






















































CommonJS modules
CommonJS is the first module system originally built into Node.js. Node.js' CommonJS implementation respects the CommonJS specification, with the addition of some custom extensions.
Let's summarize two of the main concepts of the CommonJS specification:
requireis a function that allows you to import a module from the local filesystemexportsandmodule.exportsare special variables that can be used to export public functionality from the current module
This information is sufficient for now; we will learn more details and some of the nuances of the CommonJS specification in the next few sections.
A homemade module loader
To understand how CommonJS works in Node.js, let's build a similar system from scratch. The code that follows creates a function that mimics a subset of the functionality of the original require() function of Node.js.
Let's start by creating a function that loads the content of a module, wraps it into a private scope, and evaluates it:
function loadModule (filename, module, require) {
const wrappedSrc =
`(function (module, exports, require) {
${fs.readFileSync(filename, 'utf8')}
})(module, module.exports, require)`
eval(wrappedSrc)
}
The source code of a module is essentially wrapped into a function, as it was for the revealing module pattern. The difference here is that we pass a list of variables to the module, in particular, module, exports, and require. Make a note of how the exports argument of the wrapping function is initialized with the content of module.exports, as we will talk about this later.
Another important detail to mention is that we are using readFileSync to read the module's content. While it is generally not recommended to use the synchronous version of the filesystem APIs, here it makes sense to do so. The reason for that is that loading modules in CommonJS are deliberately synchronous operations. This approach makes sure that, if we are importing multiple modules, they (and their dependencies) are loaded in the right order. We will talk more about this aspect later in the chapter.
Bear in mind that this is only an example, and you will rarely need to evaluate some source code in a real application. Features such as eval() or the functions of the vm module (nodejsdp.link/vm) can be easily used in the wrong way or with the wrong input, thus opening a system to code injection attacks. They should always be used with extreme care or avoided altogether.
Let's now implement the require() function:
function require (moduleName) {
console.log(`Require invoked for module: ${moduleName}`)
const id = require.resolve(moduleName) // (1)
if (require.cache[id]) { // (2)
return require.cache[id].exports
}
// module metadata
const module = { // (3)
exports: {},
id
}
// Update the cache
require.cache[id] = module // (4)
// load the module
loadModule(id, module, require) // (5)
// return exported variables
return module.exports // (6)
}
require.cache = {}
require.resolve = (moduleName) => {
/* resolve a full module id from the moduleName */
}
The previous function simulates the behavior of the original require() function of Node.js, which is used to load a module. Of course, this is just for educational purposes and does not accurately or completely reflect the internal behavior of the real require() function, but it's great to understand the internals of the Node.js module system, including how a module is defined and loaded.
What our homemade module system does is explained as follows:
- A module name is accepted as input, and the very first thing that we do is resolve the full path of the module, which we call
id. This task is delegated torequire.resolve(), which implements a specific resolving algorithm (we will talk about it later). - If the module has already been loaded in the past, it should be available in the cache. If this is the case, we just return it immediately.
- If the module has never been loaded before, we set up the environment for the first load. In particular, we create a
moduleobject that contains anexportsproperty initialized with an empty object literal. This object will be populated by the code of the module to export its public API. - After the first load, the
moduleobject is cached. - The module source code is read from its file and the code is evaluated, as we saw before. We provide the module with the
moduleobject that we just created, and a reference to therequire()function. The module exports its public API by manipulating or replacing themodule.exportsobject. - Finally, the content of
module.exports, which represents the public API of the module, is returned to the caller.
As we can see, there is nothing magical behind the workings of the Node.js module system. The trick is all in the wrapper we create around a module's source code and the artificial environment in which we run it.
Defining a module
By looking at how our custom require() function works, we should now be able to understand how to define a module. The following code gives us an example:
// load another dependency
const dependency = require('./anotherModule')
// a private function
function log() {
console.log(`Well done ${dependency.username}`)
}
// the API to be exported for public use
module.exports.run = () => {
log()
}
The essential concept to remember is that everything inside a module is private unless it's assigned to the module.exports variable. The content of this variable is then cached and returned when the module is loaded using require().
module.exports versus exports
For many developers who are not yet familiar with Node.js, a common source of confusion is the difference between using exports and module.exports to expose a public API. The code of our custom require() function should again clear any doubt. The exports variable is just a reference to the initial value of module.exports. We have seen that such a value is essentially a simple object literal created before the module is loaded.
This means that we can only attach new properties to the object referenced by the exports variable, as shown in the following code:
exports.hello = () => {
console.log('Hello')
}
Reassigning the exports variable doesn't have any effect, because it doesn't change the content of module.exports. It will only reassign the variable itself. The following code is therefore wrong:
exports = () => {
console.log('Hello')
}
If we want to export something other than an object literal, such as a function, an instance, or even a string, we have to reassign module.exports as follows:
module.exports = () => {
console.log('Hello')
}
The require function is synchronous
A very important detail that we should take into account is that our homemade require() function is synchronous. In fact, it returns the module contents using a simple direct style, and no callback is required. This is true for the original Node.js require() function too. As a consequence, any assignment to module.exports must be synchronous as well. For example, the following code is incorrect and it will cause trouble:
setTimeout(() => {
module.exports = function() {...}
}, 100)
The synchronous nature of require() has important repercussions on the way we define modules, as it limits us to mostly using synchronous code during the definition of a module. This is one of the most important reasons why the core Node.js libraries offer synchronous APIs as an alternative to most of the asynchronous ones.
If we need some asynchronous initialization steps for a module, we can always define and export an uninitialized module that is initialized asynchronously at a later time. The problem with this approach, though, is that loading such a module using require() does not guarantee that it's ready to be used. In Chapter 11, Advanced Recipes, we will analyze this problem in detail and present some patterns to solve this issue elegantly.
For the sake of curiosity, you might want to know that in its early days, Node.js used to have an asynchronous version of require(), but it was soon removed because it was overcomplicating a functionality that was actually only meant to be used at initialization time and where asynchronous I/O brings more complexities than advantages.
The resolving algorithm
The term dependency hell describes a situation whereby two or more dependencies of a program in turn depend on a shared dependency, but require different incompatible versions. Node.js solves this problem elegantly by loading a different version of a module depending on where the module is loaded from. All the merits of this feature go to the way Node.js package managers (such as npm or yarn) organize the dependencies of the application, and also to the resolving algorithm used in the require() function.
Let's now give a quick overview of this algorithm. As we saw, the resolve() function takes a module name (which we will call moduleName) as input and it returns the full path of the module. This path is then used to load its code and also to identify the module uniquely. The resolving algorithm can be divided into the following three major branches:
- File modules: If
moduleNamestarts with/, it is already considered an absolute path to the module and it's returned as it is. If it starts with./, thenmoduleNameis considered a relative path, which is calculated starting from the directory of the requiring module. - Core modules: If
moduleNameis not prefixed with/or./, the algorithm will first try to search within the core Node.js modules. - Package modules: If no core module is found matching
moduleName, then the search continues by looking for a matching module in the firstnode_modulesdirectory that is found navigating up in the directory structure starting from the requiring module. The algorithm continues to search for a match by looking into the nextnode_modulesdirectory up in the directory tree, until it reaches the root of the filesystem.
For file and package modules, both files and directories can match moduleName. In particular, the algorithm will try to match the following:
<moduleName>.js<moduleName>/index.js- The directory/file specified in the
mainproperty of<moduleName>/package.json
The complete, formal documentation of the resolving algorithm can be found at nodejsdp.link/resolve.
The node_modules directory is actually where the package managers install the dependencies of each package. This means that, based on the algorithm we just described, each package can have its own private dependencies. For example, consider the following directory structure:
myApp
├── foo.js
└── node_modules
├── depA
│ └── index.js
├── depB
│ ├── bar.js
│ └── node_modules
│ └── depA
│ └── index.js
└── depC
├── foobar.js
└── node_modules
└── depA
└── index.js
In the previous example, myApp, depB, and depC all depend on depA. However, they all have their own private version of the dependency! Following the rules of the resolving algorithm, using require('depA') will load a different file depending on the module that requires it, for example:
- Calling
require('depA')from/myApp/foo.jswill load/myApp/node_modules/depA/index.js - Calling
require('depA')from/myApp/node_modules/depB/bar.jswill load/myApp/node_modules/depB/node_modules/depA/index.js - Calling
require('depA')from/myApp/node_modules/depC/foobar.jswill load/myApp/node_modules/depC/node_modules/depA/index.js
The resolving algorithm is the core part behind the robustness of the Node.js dependency management, and it makes it possible to have hundreds or even thousands of packages in an application without having collisions or problems of version compatibility.
The resolving algorithm is applied transparently for us when we invoke require(). However, if needed, it can still be used directly by any module by simply invoking require.resolve().
The module cache
Each module is only loaded and evaluated the first time it is required, since any subsequent call of require() will simply return the cached version. This should be clear by looking at the code of our homemade require() function. Caching is crucial for performance, but it also has some important functional implications:
- It makes it possible to have cycles within module dependencies
- It guarantees, to some extent, that the same instance is always returned when requiring the same module from within a given package
The module cache is exposed via the require.cache variable, so it is possible to directly access it if needed. A common use case is to invalidate any cached module by deleting the relative key in the require.cache variable, a practice that can be useful during testing but very dangerous if applied in normal circumstances.
Circular dependencies
Many consider circular dependencies an intrinsic design issue, but it is something that might actually happen in a real project, so it's useful for us to know at least how this works with CommonJS. If we look again at our homemade require() function, we immediately get a glimpse of how this might work and what its caveats are.
But let's walk together through an example to see how CommonJS behaves when dealing with circular dependencies. Let's suppose we have the scenario represented in Figure 2.1:
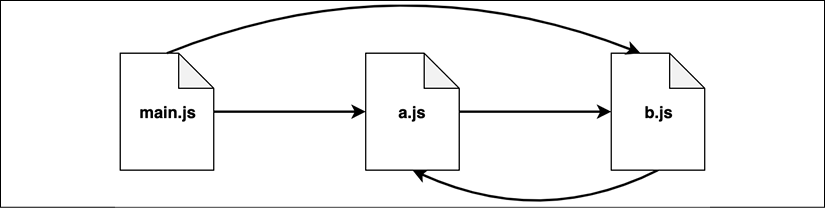
Figure 2.1: An example of circular dependency
A module called main.js requires a.js and b.js. In turn, a.js requires b.js. But b.js relies on a.js as well! It's obvious that we have a circular dependency here as module a.js requires module b.js and module b.js requires module a.js. Let's have a look at the code of these two modules:
- Module
a.js:exports.loaded = false const b = require('./b') module.exports = { b, loaded: true // overrides the previous export } - Module
b.js:exports.loaded = false const a = require('./a') module.exports = { a, loaded: true }
Now, let's see how these modules are required by main.js:
const a = require('./a')
const b = require('./b')
console.log('a ->', JSON.stringify(a, null, 2))
console.log('b ->', JSON.stringify(b, null, 2))
If we run main.js, we will see the following output:
a -> {
"b": {
"a": {
"loaded": false
},
"loaded": true
},
"loaded": true
}
b -> {
"a": {
"loaded": false
},
"loaded": true
}
This result reveals the caveats of circular dependencies with CommonJS, that is, different parts of our application will have a different view of what is exported by module a.js and module b.js, depending on the order in which those dependencies are loaded. While both the modules are completely initialized as soon as they are required from the module main.js, the a.js module will be incomplete when it is loaded from b.js. In particular, its state will be the one that it reached the moment b.js was required.
In order to understand in more detail what happens behind the scenes, let's analyze step by step how the different modules are interpreted and how their local scope changes along the way:
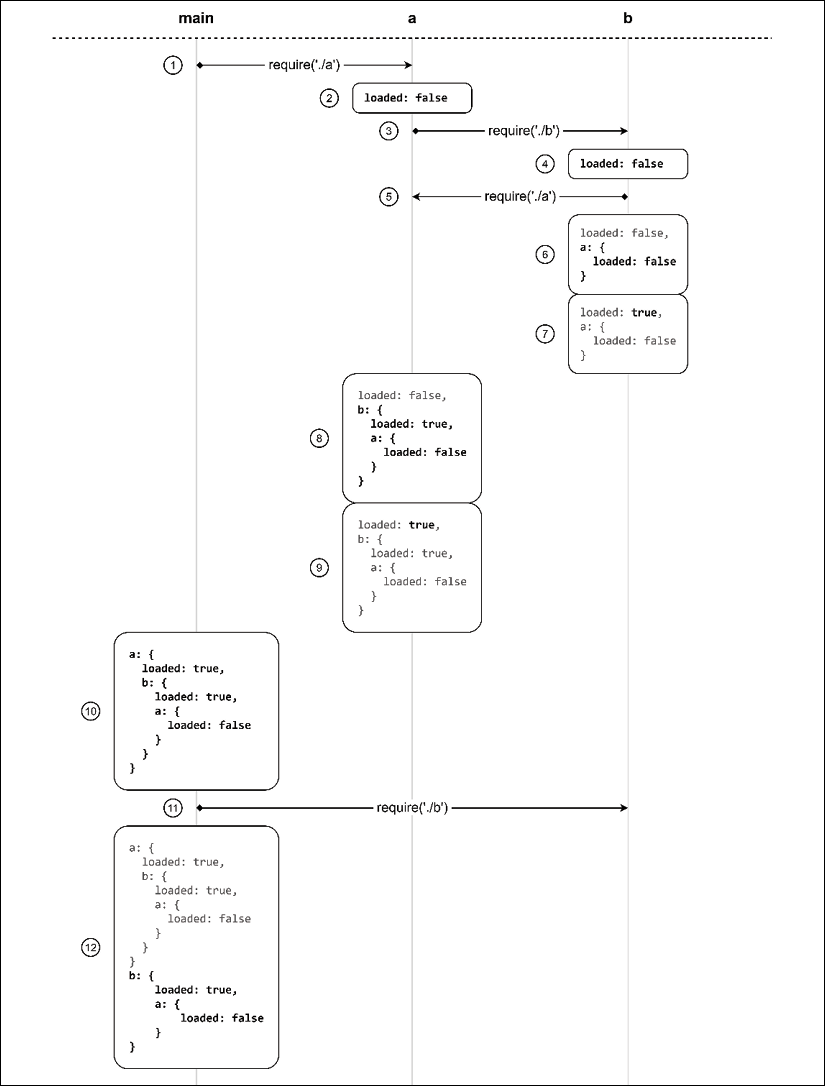
Figure 2.2: A visual representation of how a dependency loop is managed in Node.js
The steps are as follows:
- The processing starts in
main.js, which immediately requiresa.js - The first thing that module
a.jsdoes is set an exported value calledloadedtofalse - At this point, module
a.jsrequires moduleb.js - Like
a.js, the first thing that moduleb.jsdoes is set an exported value calledloadedtofalse - Now,
b.jsrequiresa.js(cycle) - Since
a.jshas already been traversed, its currently exported value is immediately copied into the scope of moduleb.js - Module
b.jsfinally changes theloadedvalue totrue - Now that
b.jshas been fully executed, the control returns toa.js,which now holds a copy of the current state of moduleb.jsin its own scope - The last step of module
a.jsis to set itsloadedvalue totrue - Module
a.jsis now completely executed and the control returns tomain.js, which now has a copy of the current state of modulea.jsin its internal scope main.jsrequiresb.js, which is immediately loaded from cache- The current state of module
b.jsis copied into the scope of modulemain.jswhere we can finally see the complete picture of what the state of every module is
As we said, the issue here is that module b.js has a partial view of module a.js, and this partial view gets propagated over when b.js is required in main.js. This behavior should spark an intuition which can be confirmed if we swap the order in which the two modules are required in main.js. If you actually try this, you will see that this time it will be the a.js module that will receive an incomplete version of b.js.
We understand now that this can become quite a fuzzy business if we lose control of which module is loaded first, which can happen quite easily if the project is big enough.
Later in this chapter, we will see how ESM can deal with circular dependencies in a more effective way. Meanwhile, if you are using CommonJS, be very careful about this behavior and the way it can affect your application.
In the next section, we will discuss some patterns to define modules in Node.js.
















