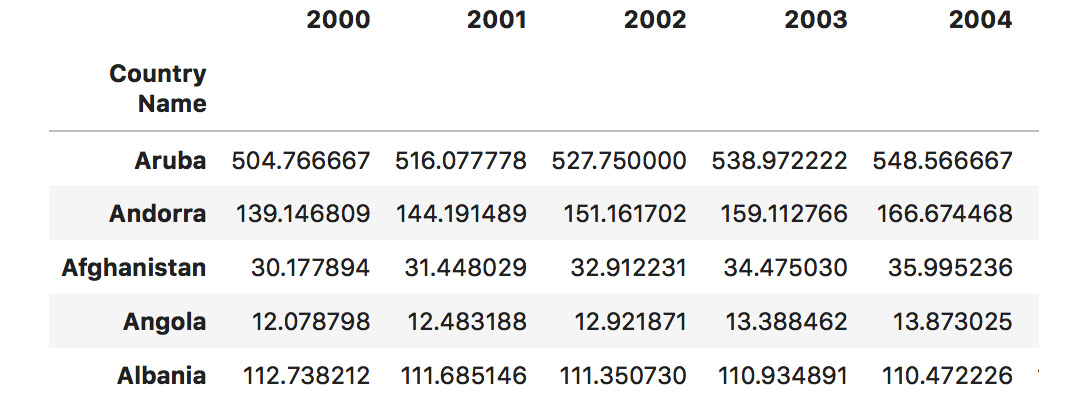
Figure 1.50: Retrieving all columns starting with 2
- Filter the rows instead of the columns by passing
axis=0. This will be helpful for situations when we want to filter all the rows that start withA:dataset.filter(regex="^A", axis=0).head()
The output of the preceding code is as follows:
Figure 1.51: Retrieving the rows that start with A
- Use the
likequery to find only the countries that contain the wordland, such as Switzerland:dataset.filter(like="land", axis=0).head()
The output of the preceding code is as follows:
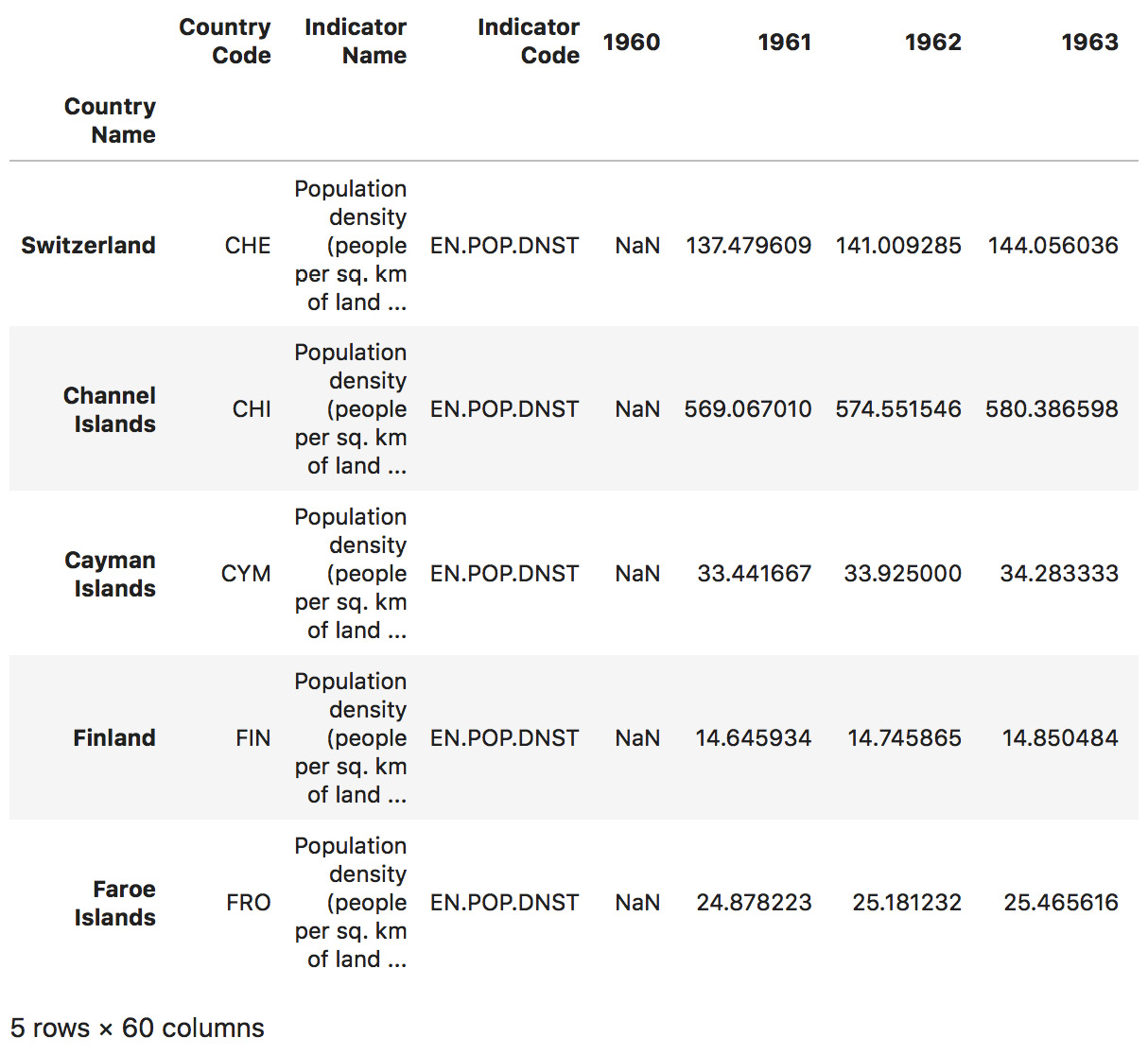
Figure 1.52: Retrieving all countries containing the word "land"
Sorting
- Use the
sort_valuesorsort_indexmethod to get the countries with the lowest population density for the year 1961:dataset.sort_values(by=["1961"])[["1961"]].head(10)
The output of the preceding code is as follows:
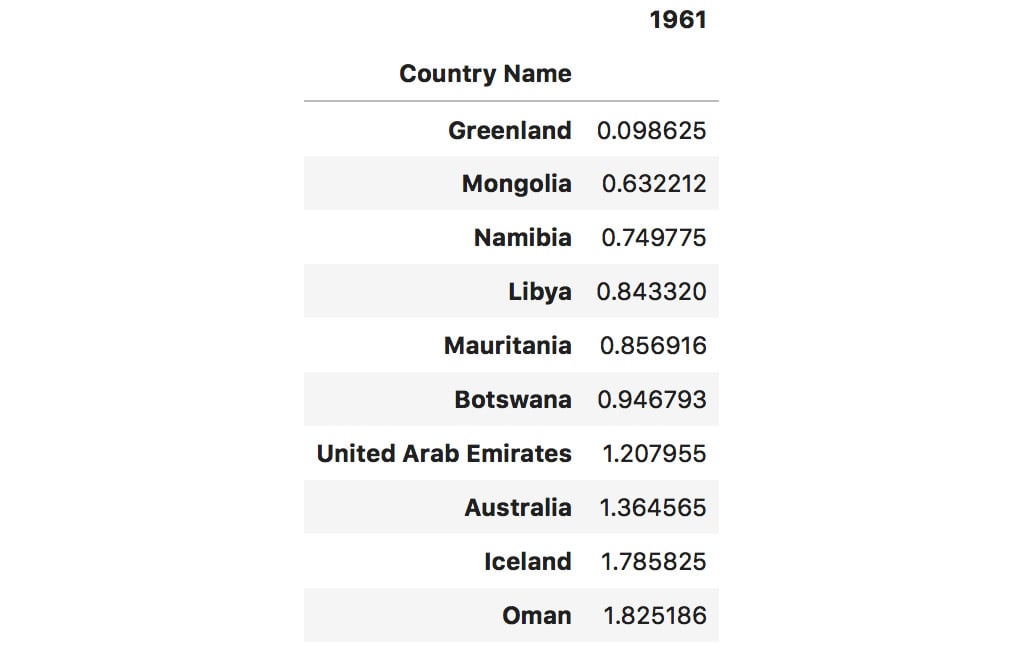
Figure 1.53: Sorting by the values for the year 1961
- Just for comparison, carry out sorting for
2015:dataset.sort_values(by=["2015"])[["2015"]].head(10)
The output of the preceding code is as follows:
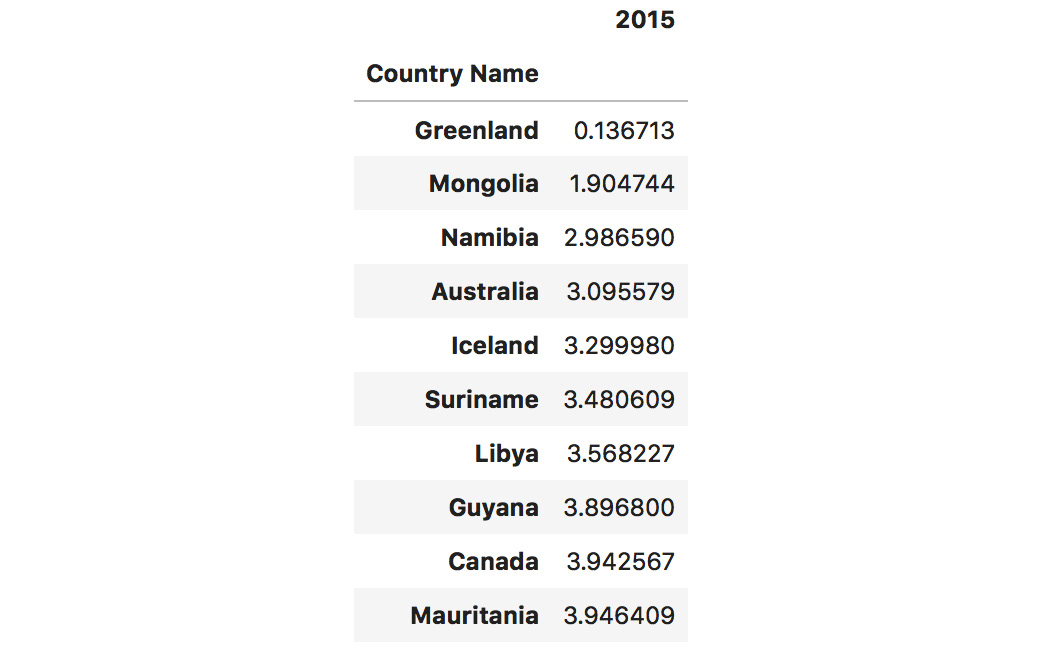
Figure 1.54: Sorting based on the values of 2015
We can see that the order of the countries with the lowest population density has changed a bit, but that the first three entries remain unchanged.
- Sort column 2015 in
descendingorder to show the biggest values first:dataset.sort_values(by=["2015"], \ ascending=False)[["2015"]].head(10)
The output of the preceding code is as follows:
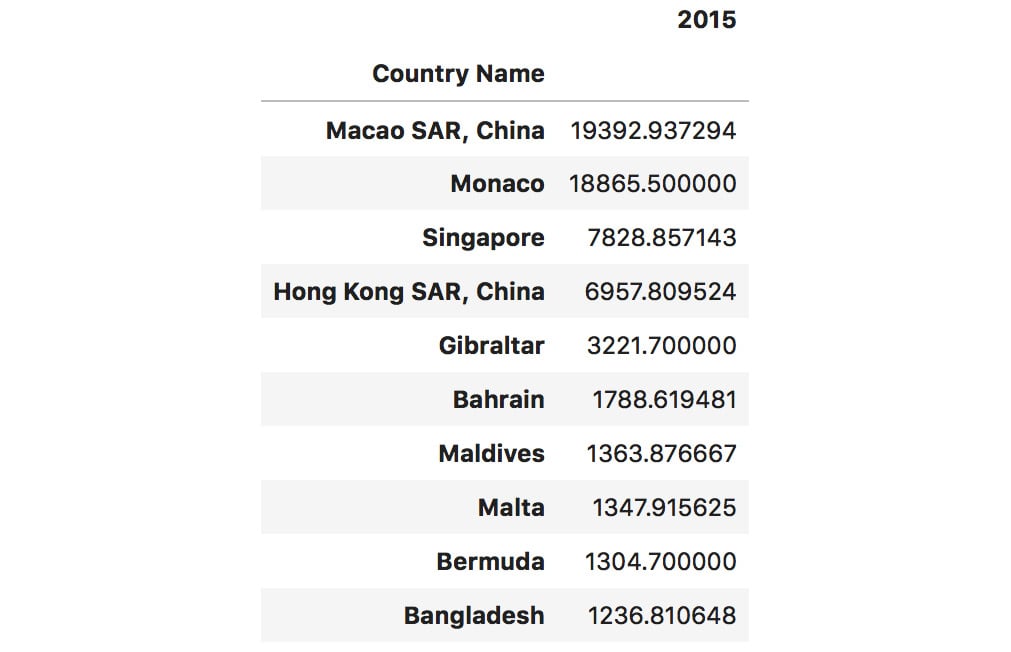
Figure 1.55: Sorting in descending order
Reshaping
- Get a DataFrame where the columns are
country codesand the only row is the year2015. Since we only have one2015label, we need to duplicate it as many times as our dataset's length:# reshaping to 2015 as row and country codes as columns dataset_2015 = dataset[["Country Code", "2015"]] dataset_2015.pivot(index=["2015"] * len(dataset_2015), \ columns="Country Code", values="2015")
The output of the preceding code is as follows:

Figure 1.56: Reshaping the dataset into a single row for the values of 2015
Note
To access the source code for this specific section, please refer to https://packt.live/2N0xHQZ.
You can also run this example online at https://packt.live/30Jeziw.
You now know the basic functionality of pandas and have already applied it to a real-world dataset. In the final activity for this chapter, we will try to analyze a forest fire dataset to get a feeling for mean forest fire sizes and whether the temperature of each month is proportional to the number of fires.
Activity 1.02: Forest Fire Size and Temperature Analysis
In this activity, we will use pandas features to derive some insights from a forest fire dataset. We will get the mean size of forest fires, what the largest recorded fire in our dataset is, and whether the amount of forest fires grows proportionally to the temperature in each month.
Our forest fires dataset has the following structure:
X: X-axis spatial coordinate within the Montesinho park map: 1 to 9Y: Y-axis spatial coordinate within the Montesinho park map: 2 to 9month: Month of the year: 'jan' to 'dec'day: Day of the week: 'mon' to 'sun'FFMC: FFMC index from the FWI system: 18.7 to 96.20DMC: DMC index from the FWI system: 1.1 to 291.3DC: DC index from the FWI system: 7.9 to 860.6ISI: ISI index from the FWI system: 0.0 to 56.10temp: Temperature in degrees Celsius: 2.2 to 33.30RH: Relative humidity in %: 15.0 to 100wind: Wind speed in km/h: 0.40 to 9.40rain: Outside rain in mm/m2: 0.0 to 6.4area: The burned area of the forest (in ha): 0.00 to 1090.84Note
We will only be using the
month,temp, andareacolumns in this activity.
The following are the steps for this activity:
- Open the
Activity1.02.ipynbJupyter Notebook from theChapter01folder to complete this activity. Importpandasusing thepdalias. - Load the
forestfires.csvdataset using pandas. - Print the first two rows of the dataset to get a feeling for its structure.
Derive insights from the sizes of forest fires
- Filter the dataset so that it only contains entries that have an area larger than 0.
- Get the mean, min, max, and std of the area column and see what information this gives you.
- Sort the filtered dataset using the area column and print the last 20 entries using the
tailmethod to see how many huge values it holds. - Then, get the median of the area column and visually compare it to the mean value.
Finding the month with the most forest fires
- Get a list of unique values from the month column of the dataset.
- Get the number of entries for the month of March using the
shapemember of our DataFrame. - Now, iterate over all the months, filter our dataset for the rows containing the given month, and calculate the mean temperature. Print a statement with the number of fires, the mean temperature, and the month.
Note
The solution for this activity can be found via this link.
You have now completed this topic all about pandas, which concludes this chapter. We have learned about the essential tools that help you wrangle and work with data. pandas is an incredibly powerful and widely used tool for wrangling and understanding data.
















