























































When designing an algorithm, it is important to find different ways to specify its details. The ability to capture both its logic and architecture is required. Generally, just like building a home, it is important to specify the structure of an algorithm before actually implementing it. For more complex distributed algorithms, pre-planning the way their logic will be distributed across the cluster at running time is important for the iterative efficient design process. Through pseudocode and execution plans, both these needs are fulfilled and are discussed in the next section.
Specifying the logic of an algorithm
Understanding pseudocode
The simplest way to specify the logic for an algorithm is to write the higher-level description of an algorithm in a semi-structured way, called pseudocode. Before writing the logic in pseudocode, it is helpful to first describe its main flow by writing the main steps in plain English. Then, this English description is converted into pseudocode, which is a structured way of writing this English description that closely represents the logic and flow for the algorithm. Well-written algorithm pseudocode should describe the high-level steps of the algorithm in reasonable detail, even if the detailed code is not relevant to the main flow and structure of the algorithm. The following figure shows the flow of steps:
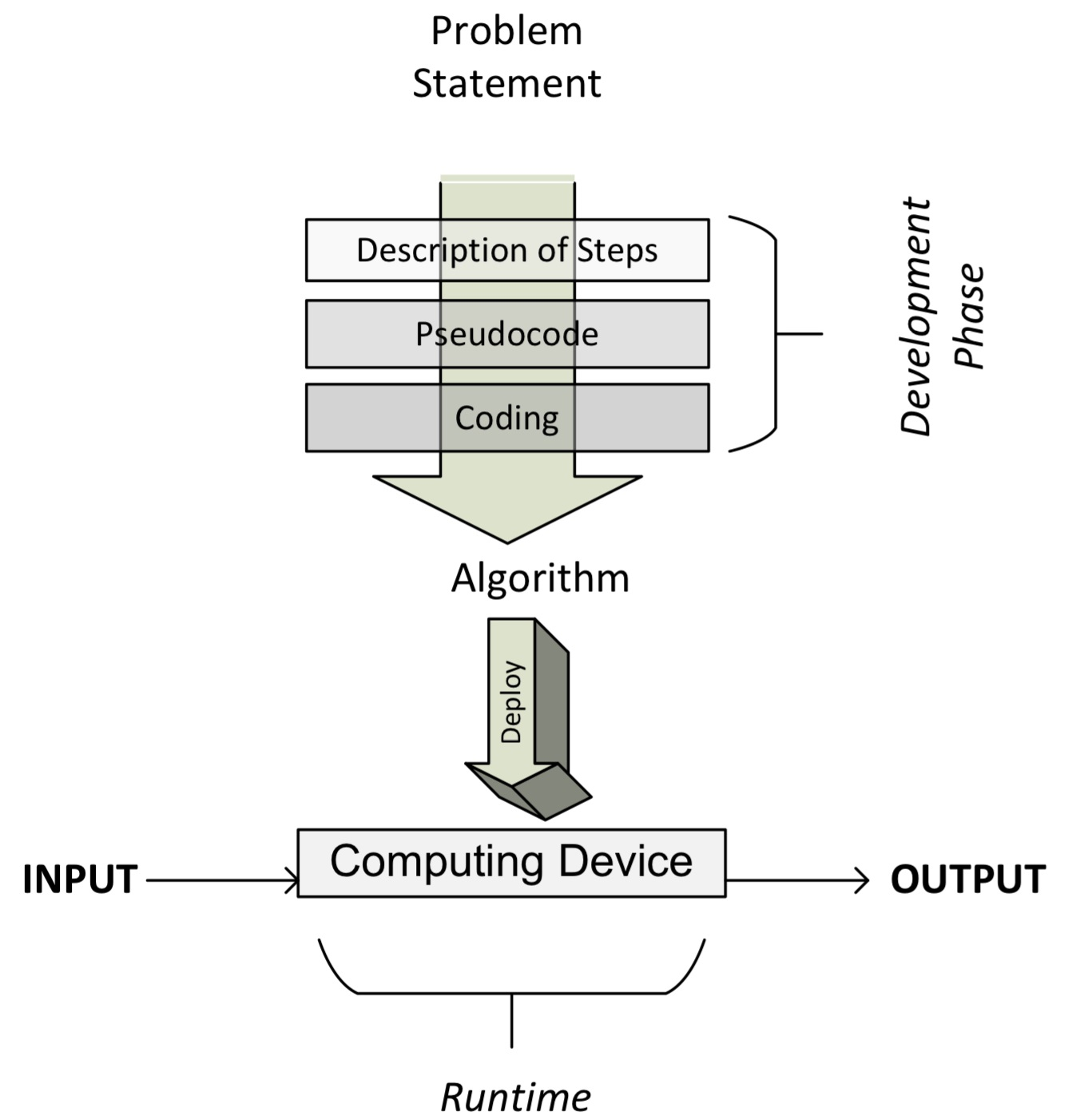
Note that once the pseudocode is written (as we will see in the next section), we are ready to code the algorithm using the programming language of our choice.
A practical example of pseudocode
Figure 1.3 shows the pseudocode of a resource allocation algorithm called SRPMP. In cluster computing, there are many situations where there are parallel tasks that need to be run on a set of available resources, collectively called a resource pool. This algorithm assigns tasks to a resource and creates a mapping set, called Ω. Note that the presented pseudocode captures the logic and flow of the algorithm, which is further explained in the following section:
1: BEGIN Mapping_Phase
2: Ω = { }
3: k = 1
4: FOREACH Ti∈T
5: ωi = RA(Δk,Ti)
6: add {ωi,Ti} to Ω
7: state_changeTi [STATE 0: Idle/Unmapped] → [STATE 1: Idle/Mapped]
8: k=k+1
9: IF (k>q)
10: k=1
11: ENDIF
12: END FOREACH
13: END Mapping_Phase
Let's parse this algorithm line by line:
We start the mapping by executing the algorithm. The Ω mapping set is empty.
The first partition is selected as the resource pool for the T1 task (see line 3 of the preceding code). Television Rating Point (TRPS) iteratively calls the Rheumatoid Arthritis (RA) algorithm for each Ti task with one of the partitions chosen as the resource pool.
The RA algorithm returns the set of resources chosen for the Ti task, represented by ωi (see line 5 of the preceding code).
Ti and ωi are added to the mapping set (see line 6 of the preceding code).
The state of Ti is changed from STATE 0:Idle/Mapping to STATE 1:Idle/Mapped (see line 7 of the preceding code).
Note that for the first iteration, k=1 and the first partition is selected. For each subsequent iteration, the value of k is increased until k>q.
If k becomes greater than q, it is reset to 1 again (see lines 9 and 10 of the preceding code).
This process is repeated until a mapping between all tasks and the set of resources they will use is determined and stored in a mapping set called Ω.
Once each of the tasks is mapped to a set of the resources in the mapping phase, it is executed.
Using snippets
With the popularity of simple but powerful coding language such as Python, an alternative approach is becoming popular, which is to represent the logic of the algorithm directly in the programming language in a somewhat simplified version. Like pseudocode, this selected code captures the important logic and structure of the proposed algorithm, avoiding detailed code. This selected code is sometimes called a snippet. In this book, snippets are used instead of pseudocode wherever possible as they save one additional step. For example, let's look at a simple snippet that is about a Python function that can be used to swap two variables:
define swap(x, y)
buffer = x
x = y
y = buffer
Note that snippets cannot always replace pseudocode. In pseudocode, sometimes we abstract many lines of code as one line of pseudocode, expressing the logic of the algorithm without becoming distracted by unnecessary coding details.
Creating an execution plan
Pseudocode and snippets are not always enough to specify all the logic related to more complex distributed algorithms. For example, distributed algorithms usually need to be divided into different coding phases at runtime that have a precedence order. The right strategy to divide the larger problem into an optimal number of phases with the right precedence constraints is crucial for the efficient execution of an algorithm.
We need to find a way to represent this strategy as well to completely represent the logic and structure of an algorithm. An execution plan is one of the ways of detailing how the algorithm will be subdivided into a bunch of tasks. A task can be mappers or reducers that can be grouped together in blocks called stages. The following diagram shows an execution plan that is generated by an Apache Spark runtime before executing an algorithm. It details the runtime tasks that the job created for executing our algorithm will be divided into:
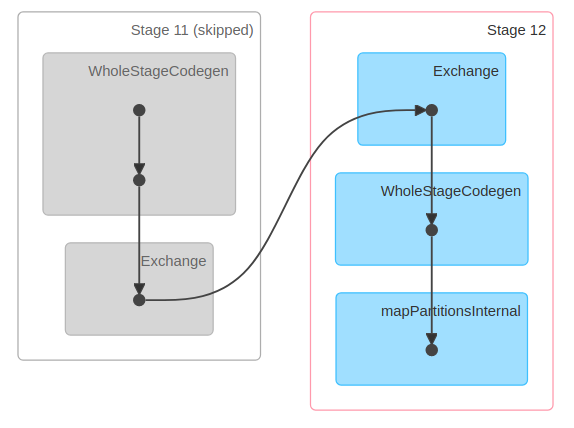
Note that the preceding diagram has five tasks that have been divided into two different stages: Stage 11 and Stage 12.






















